
Part Of: Information Theory sequence
Followup To: An Introduction To Communication
Content Summary: 900 words, 9 min read
Motivations
Information theory was first conceived as a theory of communication. An employee of Bell Labs, Shannon was interested in the problem of noise. Physical imperfections on your data cable, for example, can distort your signal.
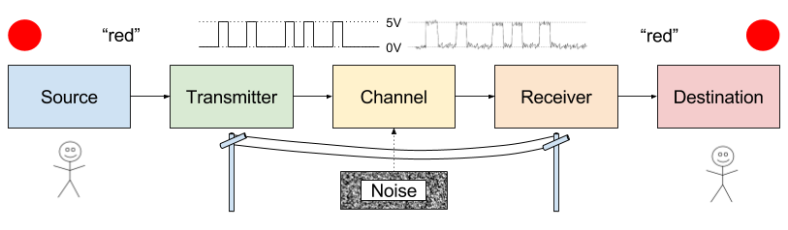
How to protect against noise? One answer is to purchase better equipment.
But there is another, less expensive answer. Errors can be reduced by introducing redundancy into their signals. But redundancy has a price: it also slows the rate of communication.
Shannon strove to understand this error vs rate trade-off quantitatively. Is error-free communication possible? And if so, how many extra bits would that require?
Before we can appreciate Shannon’s solution, it helps to understand the basics of error correcting codes (ECC). We turn first to a simple ECC: replication codes.
Replication Codes
Error correcting codes have two phases: encoding (where redundancy is injected) and decoding (where redundancy is used to correct errors)
Consider repetition code R3, with the following encoding scheme:
0 → 000
1 → 111
Decoding occurs via majority rule. If most bits are zero the original bit is a 0, and vice versa. Explicitly:
000, 001, 010, 100 → 0
111, 110, 101, 011 → 1
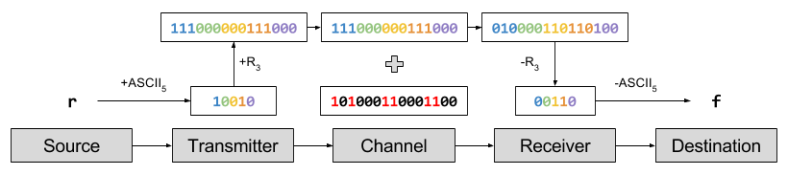
Suppose I want to communicate the word “red” to you. To do this, I encode each letter into ASCII and send those bits over the Internet, to be consumed by your Internet browser. Using our simplified ASCII: ‘r’ → 10010. To protect from noise, we repeat each bit three times: 10010 → 111000000111000.
