
Part Of: Bayesianism series
Content Summary: 2300 words, 23 min read
Epistemic Status: several of these ideas are not distillations, but rather products of my own mind. Recommend a grain of salt.
The Biology of Uncertainty
In the reinforcement learning literature, there exists a bedrock distinction of exploration vs exploitation. A rat can either search for a new food source, or continue mining calories from his current stash. There is risk in exploration (what if you don’t find anything better?), and often diminishing returns (if you’re confined to 2 miles from your sleeping grounds, there’s only so much territory that needs to be explored). But without exploration, you hazard large opportunity costs and your food supply becomes quite fragile.
Exploitation can be conducted unconsciously. You simply need nonconscious modules to track the rate of returns provided by your food site. These devices will alarm if the food source degrades, but otherwise don’t bother you much. In contrast, exploration engages an enormous amount of cognitive resources: your cognitive map (neural GPS), action plans, world-beliefs, causal inference. Exploration is about learning, and as such requires consciousness. Exploration is paying attention to the details.
Exploration will tend to produce probability matching behaviors: your actions are in proportion to your action value estimates. Exploitation tends to produce maximizing behaviors: you always choose the action estimated to produce the most value.
Statistics and Controversy
Everyone agrees that probability theory is a profoundly useful tool for understanding uncertainty. The problem is, statisticians cannot agree on what probability means. Frequentists insist on interpreting probability as relative frequency; Bayesians interpret probability as degree of confidence. Frequentists use random variables to describe data; Bayesians are comfortable also using them to describe model parameters.
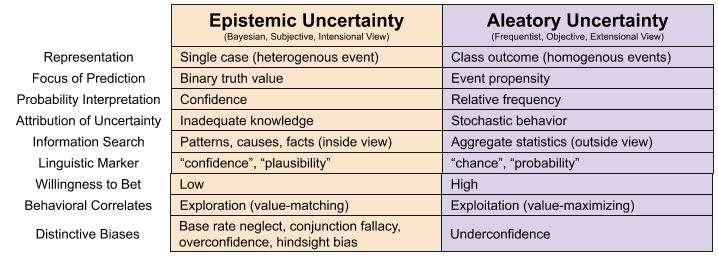
We can reformulate the debate as between two conceptions of uncertainty. Epistemic uncertainty is the subjective Bayesian interpretation, the kind of uncertainty that can be reduced by learning. Aleatory uncertainty is the objective Frequentist stuff, the kind of uncertainty you accept and work around.
Philosophical disagreements often have interesting implications. For example, you might approach deontological (rule-based) and consequential (outcome-based) ethical theories as a winner-take-all philosophical slugfest. But Joshua Greene has shown that both camps express unique circuitry in the human mind: every human being experiencing both ethical intuitions during moral dilemmas (but at different intensities and with different activation profiles.
The sociological fact of persistent philosophical disagreement sometimes reveals conflicting intuitions within human nature itself. Controversy reification is a thing. Is it possible this controversy within philosophy of statistics suggests a tension buried in human nature?
I submit these rivaling definitions of uncertainty are grounded in the exploration and exploitation repertoires. Exploratory behavior treats unpredictability as ignorance to be overcome, exploitation behavior treats unpredictability as noise to be accomodated. All vertebrates possess two ways of approaching uncertainty. Human philosophers and statisticians are rationalizing and formalizing truly ancient intuitions.
Cleaving Nature At Its Joints
Most disagreements are trivial. Nothing biologically significant hinges on the fact that some people prefer the color blue, and others green. Do frequentist/Bayesian intuitions resemble blue/green, or deontological/consequential? How would you tell?
Blue-preferring statements don’t seem systematically different from green-preferring statements. But intuitions about epistemic vs aleatory uncertainty do systematically differ. The psychological data presented in Brun et al (2011) is very strong on this point.
Statistical concepts are often introduced with ridiculously homogenous events, like a coin flip. It is essentially impossible for a neurotypical human to perfectly predict the outcome of a coin flip (which are determined by the arcane minutiae of muscular spasms, atmospheric friction, and chaos theory). Coin flips are perceived as the same. Irrelevant is the location of the coin flip, the atmosphere of the room, the force you apply – none seem to disturb the outcome of a fair coin. In contrast, epistemic uncertainty is perceived within single-case heterogenous events, such as propositions like “Is it true that Osama Bin Ladin is inside the compound”
As mentioned previously, these uncertainties elicit different kinds of information search (causal mental models versus counting), linguistic markers (“plausible” vs “chance”), and even different behaviors (exploration vs exploitation).
