Part Of: Language sequence
Content Summary: 1300 words, 13 min read
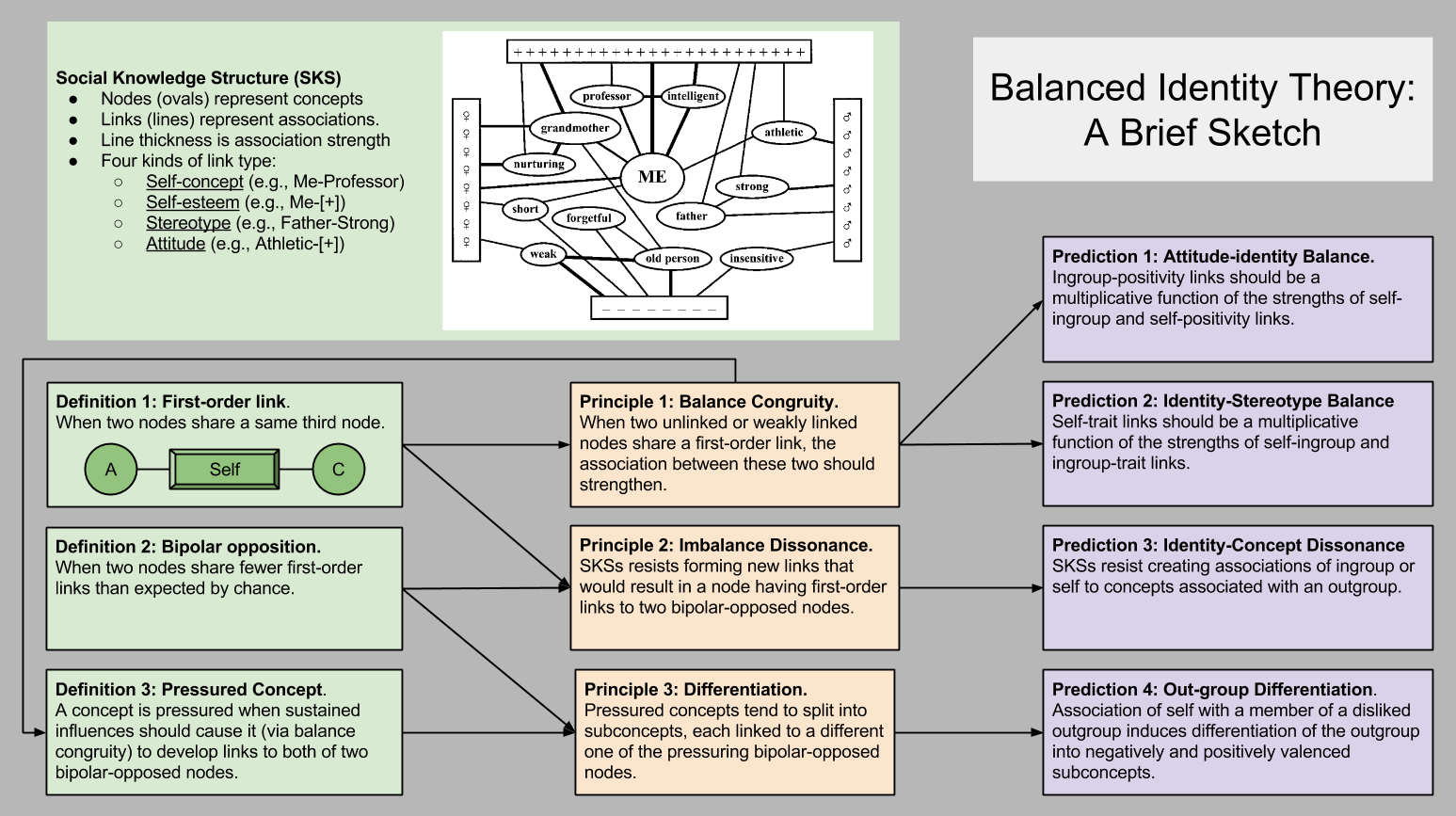
Two Tagging Methods
Imagine a library of a few million volumes, a small number of which are fiction. There are at least two reasonable methods with which one could distinguish fiction from nonfiction at a glance:
- Paste a red tag on each volume of fiction and a blue tag on each volume of nonfiction.
