Part Of: Chess sequence
Followup To: The Chess SuperTree
Content Summary: 1400 words, 14 min read
Dual Process Cognition: Working Memory
Chess engines operate by generating a decision tree, pruning irrelevant branches, assigning scores to the leaves, and consulting the minimax oracle for an optimal decision.
But when we switch from silicon to grey matter, we notice that the human mind is structured differently. We can be meaningfully divided into two selves: a fast, autonomic, associative mind and a slow, serial, conscious mind. What’s worse, the content of our “more rational” self is small – System II is grounded in working memory, which can hold 7 +/- 2 chunks of information.
Working memory span is highly correlated with IQ. Keith Stanovich, in his Rationality and the Reflective Mind, claims that intelligence can be understood as a cognitive decoupling; that is, highly intelligent people are able to evaluate more hypothetical scenarios faster, and keep those explorations firewalled from one’s modeling of the current reality.
While playing chess, the ability to construct a decision tree is a conscious, effortful task. In other words, decision trees are instantiated within your System II working memory during game play.
Dual Process Cognition: Somatic Markers
If decision trees are consciously maintained, what is the basis of score evaluation functions? Recall that machine learning accomplishes this by virtue of training feature vectors and weight vectors. Suppose these vectors can contain two millions numbers each. Every time the engine is asked to evaluate a position, it will compute a dot product: scan over the vectors, and for each value record its product.
With decision trees, I can remember keeping various alternatives in my head. Not so with producing decision scores. Nothing in my gameplay experience feels like I am computing two million numbers with every move. This suggests that score evaluation functions happen within the subconscious, massively parallel System I.
But what does evaluating a position feel like? Two phenomenological observations are in order:
- Playing chess is a highly intuitive, emotional affair. Positions in which we have a strong advantage feel good, moves that lead us into checkmate feel scary, and the objectively optimal move tends to produce the most positive feeling. In other words, emotion is the mediator of chess skill. This is an expression of the somatic marker hypothesis.
- Explaining chess moves tends to naturally flow in a non-mathematical language, where reasons are considered the final authority over decision making. I am better able to remember “White is better because he has an attack” instead of “White is 20% more likely to win the game”.
We’ll return to these suggestive observations in a little bit.
Is Scoring Cardinal Or Ordinal?
In economic theory, all decisions are mediated by a psychological entity called utility. (I introduce this concept in this post). Neuroeconomics is an attempted integration between economics, psychology, and neuroscience; it tries to get at how the brain produces decisions. Within this field, there is a live debate whether the brain represents utility cardinally (e.g., 3.2982) or ordinally (e.g., A > B and B > C).
Consider again how chess engines compute on the decision tree. The minimax algorithm pushes leaf nodes up the tree, merging results via the min() or max() operation. Whereas engines perform these operation against cardinal score nodes (e.g., in fractions of a pawn called centipawns), this need not be the case. Taking the max(A, B) does not require knowing the precise value of A and B. It is sufficient to know that A > B. In other words, minimax can also work against an ordinal scoring scheme.
The implications of an ordinal scoring scheme becomes more apparent if you view the minimax algorithm from a comparison perspective. In the following image, white spheres represent White decisions (maximization) and gray spheres represent Black decisions (minimization).
