
Part Of: Breakdown of Will sequence
Followup To: Rule Feedback Loops
Content Summary: 1300 words, 13 min read
Context
Here’s where we landed last time:
- Preference bundling is mentally implemented via a database of personal rules (“I will do X in situations that involve Y).
- Personal rules constitute a feedback loop, whereby rule-compliance strengthen (and rule-circumvention weakens) the circuit.
Today’s post will draw from the following:
- An Introduction To Hyperbolic Discounting discusses warfare between successive selves (e.g., OdysseusNOW restricts the freedoms of OdysseusFUTURE in order to survive the sirens).
- An Introduction To Prisoner’s Dilemma discusses how maths can be used to describe the outcome of games between competitors.
Time to connect these threads! 🙂 Let’s ground our warfare narrative in the formal systems of game theory.
Schizophrenic’s Dilemma
First, we interpret { larger-later (LL) vs. smaller-sooner (SS) } rewards in terms of { cooperation vs. defection } decisions.
Second, we name our actors:
- P represents your present-self
- F represents your future-self
- FF represents your far-future-self, etc.
Does this game suffer from the same issue as classical PD? Only one way to find out!

Here’s how I would explain what’s going on:
- Bold arrows represent decisions, irreversible choices in the real world. Decisions lock in final scores (yellow boxes).
- Skinny arrows represent intentions, the construction of rules for future decisions.
- The psychological reward you get from setting intentions is just as real as that produced by decisions.
- Reward is accretive: your brain seeks to maximize the sum total reward it receives over time.
Take some time to really ingest this diagram.
Iterated Schizophrenic’s Dilemma (ISD)
Okay, so we now understand how to model intertemporal warfare as a kind of “Schizophrenic’s Dilemma“. But we “have to live with ourselves” — the analogy ought to be extended across more than one decision. Here’s how:
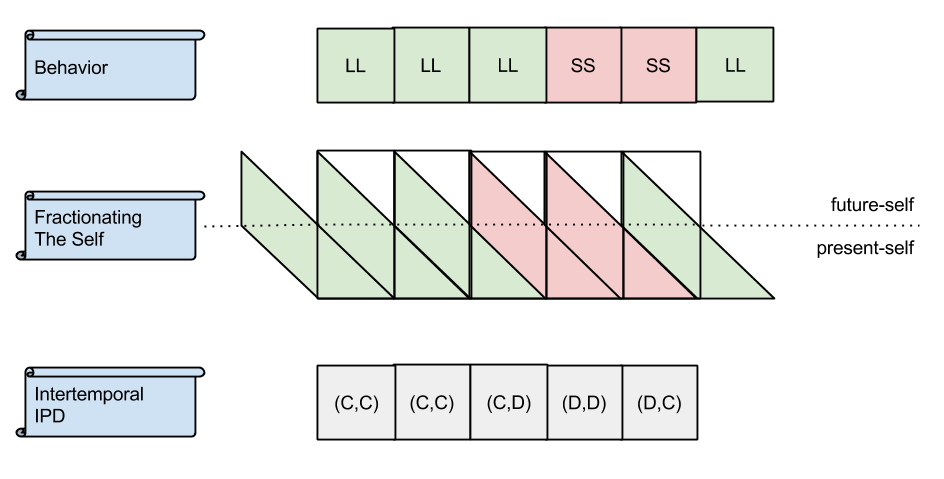
Time flows from left to right. In the first row, we see that an organism’s choices are essentially linear. For each choice, the reasoner selects either an LL (larger-longer) or an SS (smaller-sooner) reward. How can this be made into a two-dimensional game? We can achieve this graphically by “stretching each choice point up and to the left”. This move ultimately implements the following:
- Temporal Continuity: “the future-self of one time step must be equivalent to the present-self of the next time step”.
It is by virtue of this rule that we are able to conceptualize the present-self competing against the future-self (second row). The third row simply compresses the second into one state-space.
Let us call this version of the Iterated Prisoner’s Dilemma, the Iterated Schizophrenic’s Dilemma. For the remainder of this article, I will use IPD and ISD to distinguish between the two.
The Lens Of State-Space
We have previously considered decision-space, and outcome-space. Now we shall add a third space, what I shall simply call state-space (very similar to Markov Decision Processes…)

You’ll notice that the above state-space is a fully-connected graph: in IPD, any decision can be made at any time.
But this is not true in ISD, which must honor the rule of Temporal Continuity. For example, (C, C) -> (D, C) violates that “the future-self of one time step must be equivalent to the present-self of the next time step”. The ISD State-Space results from trimming all transitions that violate Temporal Continuity:
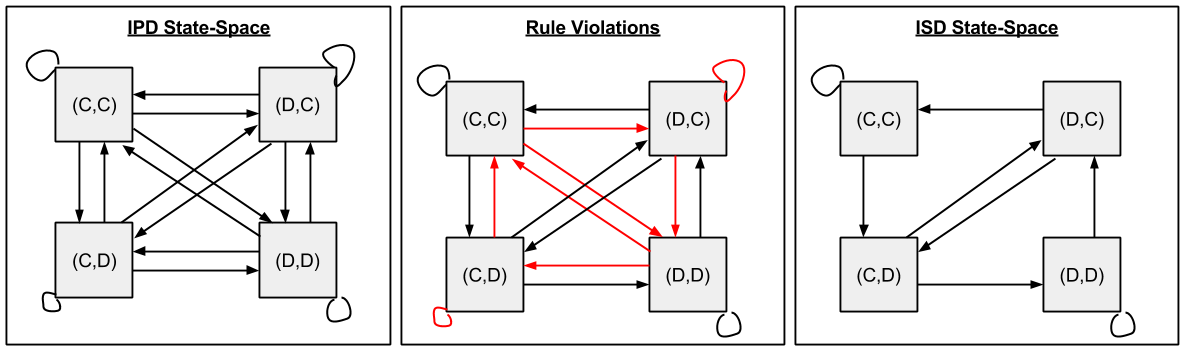
Let me briefly direct your attention to three interesting facts:
- Half of the edges are gone. This is because information now flows in only one direction.