People experience epistemic uncertainty as more aversive. People prefer to guess the roll of a die, the sex of a child, and the outcome of a horse race before the event rather than after. Before a coin flip, we experience aleatory uncertainty; if you flip the coin and hide the result, out psychology switches to a more uncomfortable sense of epistemic uncertainty. We are often less willing to bet money when we experience significant epistemic uncertainty.
These epistemic discomforts of course make sense from an sociological perspective: if we sit under epistemic uncertainty, we are more vulnerable to being exploited – both materially by betting, and reputationally by appearing ignorant.
Several studies have found that although participants tend to be underconfident assessing probabilities that their specific answers are correct, they tend to be underconfident when later asked to estimate the proportion of items that they had answered correctly. While the particular mechanism driving this phenomenon is unclear, the pattern suggests that evaluations of epistemic vs aleatory uncertainty rely on distinct information, weights, and/or processes.
People can be primed to switch their representation. If you advise a person to “think like a statistician”, they will invariably This is true drawing balls from an urn: if you remove it but don’t show the color, people switch from Outside View (extensional) to Inside View (intensional).
Other Appearances of the Distinction
Perhaps the most famous expression of the distinction comes from Donald Rumsfeld in 2002:
As we know, there are known knowns; there are things we know we know. We also know there are known unknowns; that is to say we know there are some things we do not know. But there are also unknown unknowns—the ones we don’t know we don’t know. And if one looks throughout the history of our country and other free countries, it is the latter category that tend to be the difficult ones.
You can also find the distinction hovering in Barack Obama’s retrospective on the decision to raid a suspected OBL compound:
- The question of whether Osama Bin Laden was within the compound is an unknown fact – an epistemic uncertainty.
- The question of whether the raid would be successful is an outcome of a distribution – an alethic uncertainty.
A related distinction, Knightian uncertainty, comes from the economist Frank Knight. “Uncertainty must be taken in a sense radically distinct from the familiar notion of Risk, from which it has never been properly separated…. The essential fact is that ‘risk’ means in some cases a quantity susceptible of measurement, while at other times it is something distinctly not of this character; and there are far-reaching and crucial differences in the bearings of the phenomena depending on which of the two is really present and operating…. It will appear that a measurable uncertainty, or ‘risk’ proper, as we shall use the term, is so far different from an unmeasurable one that it is not in effect an uncertainty at all.” It is It is well illustrated by the Ellsburg Paradox:
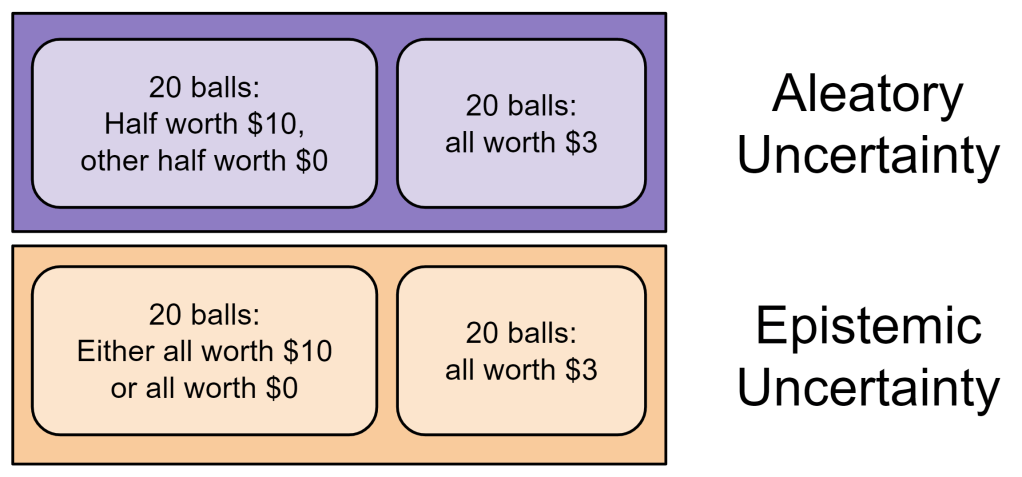
As Hsu et al (2005) demonstrates, people literally use different systems in their brains to process the above games. When the game structure is known, the reward processing centers (the basal ganglia) are used. When the game structure is unknown, fear processing centers (amygdala nuclei) are instead employed.
Mousavi & Gigerenzer (2017) use Knightian uncertainty to defend the rationality of heuristics in decision making. Nassim Taleb’s theory of “fat tailed distributions” are often interpreted as affirmations of Knightian uncertainty, a view he rejects.