- Tag the fiction and leave the nonfiction untagged.
Perhaps the most striking feature of these two different systems is how similar they are. Despite the fact that the two libraries use somewhat different tagging systems, both ultimately accomplish the same end. Imagine each book If the labeling was done by a machine inside of a tiny closet – if a library user could not see with her own eyes the method employed, is there any hope of her discovering the truth method employed?
This is exactly the problem faced by cognitive scientists trying to understand the nature of belief. Your brain is responsible for maintaining a collection of beliefs (the mental library). Some of these beliefs are marked true (e.g., “fish swim”); others are marked false (e.g., “Santa Claus is real”). As philosophers in the 18th century discovered, your brain could process truth from falsehood in two distinct ways:
- Rene Descartes thought the brain uses the red-blue system. That is, it first tries to comprehend an idea (import the book) and then evaluate its status (give it the appropriate color).
- Baruch Spinoza thought the brain uses the tagged-untagged system. That is, it first tries to comprehend an idea (import the book) and then check whether it is fiction (decide whether it needs to be tagged).
Here is a graphical representations of the two brains:
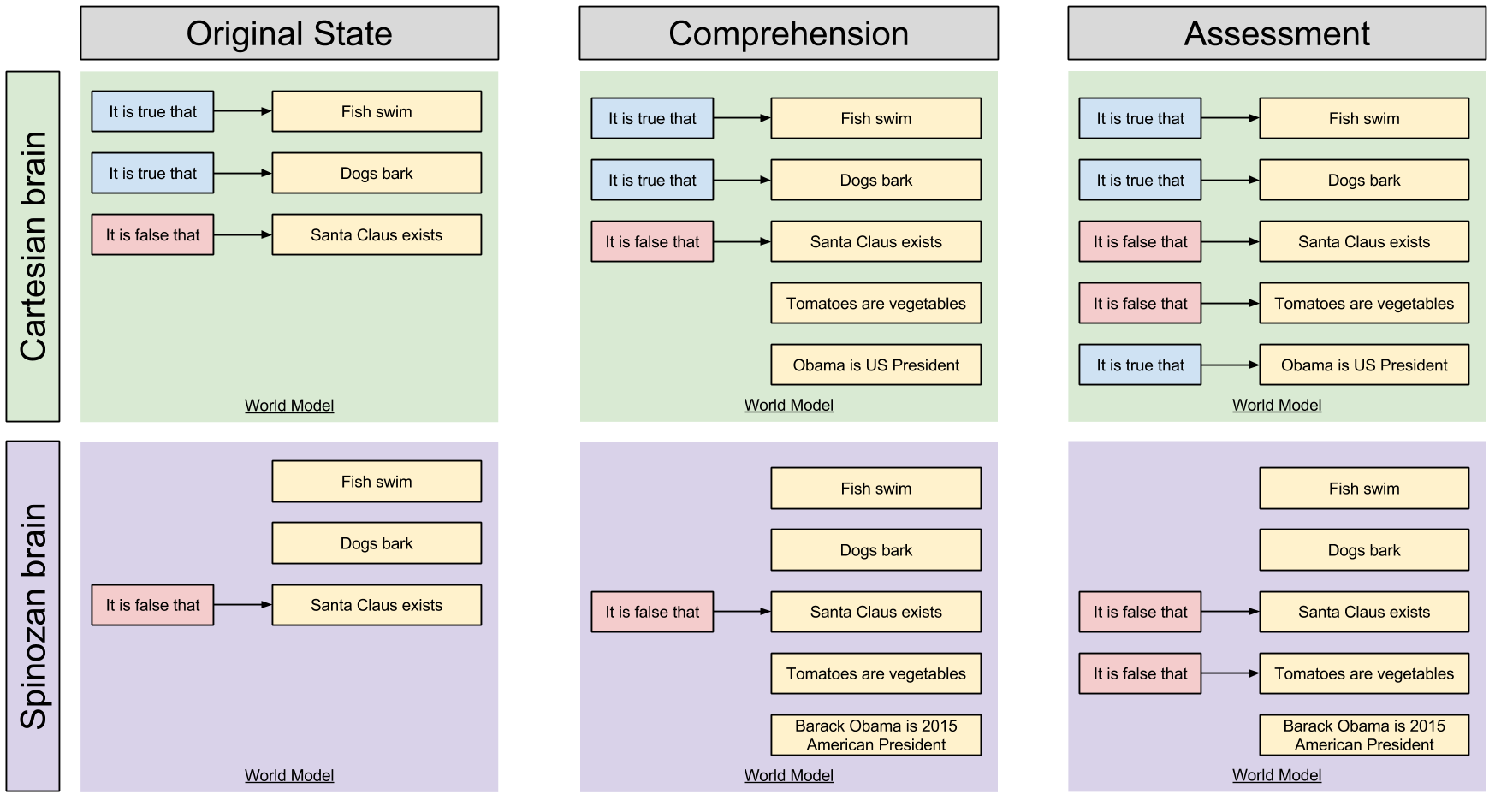
Would The Real Brain Please Stand Up?