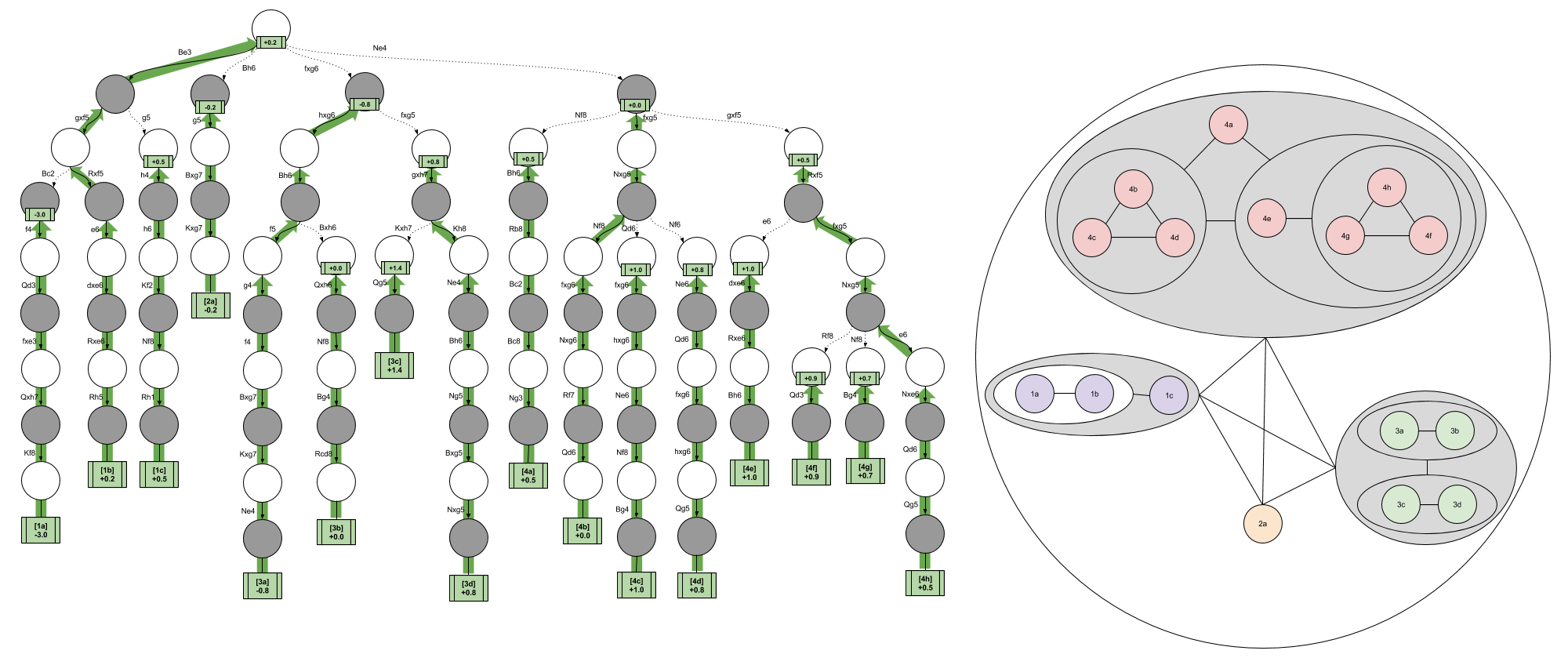
It is possible to think of image on the left as a “side view” of the minimax algorithm. With this geometric interpretation, the right image becomes a “bottom view” of the exact same algorithm. Pause a moment here until you convince yourself of this.
Consider the nested spheres containing the purple nodes. These represent three leftmost threads in the decision tree: { { 1a vs 1b } vs 1c }. Do we need to know the value of { 1a vs 1c } or { 1b vs 1c }? If we knew both facts, we could surely have enough information to implement minimax. But this “easy solution” would require a total ordering, which is prohibitively expensive. We instead need to resolve the { 1a vs 1b } fact, after which we can compare the result to 1c.
So the brain could choose to evaluate positions ordinally or cardinally. Which technology does it employ in practice?
I don’t know, but I can recommend a test to divine the correct answer. The order in which cardinal scores are generated is unconstrained: a chess player with a cardinal function can evaluate any position at any time. In contrast, the order in which ordinal scores are generated is highly constrained (if we assume a non-total ordering). A brain that implement ordinal evaluations cannot physically evaluate the 1c thread until it has evaluated { 1a vs 1b }. Thus, if we were to study the speech and subjective experiences of a multitude of chess players, we could hope to learn whether their creative abilities are constrained in this way.
The State Comparator & Distinguishing Features
Consider again the feature-weight dot product model of score functions. If I were to evaluate two very similar functions, the dot product would necessarily be very similar: only a few dozen features may meaningfully diverge in their contribution to the final output. Call these uniquely divergent features the distinguishing features.
A computer engine will compute similar dot products in their entirety (with the exception of position that are exactly the same, see transposition tables); it strikes me as very likely that the brain (a metabolic conservative) typically only retains a representation of the distinguishing features. In other words, the “reason-based natural language” that humans produce when we evaluating gamelines draws from a cognitive mechanism that recognizes that features close in distance to the KingSafety category tend to be the relevant ones.
