Part Of: Reinforcement Learning sequence
Followup To: An Introduction To Markov Chains
Content Summary: 900 words, 9 min read
Motivations
Today, we turn our gaze to Markov Decision Processes (MDPs), a decision-making environment which supports our propensity to learn from good and bad outcomes. We represent outcome desirability with a single number, R. This value is used to refine action selection: given a particular situation, what action will maximize expected reward?
In biology, we can describe the primary work performed by an organism is to maintain homeostasis: maintaining metabolic energy reserves, body temperature, etc in a widely varying world.
Cybernetics provide a clear way of conceptualizing biological reward. In Neuroendocrine Integration, we discussed how brains must respond both to internal and external changes. This dichotomy expresses itself as two perception-action loops: a visceral body-oriented loop, and a cognitive world-centered one.
Rewards are computed by the visceral loop. To a first approximation, reward encode progress towards homeostasis. Food is perceived as more rewarding when the body is hungry, this is known as alliesthesia. Reward information is delivered to the cognitive loop, which helps refine its decision making.

Extending Markov Chains
Recall that a Markov Chain contains a set of states S, and a transition model P. A Markov Decision Process (MDP) extends this device, by adding three new elements.
Specifically, an MDP is a 5-tuple (S, P, A, R, ɣ):
- A set of states s ∈ S
- A transition model Pa(s’ | s).
- A set of actions a ∈ A
- A reward function R(s, s’)
- A discount factor ɣ
To illustrate, consider GridWorld. In this example, every location in this two-dimensional grid is a state, for example (1,0). State (3,0) is a desirable location: R(s(3,0)) = +1.0, but state (3,1) is undesirable, R(s(3,1)) = -1.0. All other states are neutral.
Gridworld supports four actions, or movements: up, down, left, and right. However, locomotion is imperfect: if Up is selected, the agent will only move up with 80% probability: 20% of the time it will go left or right instead. Finally, attempting to move into a forbidden square will simply return the agent to its original location (“hitting the wall”).

The core problem of MDPs is to find a policy (π), a function that specifies the agent’s response to all possible states. In general, policies should strive to maximize reward, e.g., something like this:

Why is the policy at (2,2) Left instead of Up? Because (2,1) is dangerous: despite selecting Up, there is a 10% chance that the agent will accidentally move Right, and be punished.
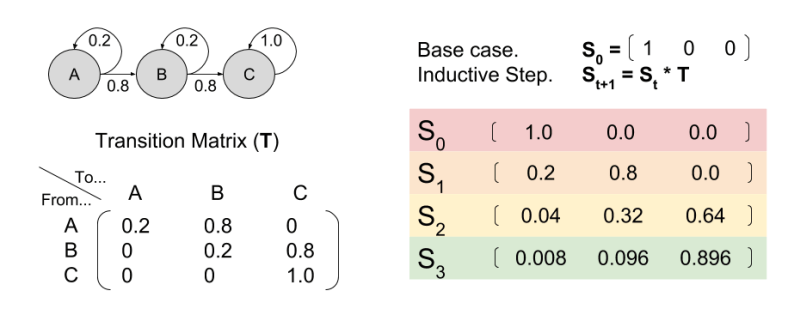
Let’s now consider an environment with only three states A, B, and C. First, notice how different policies change the resultant Markov Chain:

This observation is important. Policy determines the transition model.
Towards Policy Valuation V(s)
An agent seeks to maximize reward. But what does that mean, exactly?
Imagine an agent selects 𝝅1. Given the resultant Markov Chain, we already know how to use matrix multiplication to predict future locations St. The predicted reward Pt is simply the dot product of expected location and the reward function.

We might be tempted to define the value function V(S) as the sum of all predicted future rewards:

However, this approach is flawed. Animals value temporal proximity: all else equal, we prefer to obtain rewards quickly. This is temporal discounting: as rewards are further removed from the present, their value is discounted.
In reinforcement learning, we implement temporal discounting with the gamma parameter: rewards that are k timesteps away are multiplied by the exponential discount factor  . The value function becomes:
. The value function becomes:
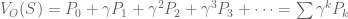
Without temporal discounting, V(s) can approach infinity. But exponential discounting ensures V(s) equals a finite value. Finite valuations promote easier computation and comparison of state evaluations. For more on temporal discounting, and an alternative to the RL approach, see An Introduction to Hyperbolic Discounting.
Intertemporal Consistency
In our example, at time zero our agent starts in state A. We have already used linear algebra to compute our Pk predictions. To calculate value, we simply compute $latex \sum{\gamma^k P_k}$

Agents compute V(s) at every time step. At t=1, two valuations are relevant:

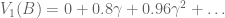
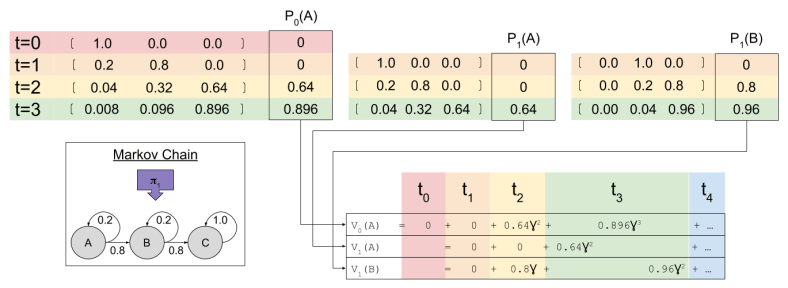
What is the relationship between the value functions at t=0 and t=1? To answer this, we need to multiply each term by  , where
, where  is the state being considered at the next time step.
is the state being considered at the next time step.
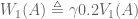

Similarly,

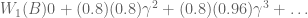
Critically, consider the sum  :
:


Does  look familiar? That’s because it equals
look familiar? That’s because it equals  ! In this way, we have a way of equating a valuation at t=0 and t=1. This property is known as intertemporal consistency.
! In this way, we have a way of equating a valuation at t=0 and t=1. This property is known as intertemporal consistency.
Bellman Equation
We have seen that 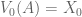 . Let’s flesh out this equation, and generalize to time t.
. Let’s flesh out this equation, and generalize to time t.
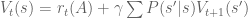
This is the Bellman Equation, and it is a central fixture in control systems. At its heart, we define value in terms of both immediate reward and future predicted value. We thereby break up a complex problem into small subproblems, a key optimization technique that can be approached with dynamic programming.
Next time, we will explore how reinforcement learning uses the Bellman Equation to learn strategies with which to engage its environment (the optimal policy 𝝅). See you then!