Ideal mental systems have unlimited processing resources and an unstoppable tagging system. Real mental systems operate under imperfect conditions and a finite pool of resources, which causes these mental processes to sometimes fail. Sometimes, your brain isn’t able to assess beliefs at all.
What happens when a Cartesian red-blue brain is unable to fully assess incoming beliefs? Well, if the world model is left alone after comprehension (middle column), then resultant beliefs are neither marked true nor false, easily distinguishable from more trustworthy beliefs.
What happens when a Spinozan tagged-untagged brain cannot assess an incoming belief? Well, if its World Model processing stops after comprehension (middle column), then the novel claims appear identical to true beliefs.
On the Cartesian system, comprehension is distinct from acceptance. On a Spinozan system, comprehension is acceptance, and an additional (optional!) effort is required to unaccept belief. Cartesian brains are innately analytic, Spinozan brains are innately gullible.
So which is it? Is your brain Cartesian or Spinozan?
Three Reasons Why Your Brain Is Spinozan
Three streams of evidence independently corroborate the existence of the Spinozan brain.
First, scientists have confirmed time and again that distraction amplifies gullibility.
[Festinger & Maccoby 1964] demonstrated that subjects who listened to an untrue communication while attending to an irrelevant stimulus were particularly likely to accept the propositions they comprehended (see [Baron & Miller 1973] for a review of such studies)
When resource-depleted persons are exposed to doubtful propositions (i.e., propositions that they normally would disbelieve), their ability to reject those propositions is markedly reduced (see [Petty & Cacioppo 1986] for a review).
This effect appears in more complex scenarios, too. Suppose your friend Clyde says that “dragons exist”. In this scenario, the brain may not simply wish to reject that (first-order) claim, but also implement lie detection via rejecting the second-order proposition that “Clyde thinks that dragons exist”.
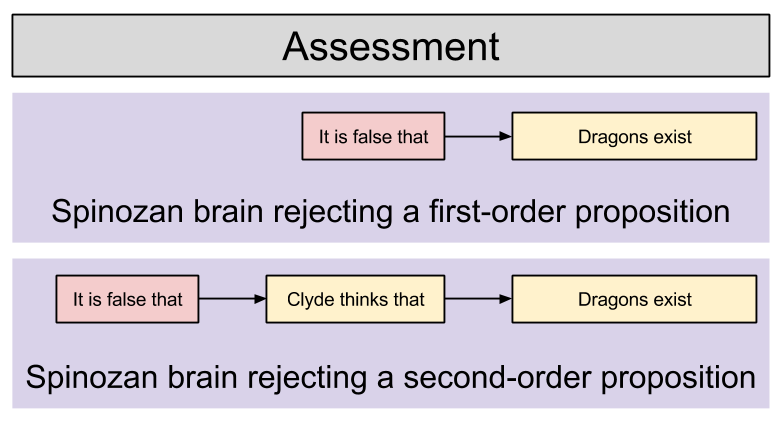
In the context of second-order propositions, distraction causes an even stronger inability to reject claims:
After decades of research activity, both the lie-detection and attribution literatures have independently concluded that people are particularly prone to accept the second-order propositions implicit in others’ words and deeds (for reviews of these literatures see, respectively, [Zuckerman, Depaulo, & Rosenthal 1981] and [Jones 1979]. What makes this phenomenon so intriguing is that people accept these assertions even when they know full well that the assertions stand an excellent chance of being wrong. For example, if an authority asks someone to read aloud a prepared statement (e.g., “I am in favor of federal protection of armadillos”), people [still] assume that the speaker believes the words coming out of the speaker’s mouth. This robust tendency is precisely the sort that a resource-depleted Spinozan system should display.