Towards a Formal Theory
For some, Knightian uncertainty has been a rallying cry driven by discontents with orthodox probability theory. It is associated with efforts at replacing its Kolmogorov foundations. Intuitionistic probability theory, replacing classical axioms with computationally tractable alternatives, is a classic example of this kind of work. But as Weatherson (2003) notes, other alternatives exist:
It is a standard claim of modern Bayesian epistemology that reasonable epistemic states should be representable by probability functions. There have been a number of authors who have opposed this claim. For example, it has been claimed that epistemic states should be representable by Zadeh’s fuzzy sets, Dempster and Shafer’s evidence functions, Shackle’s potential surprise functions, Cohen’s inductive probabilities or Schmeidler’s non-additive probabilities. A major motivation of these theorists has been that in cases where we have little or no evidence for or against p, it should be reasonable to have low degrees of belief in each of p and not-p, something apparently incompatible with the Bayesian approach.
Evaluating the validity of these heterodoxies is beyond the scope of this article. For now, let me state that it may be possible to simply accommodate the epistemic/aleatory distinction within probability theory itself. As Andrew Gelman claims:
The distinction between different sources of uncertainty can in fact be encoded in the mathematics of conditional probability. So-called Knightian uncertainty can be modeled using the framework of probability theory.
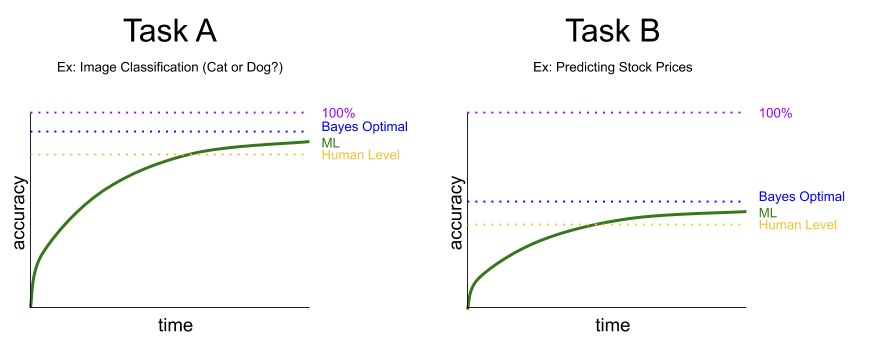
You can arguably see the distinction in the statistical concept of Bayesian optimality. For tasks with low aleatory uncertainty (e.g., classification on high-res images), classification performance can approach 100%. But other tasks with higher aleatory uncertainty (e.g., predicting future stock prices), model performance asymptotically approaches a much lower bound.
Recall the Bayesian interpretation of learning:
Learning is a plausibility calculus, where new data pays down uncertainty. What is uncertainty? Uncertainty is how “loosely held” our beliefs are. The more data we have, the less uncertain we must be, and the sharper the peaks in our belief distribution.
We can interpret learning as asymptoptic distribution refinement, some raw noise profile beyond which we cannot reach:
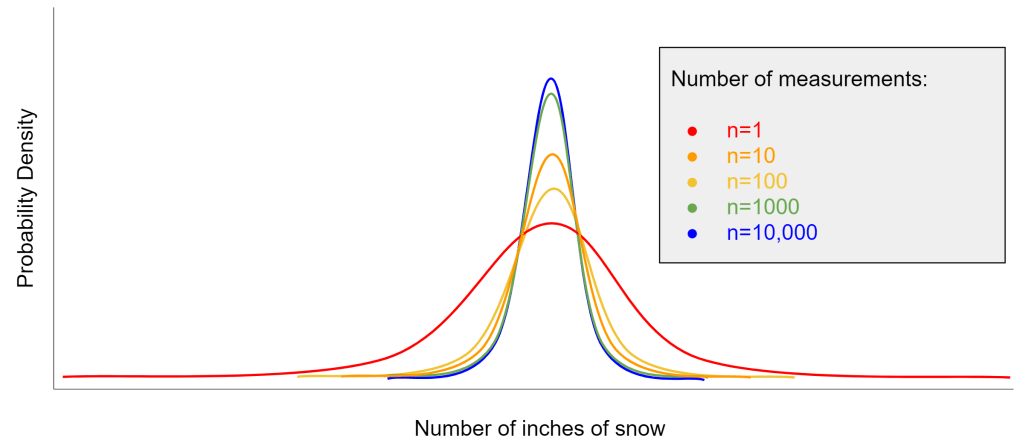
Science qua cultural learning, then, is not about certainty, not about facts etched into stone tablets. Rather, science is about painstakingly paying down epistemic uncertainty: sharpening our hypotheses to be “as simple as possible, but no simpler”.
