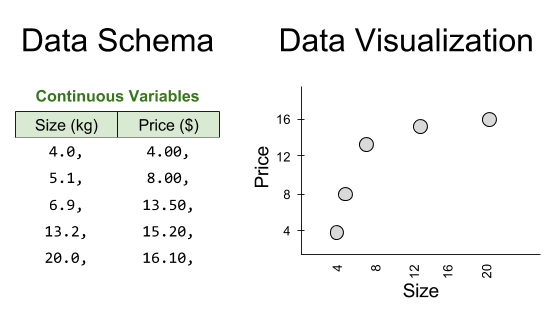
Part Of: Demystifying Physics sequence
Content Summary: 1200 words, 12 min read
Motivations
Consider the following puzzle. Can you tell me the answer?
We see an object O. Under white light, O appears blue. How would O appear, if it is placed under a red light?
As with many things in human discourse, your simple vocabulary (color) is masking a more rich reality (quantum electrodynamics). These simplifications generate the correct answers most of the time, and make our mental lives less cluttered. But sometimes, they block us from reaching insights that would otherwise reward us. Let me “pull back the curtain” a bit, and show you what I mean.
The Humble Photon
In the beginning was the photon. But what is a photon?
Photons are just one type of particle, in this particle zoo we call the universe. Photons have no mass and no charge. This is not to say that all photons are the same, however: they are differentiated by how much energy they possess.
Do you remember that famous equation of Einstein’s, 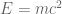 ? It is justly famous for demonstrating mass-energy interchangeability. If you are set up a situation to facilitate a “trade”, you can purchase energy by selling mass (and vice versa). Not only that, but you can purchase a LOT of energy with very little mass (the ratio is about 90,000,000,000,000,000 to 1). This kind of lopsided interchangeability helps us understand why things like nuclear weapons are theoretically possible. (In nuclear weapons, a small amount of uranium mass is translated into considerable energy). Anyways, given , can you find the problem with my statement above?
? It is justly famous for demonstrating mass-energy interchangeability. If you are set up a situation to facilitate a “trade”, you can purchase energy by selling mass (and vice versa). Not only that, but you can purchase a LOT of energy with very little mass (the ratio is about 90,000,000,000,000,000 to 1). This kind of lopsided interchangeability helps us understand why things like nuclear weapons are theoretically possible. (In nuclear weapons, a small amount of uranium mass is translated into considerable energy). Anyways, given , can you find the problem with my statement above?
Well, if photons have zero mass, then plugging in 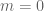 to tells us that all photons have the same energy: zero! This falsifies my claim that photons are differentiated by energy.
to tells us that all photons have the same energy: zero! This falsifies my claim that photons are differentiated by energy.
Fortunately, I have a retort: is not true; it is only an approximation. The actual law of nature goes like this (p stands for momentum):

Since for photons, we can eliminate the left-hand side of the equation. This leaves  (“energy equals momentum times speed-of-light”). We also know that that
(“energy equals momentum times speed-of-light”). We also know that that  (“momentum equals Planck’s constant divided by wavelength”). Putting these together yields the cumulative value for energy of a photon:
(“momentum equals Planck’s constant divided by wavelength”). Putting these together yields the cumulative value for energy of a photon:
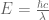
Since h and c are just constants, the relation becomes very simple: energy is inversely proportional to wavelength. Rather than identifying a photon by its energy, then, let’s identify it by its wavelength. We will do this because wavelength is easier to measure (in my language, we have selected a measurement-affine independent variable).
Meet The Spectrum
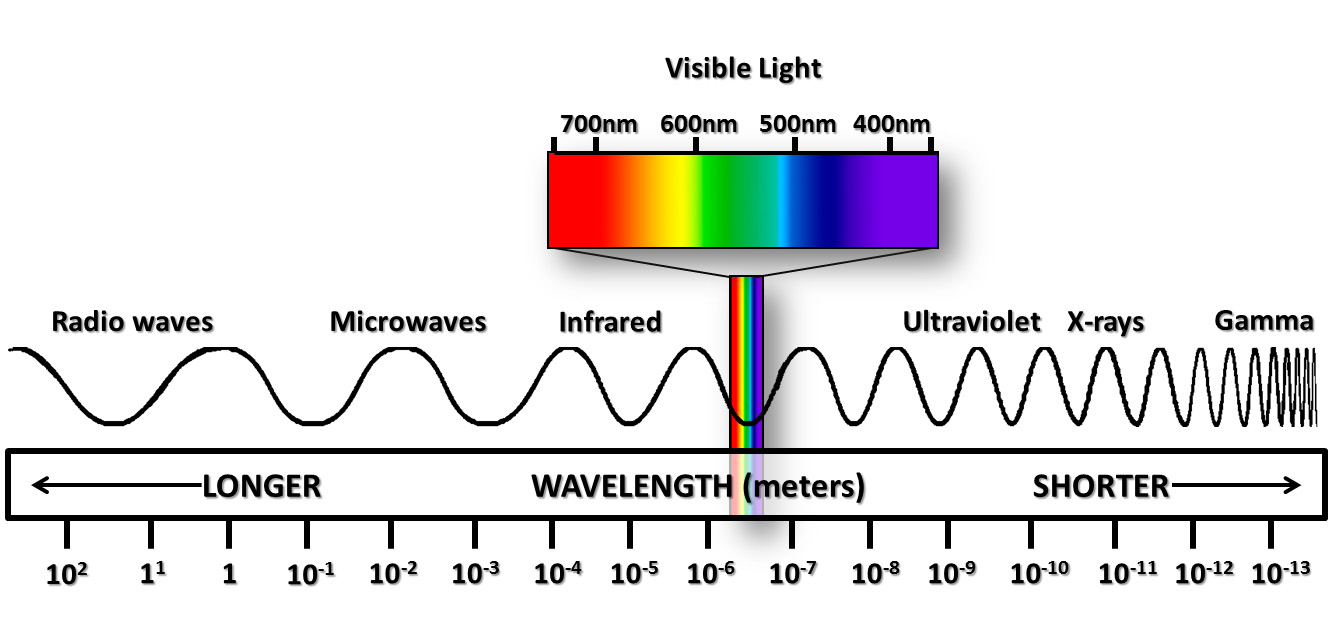
So we can describe one photon by its wavelength. How about billions? In such a case, it would be useful to draw a map, on which we can locate photon distributions. Such a photon map is called an electromagnetic spectrum. It looks like this:

