Part Of: [Deserialized Cognition] sequence
Introduction
Nietzsche once said:
My time has not yet come; some men are born posthumously.
Well, this post is “born posthumously” too: its purpose will become apparent by its successor. Today, we will be taking a rather brisk stroll through computer science, to introduce serialization. We will be guided by the following concept graph:

On a personal note, I’m trying to make these posts shorter, based on feedback I’ve received recently. 🙂
Let’s begin.
Object-Oriented Programming (OOP)
In the long long ago, most software was cleanly divided between data structures and the code that manipulated them. Nowadays, software tends to bundle these two computational elements into smaller packages called objects. This new practice is typically labelled object-oriented programming (OOP).
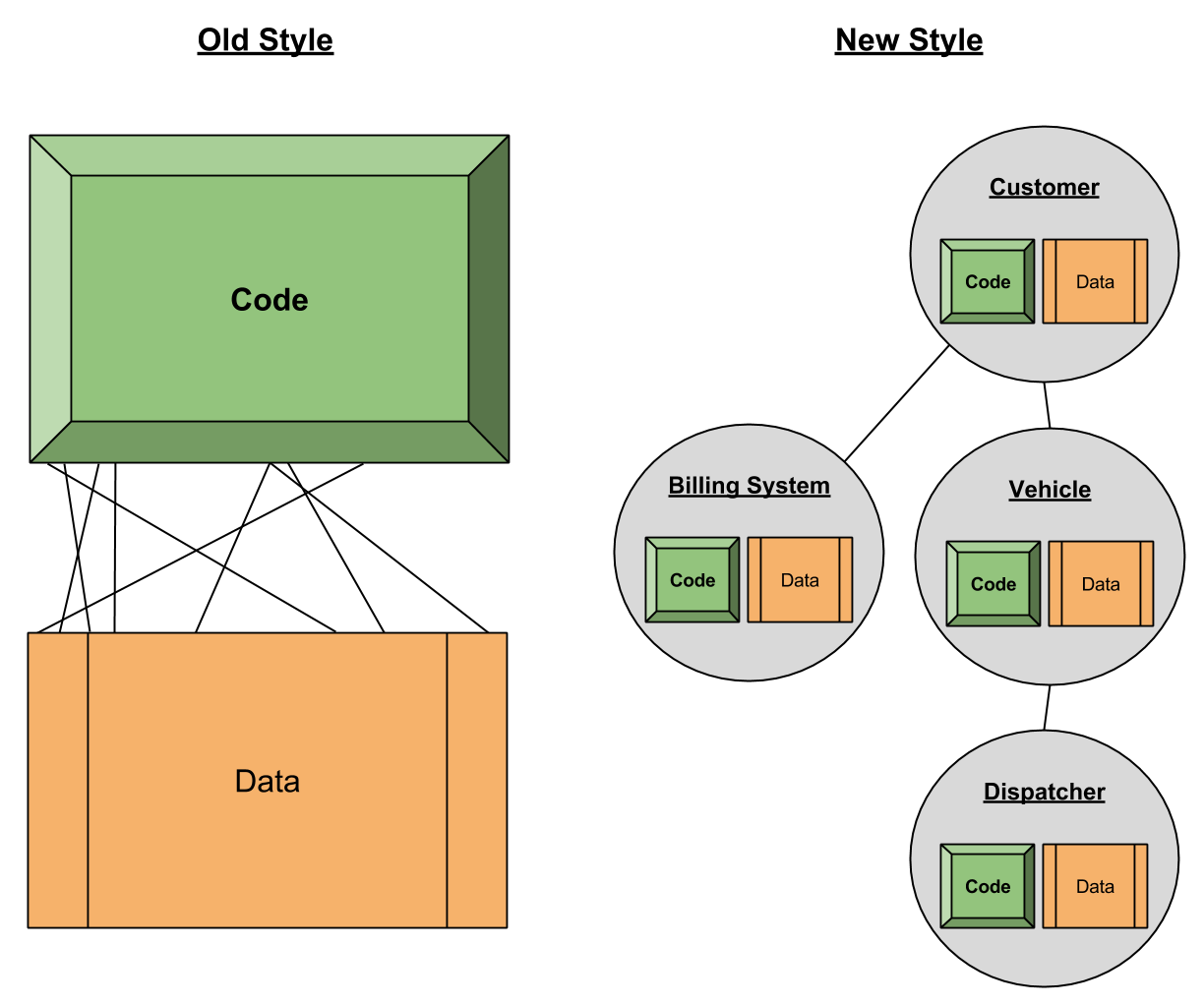
The new style, OOP, has three basic principles:
- Encapsulation. Functions and data that pertain to the same logical unit should be kept together.