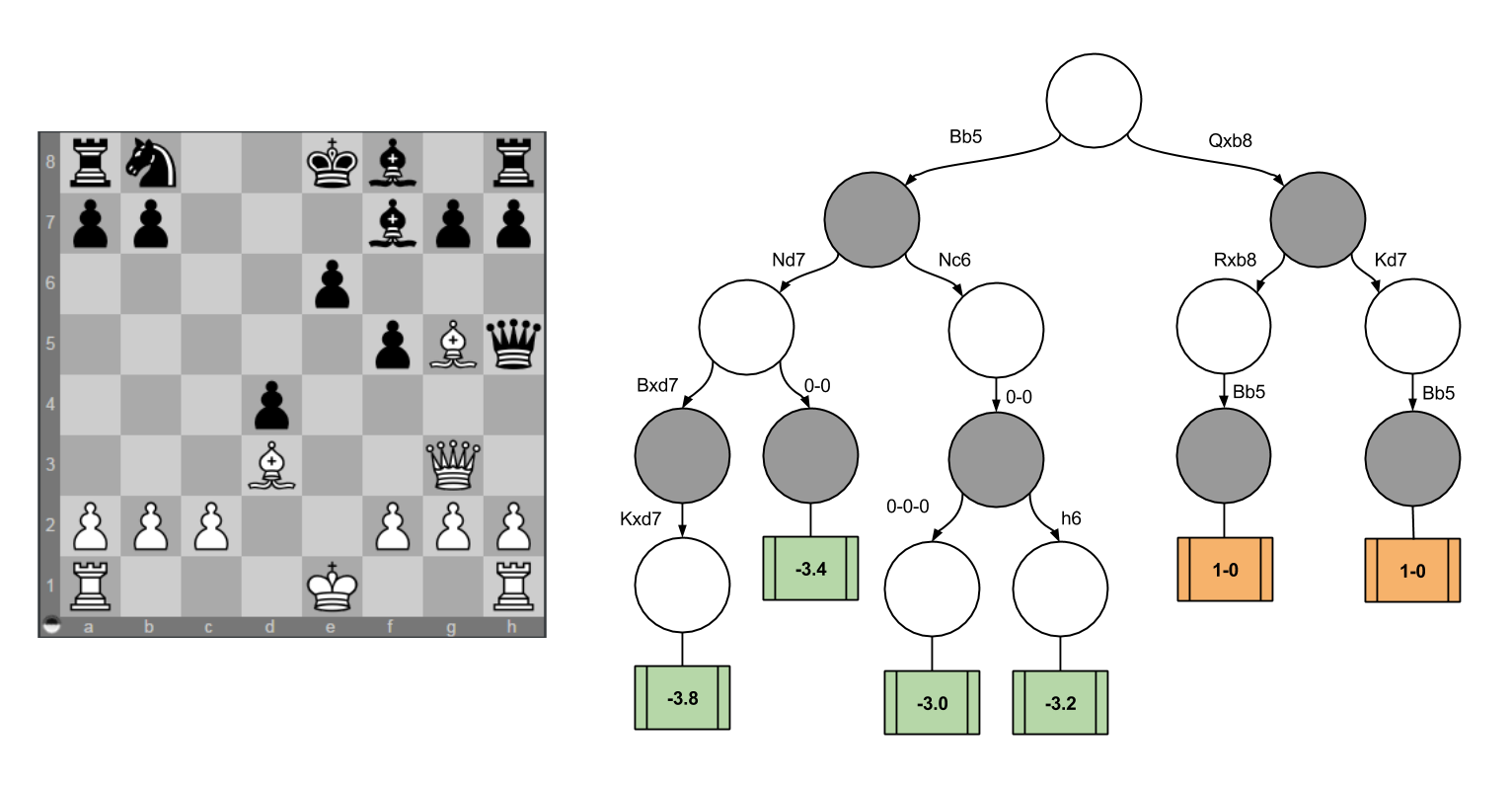
In the discussion of Decision Trees In Chess, I discuss four different moves. The insightful reader may have noticed that I moved my Bishop to the h6 square in three separate situations. These considerations happen at three locations in the decision tree:
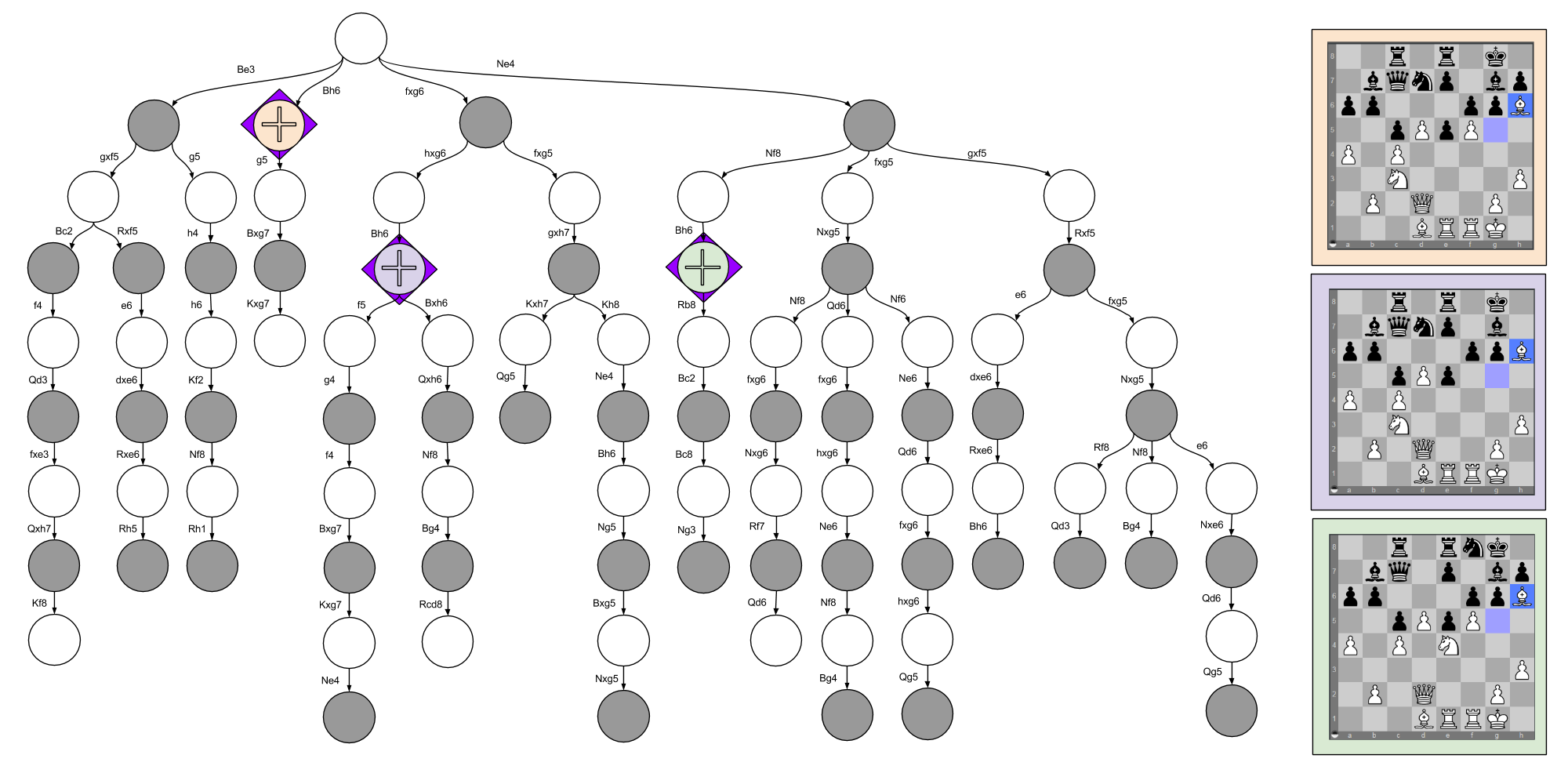
While a chess engine may score each position repetitively, each score computation will be very similar. Only two features really stand out:
- The purple node is different from the orange node because the former has traded off two pawns.
- The green node is different from the orange node because the former has made two Knight moves to attack & defend the Kingside.
If you consult the minimax graphic above, you’ll see that my preference ordering is { Green > Orange > Purple }. I would explain this in language by appealing to the relevant differences (e.g., “the pawn trade frees his pawns to control the center”). To me, this is evidence for a state comparison tool that is able to zoom in on distinguishing features.
The Move Generator & Representative Lines
Another distinction between human and computer decisions in chess seems to lie in how the decision tree is approached. Engines like Stockfish typically have a getLegalMoves() function that fleshes out the entire branching structure, and then (extremely) sophisticated pruning techniques are used to make truly deep evaluations possible of the interesting lines. It is possible that nonconscious Type I processes in humans do something comparable, but this strikes me as unlikely. Rather than an eliminative approach to the SuperTree, it seems to me that humans construct representations gradually.