Inside vs Outside View
The epistemic/aleatory distinction seems to play an underrated role in forecasting. Consider the inside vs outside view, first popularized by Kahneman & Lovallo (1993):
Two distinct modes of forecasting were applied to the same problem in this incident. The inside view of the problem is the one that all participants adopted. An inside view forecast is generated by focusing on the case at hand, by considering the plan and the obstacles to its completion, by constructing scenarios of future progress, and by extrapolating current trends. The outside view is the one that the curriculum expert was encouraged to adopt. It essentially ignores the details of the case at hand, and involves no attempt at detailed forecasting of the future history of he project. Instead, it focuses on the statistics of a class of cases chosen to be similar in relevant respects to the present one. The case at hand is also compared to other members of the class, in an attempt to assess its position in the distribution of outcomes for the class. …
Tetlock (2015) describes how superforecasters tend to start with the outside view,
It’s natural to be drawn to the inside view. It’s usually concrete and filled with engaging detail we can use to craft a story about what’s going on. The inside view is typically abstract, bare, and doesn’t lend itself so readily to storytelling. But superforecasters don’t bother with any of that, at least not at first.
Suppose I pose to you the following question. “The Renzettis live in a small house at 84 Chestnut Avenue. Frank Renzetti is forty-five and works as a bookkeeper for a moving company. Mary Renzetti is thirty-five and works part-time at a day care. They have one child, Tommy, who is five. Frank’s widowed mother, Camila, also lives with the family. Given all that information, how likely is it that the Renzettis have a pet?
A superforecaster knows to start with the outside view; in this case, the base rates. The first thing they would do is find out what percentage of American households own a pet. Starting from this probability, then you can slowly incorporating the idiosyncrasies of the Renzettis into your answer.
At first, it is very difficult to square this recommendation with how rats learn. This ordering is, in fact, precisely backwards:
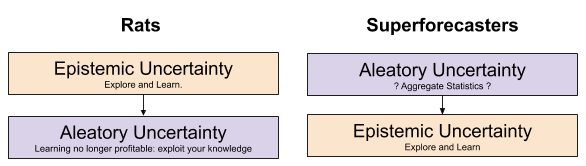
Fortunately, the tension disappears when you remember the human faculty of social learning. In contrast with rats, we don’t merely form beliefs from experience; we also ingest mimetic beliefs – those which we directly download from the supermind of culture. The rivaling fields of personal epistemology and social epistemology is yet another example of controversy reification.
This, then, is why Tetlock’s advice tends to work well in practice1:
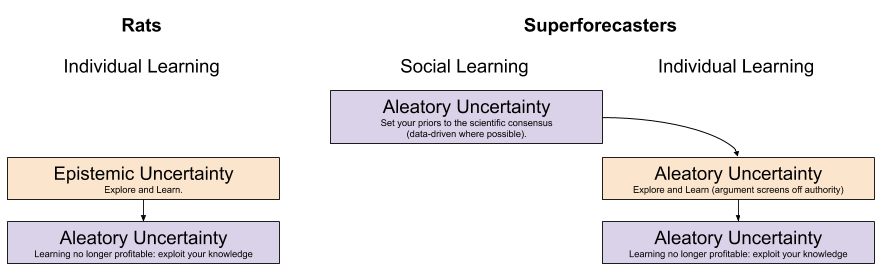
On some occasions, for some topics, humans cannot afford to engage in individual epistemic learning (see the evolution of faith). But for important descriptive matters, it is often advisable to start with a socially accepted position and “mix in” your own personal insights and perspectives (developing the Inside View).
When I read complaints about the blind outside view, what I hear is a simple defense of individual learning.
Footnotes
1. Even this individual/social distinction is not quite precise enough. There are in fact, two forms of social learning. Qualitative social learning is learning by speech generated by others, quantitative social learning is learning by maths and data curated by others. Figuring out how the quantitative/qualitative data intake mechanisms work is left as an exercise to the reader 😉

References
- Brun et al (2011). Two Dimensions of Uncertainty
- Hsu et al (2005). Neural Systems Responding to Degrees of Uncertainty in Human Decision-Making
- Kahneman & Lovallo (1993). Timid choices and bold forecasts: A cognitive perspective on risk taking
- Mousavi & Gigerenzer (2017). Heuristics are Tools for Uncertainty
- Tetlock (2015). Superforecasting
- Weatherson (2003). From Classical to Intuitionistic Probability.

Good stuff. You’ve convinced my basal ganglia, but my amygdala is unsure. I guess I’ll need to explore further.
LikeLiked by 1 person