- Inheritance. Objects may be arranged hierarchically; they may inherit information in more basic objects.
- Polymorphism. The same inter-object interface can be satisfied by more than one object.
Of these three principles, the first is most paradigmatic: programming is now conceived as a conversation between multiple actors. The other two simply elaborate the rules of this new playground.
None of this is particularly novel to software engineers. In fact, the ability to conjure up conversational ecosystems – e.g., the taxi company OOP system above – is a skill expected in practically all software engineering interviews.
CogSci Connection: Some argue that conversational ecosystems is not an arbitrary invention, but necessary to mitigate complexity.
State Transitions
Definition: Let state represent a complete description of the current situation. If I were to give you full knowledge of the state of an object, you could (in principle) reconstitute it.
During a program’s lifecycle, the state of an object may change over time. Suppose you are submitting data to the taxi software from the above illustration. When you give your address to the billing system, that object updates its state. Object state transitions, then, look something like this:
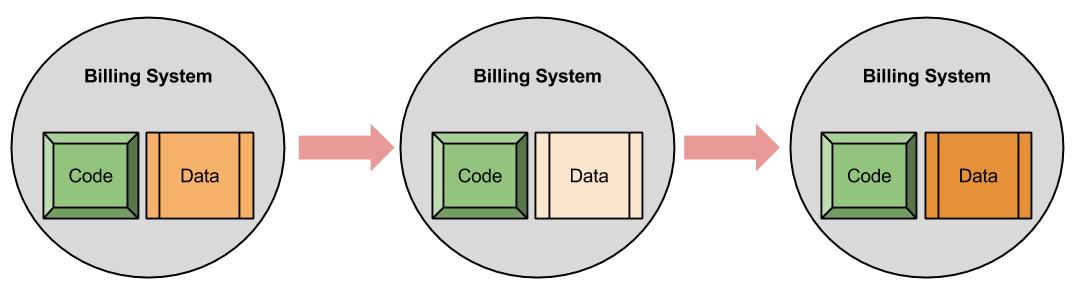
Memory Hierarchy
Ultimately, of course, both code and data are 1s and 0s. And information has to be physically embedded somewhere. You can do this in switches, gears, vacuum tubes, DNA, and entangled quantum particles: there is nothing sacred about the medium. Computer engineers tend to favor magnetic disks and silicon chips, for economic reasons. Now, regardless of the medium, what properties do we want out of an information vehicle? Here’s a tentative list:
- Error resistant.
- Inexpensive.
- Non-volatile (preserve state even if power is lost).
- Fast.
Engineers, never with a deficit of creativity, have invented dozens of such information vehicle technologies. Let’s evaluate four separate candidates, courtesy of Tableau. 🙂

Are any of these technologies dominant (superior to all other candidates, in every dimension)?
No. We are forced to make tradeoffs. Which technology do you choose? Or, to put it more realistically, what would you predict computer manufacturers have built, guided by our collective preferences?
The universe called. It says my question is misleading. Economic pressures have caused manufacturers to choose… several different vehicles. And no, I don’t mean embedding different programs into different mediums. Rather, we embed our programs into multiple vehicles at the same time. The memory hierarchy is a case study in redundancy.