Specifically, I suspect that humans have a Type I statistical mechanism that generates a few plausible moves for a given position. Consider the following subset of a decision tree I examined previously:
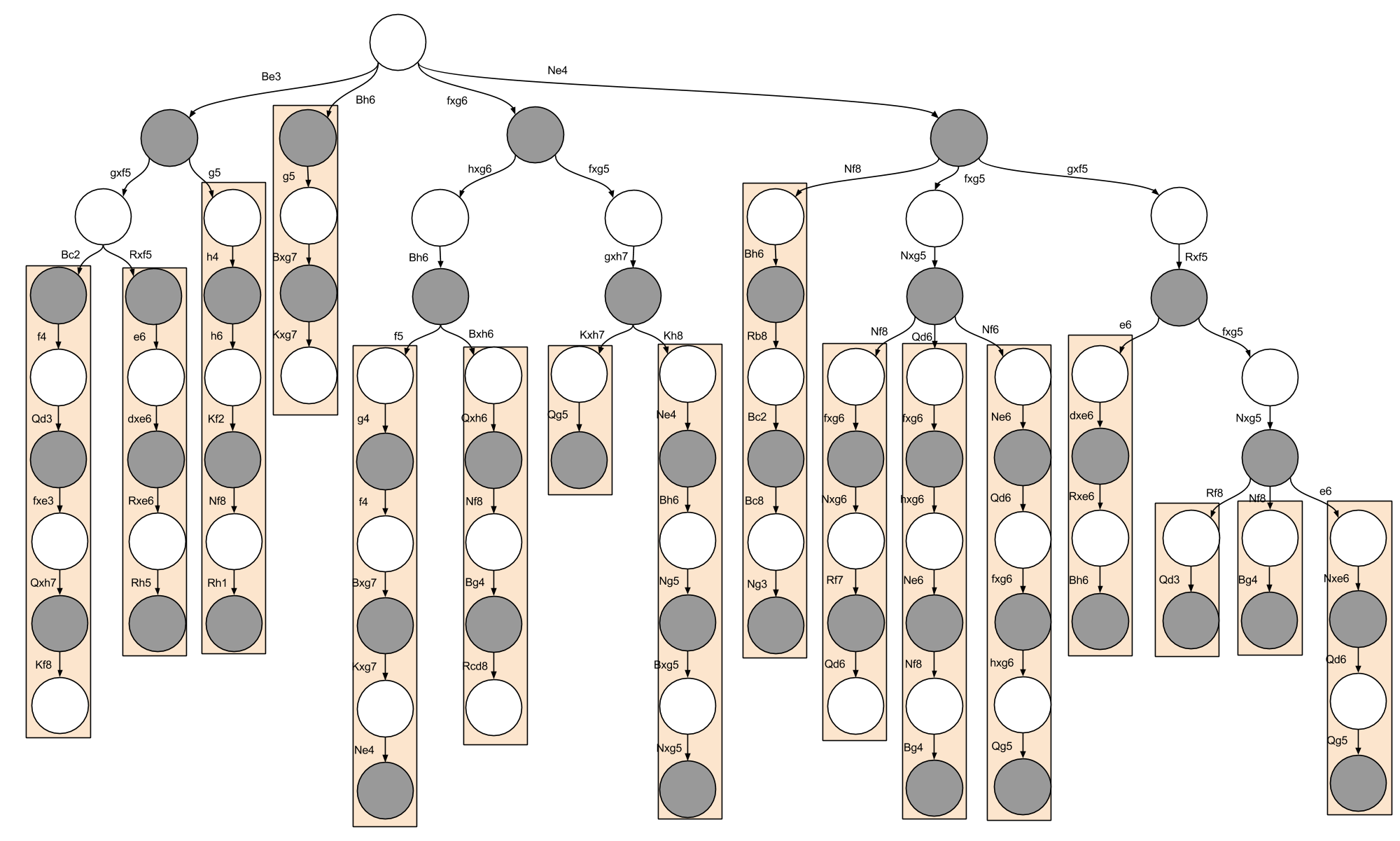
Each orange rectangle represents moments when I simply stopped considering alternatives; these representative lines are depth-oriented in nature. I suspect the ubiquity of these representative lines can be explained by appealing to serial application of the MoveGenerator, and the sheer difficulty humans have in maintaining a complex tree in working memory.
Takeaways
- The brain represents decision trees largely in working memory (a conscious System II process)
- Massively parallel System I processes are how the brain computes position scores, which are encoded in emotion.
- While computers represent scores as numbers, it is possible the brain represents scores as preferences (an ordinal system).
- The brain, being allergic to duplicate computations, contains a State Comparator which isolates distinguishing features within similar positions.
- Rather than pruning a complete decision tree like computers, the brain an intuitive, System I, Move Generator to construct a plausible sub-tree.