- Every node is reachable; no node has been stranded by the edge pruning.
- (C,D) and (D,C) are necessarily transient states; only (C, C) and (D,D) can recur indefinitely.
Intertemporal Retaliation
Four qualities of successful IPD strategies are: nice, forgiving, non-envious, and retaliating. How does retaliation work in the “normal” IPD?
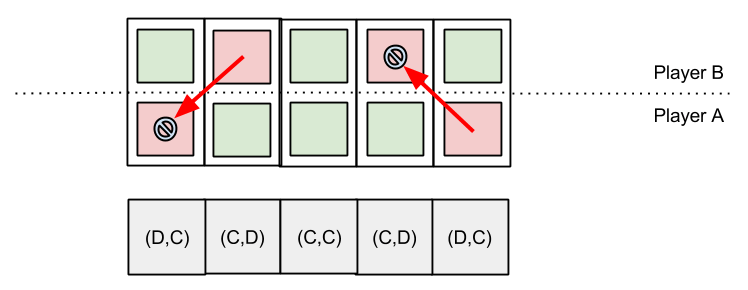
Here we have two cases of retaliation:
- At the first time-step, Player A defects “unfairly”. Incensed, Player B retaliates (defects) next turn.
- At the fourth time-step, Player B takes advantage of A’s goodwill. Outraged, Player A punishes B next turn.
Note the easy two-way symmetry. But in the ISD case, the question of retaliation becomes very complex:
- Present-selves may “punish” future-selves by taking an earlier reward, now.
- But future-selves cannot punish present-selves, obviously, because time does not flow in that direction.
What, then, is to motivate our present-selves to “keep the faith”? To answer this, we need only appeal to the feedback nature of personal rules (explored last time)!
I’ll let Ainslie explain:
As Bratman has correctly argued (Bratman 1999, pp. 35-57), a present “person-stage” can’t retaliate against the defection of a prior one, a difference that disqualifies the prisoner’s dilemma in its classical form as a rationale for consistency. However, insofar as a failure to cooperate will induce future failures, a current decision-maker contemplating defection faces a danger of the same kind as retaliation…
With the question of retaliation repaired, the analogy between IPD and ISD seems secure. Ainslie has earned the right to invoke IPD explananda; for example:
The rules of this market are the internal equivalent of “self-enforcing contracts” made by traders who will be dealing with each other repeatedly, contracts that let them do business on the strength of handshakes (Klein & Leffler 1981; Macaulay 1963).
Survival Of The Salient
After casting warfare of successive selves into game theoretic terms, we are in a position to import other concepts. Consider the Schelling point, the notion that salient choices function as an attractor between competitors. Here’s an example of the Schelling point:
Consider a simple example: two people unable to communicate with each other are each shown a panel of four squares and asked to select one; if and only if they both select the same one, they will each receive a prize.Three of the squares are blue and one is red. Assuming they each know nothing about the other player, but that they each do want to win the prize, then they will, reasonably, both choose the red square. Of course, thered square is not in a sense a better square; they could win by both choosing any square. And it is only the “right” square to select if a player can be sure that the other player has selected it; but by hypothesis neither can. However, it is the most salient and notable square, so—lacking any other one—most people will choose it, and this will in fact (often) work.
By virtue of the feedback mechanism discussed above, rules are adapt over time via a kind of variation on natural selection (“survival of the salient“):
Intertemporal cooperation is most threatened by rationalizations that permit exceptions for the choice at hand, and is most stabilized by finding bright lines to serve as criteria for what constitutes cooperation. A personal rule never to drink alcohol, for instance, is more stable than a rule to have only two drinks a day, because the line between some drinking and no drinking is unique (bright), while the two-drinks rule does not stand out from some other number, or define the size of the drinks, and is thus susceptible to reformulation. However, skill at intertemporal bargaining will let you attain more flexibility by using lines that are less bright. This skill is apt to be a key component of the control processes that get called ego functions.
In the vocabulary of our model, it is the peculiarities of the preference bundling module whereby Schelling points are more effectual.
Let us close by, in passing, noting that this line of argument can be generalized into a justification for slippery slope arguments.
Takeaways
- Warfare of successive selves can be understood in terms of the Prisoner’s Dilemma, where cooperation with oneself is selecting LL, and defection is SS.
- In fact, intertemporal bargaining can be successfully explained via a modified form of the Iterated Prisoner’s Dilemma, since retaliation works via a unique feedback mechanism.
- Because our model of willpower spans both a game-theoretic and cognitive grammar, we can make sense of a “survival of the salient” effect, whereby memorable rules persist longer.