CogSci Connection: I cannot answer why economics has gravitated towards this highly counter-intuitive solution? But, it is important to realize that the brain does the same thing! It houses a hierarchy of trace memory, working memory, and long-term memory. Why is duplication required here, as well? So many unanswered questions…
Serialization
It is time to combine OOP and the memory hierarchy. We now imagine multiple programs, duplicated across several vehicles, living in your computer:
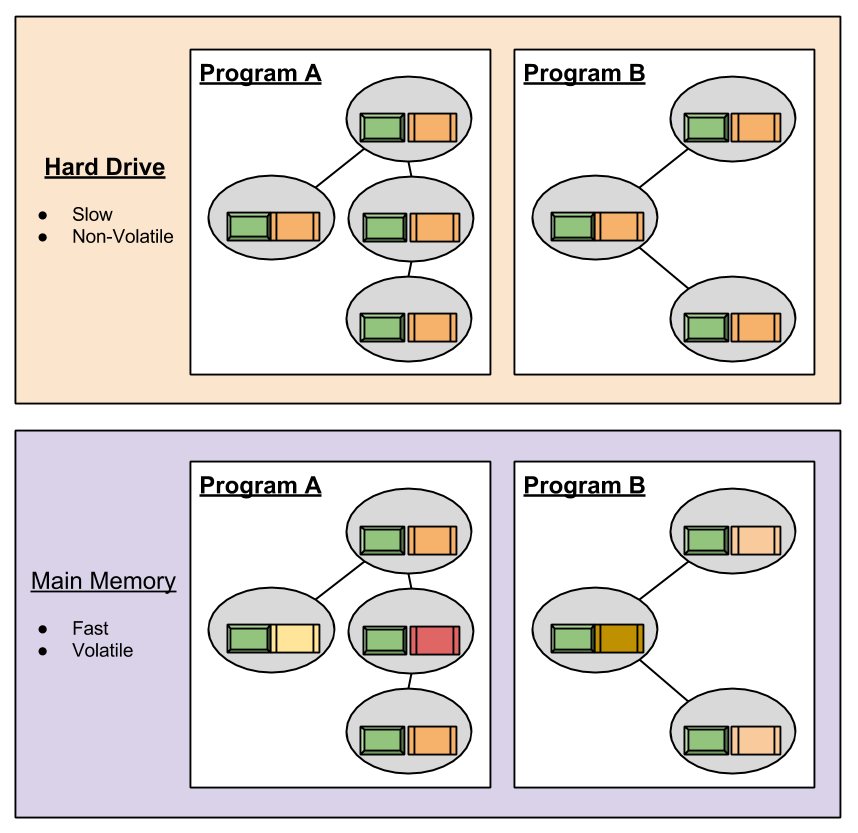
In the above illustration, we have two programs being duplicated in two different information vehicles (main memory and hard drive). The main memory is faster, so state transitions (changes made by the user, etc) land there first. This is represented by the mutating color within the objects of main memory. But what happens if someone trips on your power cord, unplugging your CPU before main memory can be copied to the hard drive? All changes to the objects are lost! How do we fix this?
One solution is serialization (known in some circles as marshalling). If we simply write down the entire state of an object, we would be able to re-create it later. Many serialization formats (competing techniques for how best to record state) exist. Here is an example in the JavaScript Object Notation (.json) format:
{“menu”: {
“id”: “file”,
“value”: “File”,
“popup”: {
“menuitem”: [
{“value”: “New”, “onclick”: “CreateNewDoc()”},
{“value”: “Open”, “onclick”: “OpenDoc()”},
{“value”: “Close”, “onclick”: “CloseDoc()”}
]
}
}}
Applications
So far, we’ve motivated serialization by appealing to a computer losing power. Why else would we use this technique?
Let’s return to our taxi software example. If the software becomes very popular, perhaps too many people will want to use it at the same time. In such a scenario, it is typical for engineers to load balance: distribute the same software on multiple different CPUs. How could you copy the same objects across different computers? By serialization!
CogSci Connection: Let’s pretend for a moment that computers are people, and objects are concepts. … Notice anything similar to interpersonal communication? 🙂
Conclusion
In this post, we’ve been introduced to object-oriented programming, and how it changed software to becoming more like a conversation between agents. We also learned the surprising fact about memory: that duplicate hierarchies are economically superior to single solutions. Finally, we connected these ideas in our model of serialization: how the entire state of an object can be transcribed to enable future “resurrections”.
Along the way, we noted three parallels between computer science and psychology:
- It is possible that object-oriented programming was first discovered by natural selection, as it invented nervous systems.
- For mysterious reasons, your brain also implements a duplication-heavy memory hierarchy.
- Inter-process serialization closely resembles inter-personal communication.