Let us imagine that 6 bits are flipped: 101000110001100. The last error caused the code 000 → 100, which the decoding algorithm successfully ignores. But the first two noise events caused 111 → 010, which causes a decoding error. These decoding errors in turn change the ASCII interpretation. This pattern of noise will cause you to receive the word “fed”, even though I typed “red”.
Analysis of Repetition Codes
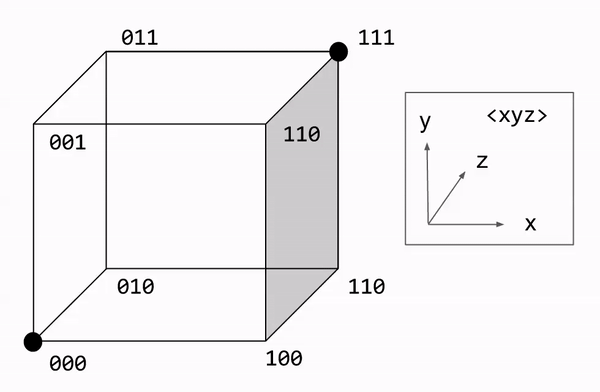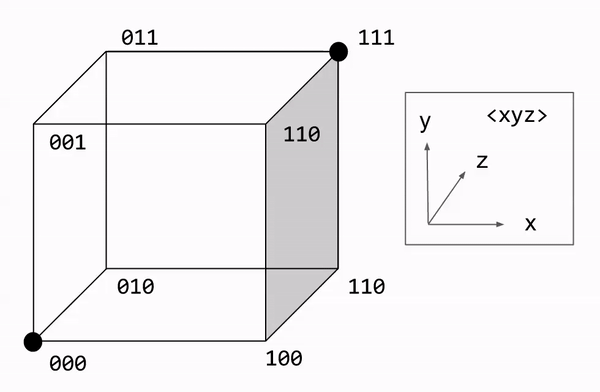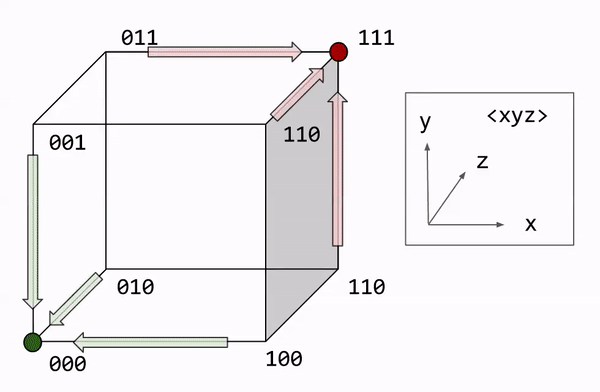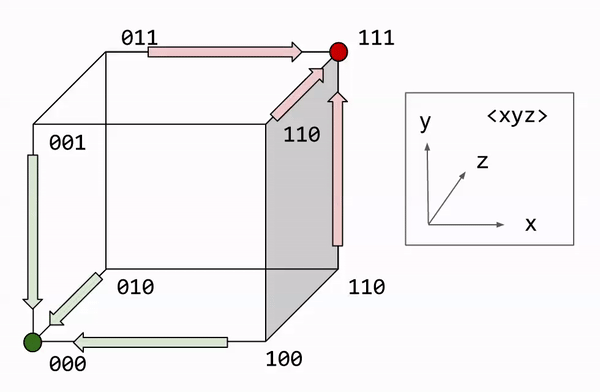
Let us formalize the majority rule algorithm. Decoding involves counting the number of bit flips required to restore the original message. We express this number as the Hamming distance. This can be visualized graphically, with each bit corresponding to a dimension. On this approach, majority rule becomes a nearest neighbor search.
What is the performance of R3? Let us call noise probability p, the chance of any one bit flip. We can model the total number of errors with the binomial distribution:
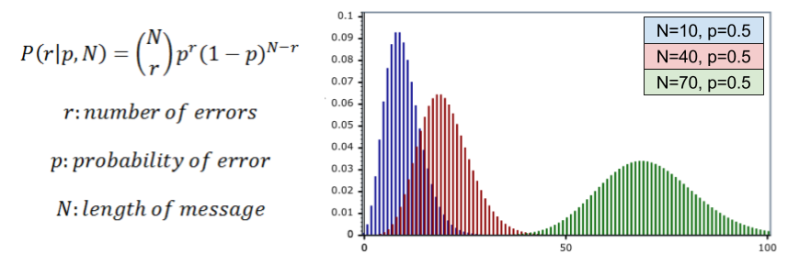
In R3, a decoding error requires two bit flips within a 3-bit block. Thus, P(error) = P(r >= 2|p, 3). We can then compute the frequency of decoding errors.

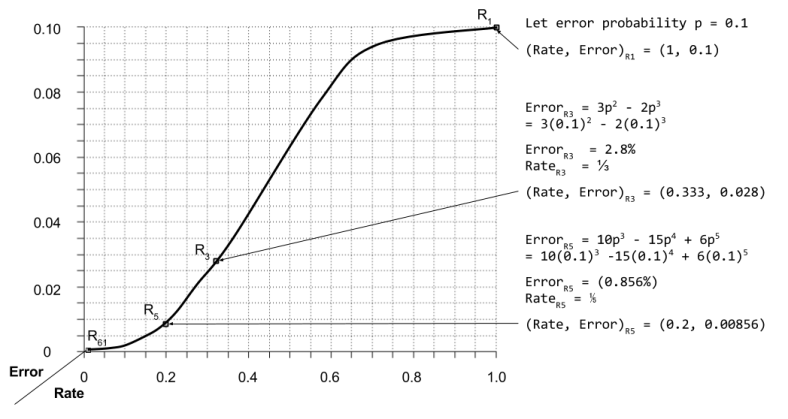
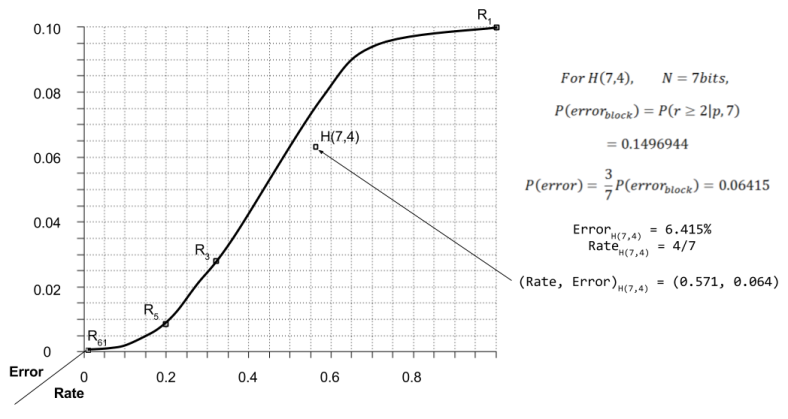
For p = 10% error rate, we can graph R3 vs R5 performance:
Hamming Codes
In error correcting codes, we distinguish redundant bits versus message bits. Replication codes have a very straightforward mapping between these populations. However, we might envision schemes where each redundant bit safeguards multiple message bits.