Not only does dubious position assertions more believable amidst distraction, the opposite of reasonable denials are also likely to be affirmed. That is, resource depletion will cause statements like “Bob Talbert not linked to Mafia” to induce belief in “Bob Talbert linked to Mafia”. The Cartesian model predicts no such asymmetry in response to resource depletion during assessment.
Second, children develop the ability to believe long before the ability to disbelieve.
The ability to deny propositions is, in fact, one of the last linguistic abilities to emerge in childhood [Bloom 1970] [Pea 1980] Although very young children may use the word no to reject, the denial function of the word is not mastered until quite a bit later.
Furthermore, young children are particularly prone to accept propositions uncritically (see [Ceci et al 1987]). Although such hypersuggestibility is surely exacerbated by the child’s inexperience and powerlessness, young children are more suggestible than older children even when such factors are taken into account [Ceci et al 1987].
Third, linguistic evidence shows that negative beliefs take longer to assess, and appear less frequently in practice.
A fundamental assumption of psycholinguistic research is that “complexity of in thought tends to be reflected in complexity of expression”, and vice versa. The markedness of a word is usually considered the clearest index of linguistic complexity… The Spinozan hypothesis states that acceptance is a more complex operation than is acceptance and, interestingly enough, the English words that indicate acceptance of ideas are generally unmarked. That is, our everyday language has us speaking of propositions as acceptable and unacceptable instead of rejectable and unrejectable. Indeed, people even speak of belief and disbelief more naturally than they speak of doubt and undoubt.
People are generally quicker to assess true statements, than false statements [Gough 1965].
How Should We Then Think?
Frankly, this was a difficult article to post. Knowing about biases can hurt people; that is, learning about their own flaws can make people defensive and inflexible.
But this sobering post need not cause us to abandon curiosity and pursuit of truth. It is the mark of an educated mind embrace a thought without flinching, to explore its consequences without fear. It is possible to change your mind.
Takeaways
This article was inspired by [Gilbert 1991] How Mental Systems Believe. Points to remember:
- How to tell truth from falsehood? You can either tag all beliefs true or false (Cartesian system) or only tag false belief (Spinozan system)
- Beliefs aren’t always fully analyzed. But in a Spinozan system, unassessed beliefs appear true – the system is credulous by default.
- Comprehension is belief: gullibility is innate. Only critical thinking is optional, effortful, and prone to failure. Your brain is Spinozan.
- How do we know? Because distraction causes thinkers to become more gullible
- How do we know? Because young children are very suggestible, only later acquiring the ability to be skeptical
- How do we know? Because negative beliefs take longer to assess, have more complex words, and appear less frequently in practice.
- The great master fallacy of the human mind is believing too much.
References
- [Baron & Miller 1973] The relation between distraction and persuasion.
- [Bloom 1970] Language development: Form and function in emerging grammars.
- [Ceci et al 1987] Suggestibility of children’s memory: Psychological implications.
- [Festinger & Maccoby 1964] On resistance to persuasive communications.
- [Gough 1965] The verification of sentences: The effects of delay of evidence and sentence length.
- [Jones 1979] The rocky road from acts to dispositions.
- [Pea 1980] The development of negation in early child language.
- [Petty & Cacioppo 1986] The elaboration likelihood model of persuasion.
- [Zuckerman, Depaulo, & Rosenthal 1981] Verbal and nonverbal communication of deception.