Part Of: [Deserialized Cognition] sequence
Followup To: [Why Serialization?]
You’ve heard the phrase “pre-conceived notion” before. Ever wonder what it means? Let’s figure it out!
Cognitive Style: Conceptiation
Your mind is capable of generating concepts. Let us name this active process conceptiation.
How does this process work in practice? There are only two ways concepts are created: from oneself (inference conceptiation), or from others (social conceptiation):
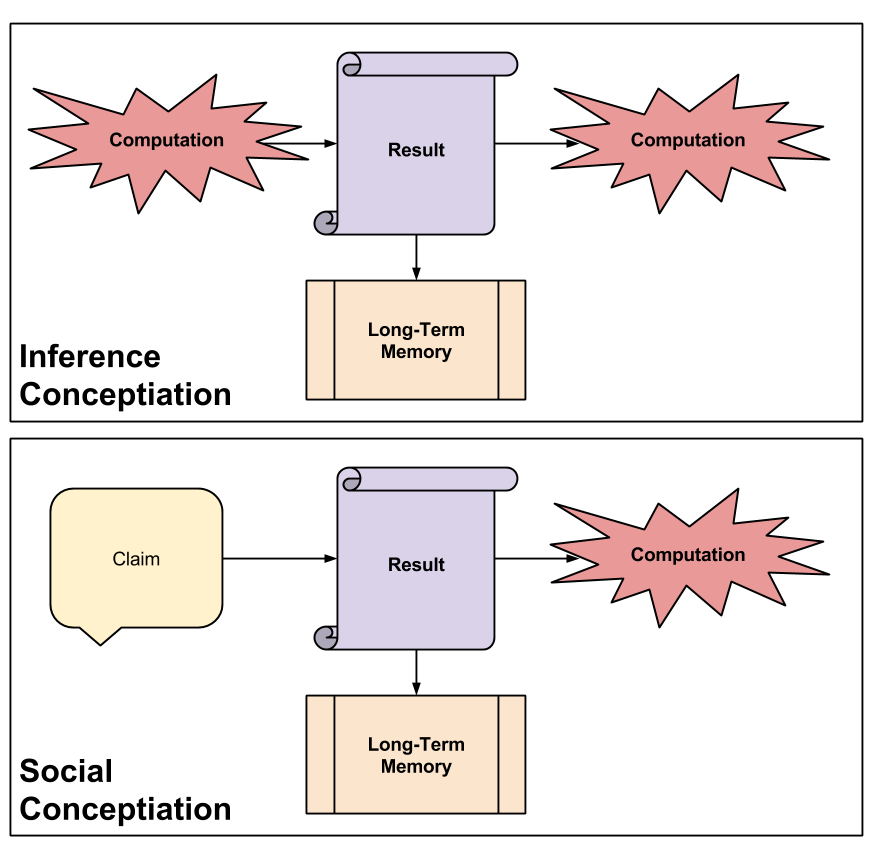
Inference Conceptiation attempts to get at self-motivated, non-social cognition. You process information, you form a conclusion (a result), you save this result to memory, and then you pass it along to other cognitive process. Examples:
- A scientist trying to make progress in string theory
- An artist teaching herself to speak Spanish
Social Conceptiation summarizes the thought process of someone immersed in a more social setting. Examples:
- An engineer picking up an proverb (e.g., “no analogy is perfect”) from Facebook, without thinking about it much.
- A socialite half-listening to some guy at a dinner party describing nuanced work tasks.
During both types of conceptiation, concepts are saved to your long-term memory. Call this serialization.
Cognitive Style: Deserialization
You are a lazy thinker. Don’t take it personally, though – so is everyone else. How can we explain our inner cognitive miser? It turns out that there are at least two biological reasons for this failing:
- Brains are slow because they rely on chemical synapses; they run at 100Hz (vs the 2 billion Hz of computers)
- Brains are metabolically expensive, burning 800% more energy than other organs (20% of total organismic load)
Serialization techniques (discussed previously) allow our brains to be lazy. Not all concepts need to be created from scratch; if, at some point in the past, you have acquired the requisite mindware, you can always resurrect it from long-term memory, in virtue of your built-in deserialization mechanism:

Two Inputs
As mentioned, deserialization (loading) only works if the requisite concepts have been serialized (saved) at some point in the past. Since serialization comes in two flavors, we can now refer to two different kinds of deserialization:

Call the former inference deserialization, and the latter social deserialization.
Application: “I Love You”
Imagine you were raised to believe in the importance of regular expressions of affection to your significant other (SO). So, you say “I love you” to him/her every day. At first, you are eager to tell them the reasons behind your feelings, but after a while, novelty becomes increasingly effortful. Eventually, you settle into a simple “I love you” before falling asleep. Fast forward two years, and your SO says “I don’t feel like you are being affectionate enough”. How can we explain this?
We are now equipped to describe the “I love you” pattern as an instance of deserialized cognition, no? This form of cognition (more specifically, a behavioral pattern) was established previously, and no longer requires active conceptiation to perform. Why should your SO wish for you to employ active processing, especially if such processing yields content very similar to your habituated behavior?
Why would your SO wish you reject serialized cognition? Here’s one path an explanation may take: such an override goes against the instinct of the cognitive miser. Costly signaling is a staple concept in ethology: effort filters between those who truly hold the recipient in high regard and those who only wish to appear that way.
Speaking more generally, it seems to me that our itch for originality come from precisely this will to demonstrate rejection of deserialized cognition.
Takeaways
In this post, we explored how the brain uses concepts via two distinct mechanisms:
- In conceptiation, the brain actively constructs & uses novel concepts.
- In deserialization, the brain simply reuses pre-existing concepts.
The brain also employs two different ways to create concepts:
- Some concepts are constructed by one’s own mind.
- Concepts constructed in a social setting are constructed externally, but are (optionally) evaluated by the self.
Putting these together, we are now equipped to refer to four different types of cognition.

This new vocabulary opens many doors to explanation, including the question “why do people value originality?”
Credit: Some of the ideas of this post come from previous speculations about cached thoughts. However, compared to deserialization, caching has a weaker analogy strength: concept reuse has precious little to do with enforcing consistency within a memory hierarchy.
Until next time!