Consider the Hamming code, invented in 1950. Richard Hamming shared an office with Claude Shannon for several years. He is also the father of Hamming distance metric, discussed above.
Hamming codes split messages into blocks, and add redundant bits that map to the entire block. We will be examining the H(7,4) code. This code takes 4-bit blocks, and adds three redundant bits at the end. Each redundant bit then “maps to” three of the message bits:
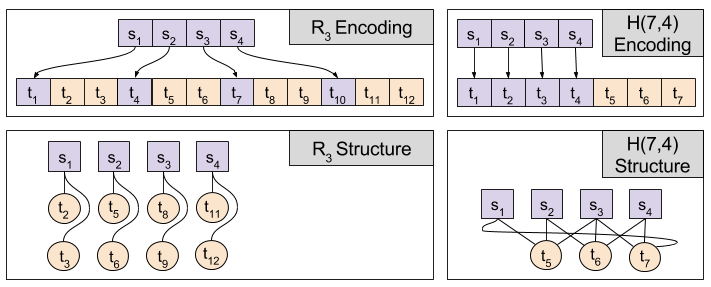
We now define the encoding and decoding algorithms for Hamming Codes. Let message bits s ∈ S be organized into blocks. Let each redundant bit t ∈ T map to a particular subset of the block. For example, s(t7) → { s3, s4, s1 }.
For H(7,4) code, each redundant bit maps to a set of three message bits. If there are an odd number of 1s in this set, the redundant bit is set to 1. Otherwise, it is set to zero. Binary addition (eg., 1+1=0) allows us to express this algebraically:
ti = ∑ s(ti)
A Venn diagram helps to visualize this encoding: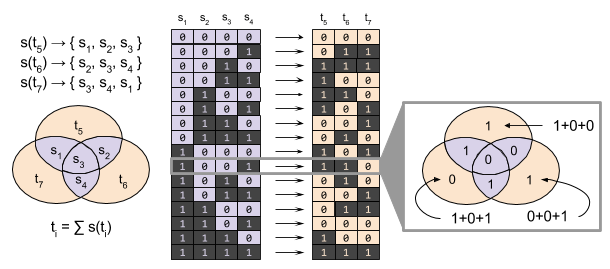
H(7,4) decoding is complicated by the fact that both message bits and redundant bits can be corrupted by noise. We begin by identifying whether there are any inequalities between ti versus ∑ s(ti). If there is, that means *something* has gone wrong.
For H(7,4), there are three redundant bits in every block; there are thus eight different syndromes (error signatures). The decoding algorithm must respond to each possible syndrome, as follows:
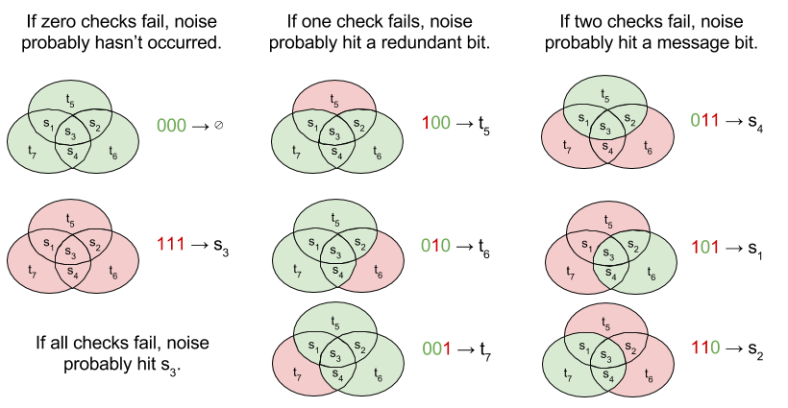
The error rate for H(7,4) is calculated as follows.
Application To Information Theory
This example demonstrates that Hamming codes can outperform replication codes. By making the structure of the redundant bits more complex, it is possible to reduce noise while saving space.
Can error-correcting codes be improved infinitely? Or are there limits to code performance, besides human imagination?
Shannon proved that there are limits to error-correcting codes. Specifically, he divides the error-rate space into attainable and unattainable regions:
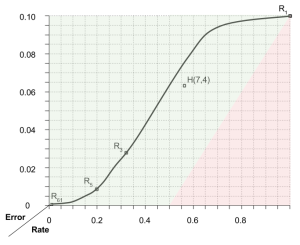
Another important result of information theory is the design of decoding algorithms. Decoding H(7,4) is perhaps the most complex algorithm presented above. For more sophisticated ECCs, these decoding tasks become even more difficult.
Information theory provides a principled way to automate the discovery of optimal decoding algorithms. By applying the principle of maximum entropy, we can radically simplify the process of designing error-correcting codes.
We will explore these ideas in more detail next time. Until then!