Pay no attention to the colorful thing in the middle called “visible light”. There is no such distinction in the laws of nature, it is just there to make you comfortable.
Model Building
We see an object O.
Let’s start by constructing a physical model of our problem. How does seeing even work?
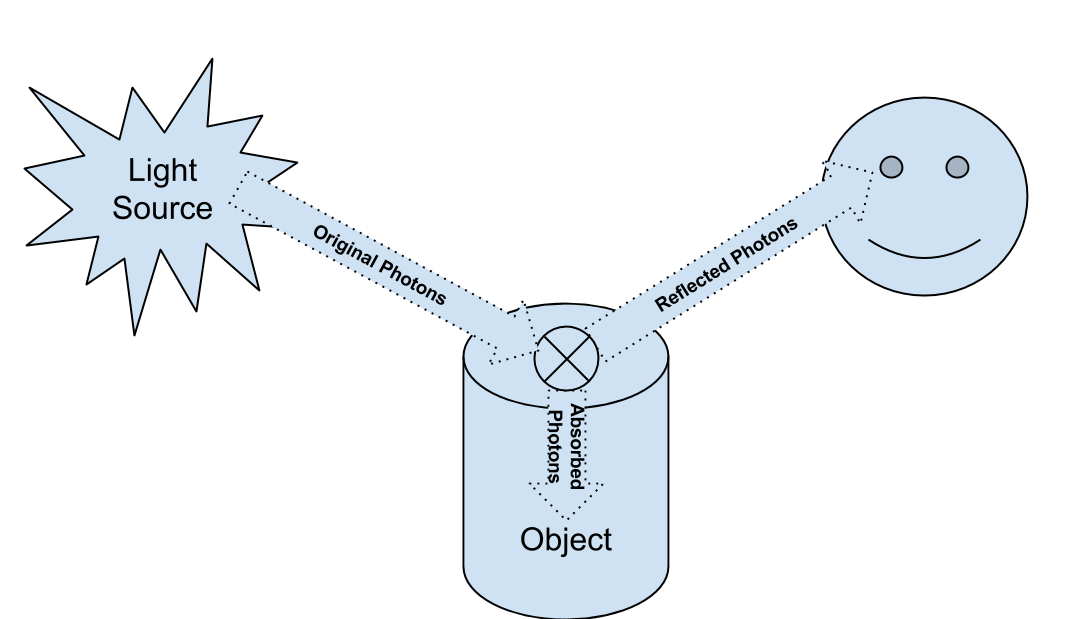
Once upon a time, the emission theory of vision was in vogue. Plato, and many other renowned philosophers, believed that perception occurs in virtue of light emitted from our eyes. This theory has since been proven wrong. The intromission theory of vision has been vindicated: we see in virtue of the fact that light (barrages of photons) emitted by some light source, arrives at our retinae. The process goes like this:

If you understood the above diagram, you’re apparently doing better than half of all American college students… who still affirm emission theory… moving on.
Casting The Puzzle To Spectra
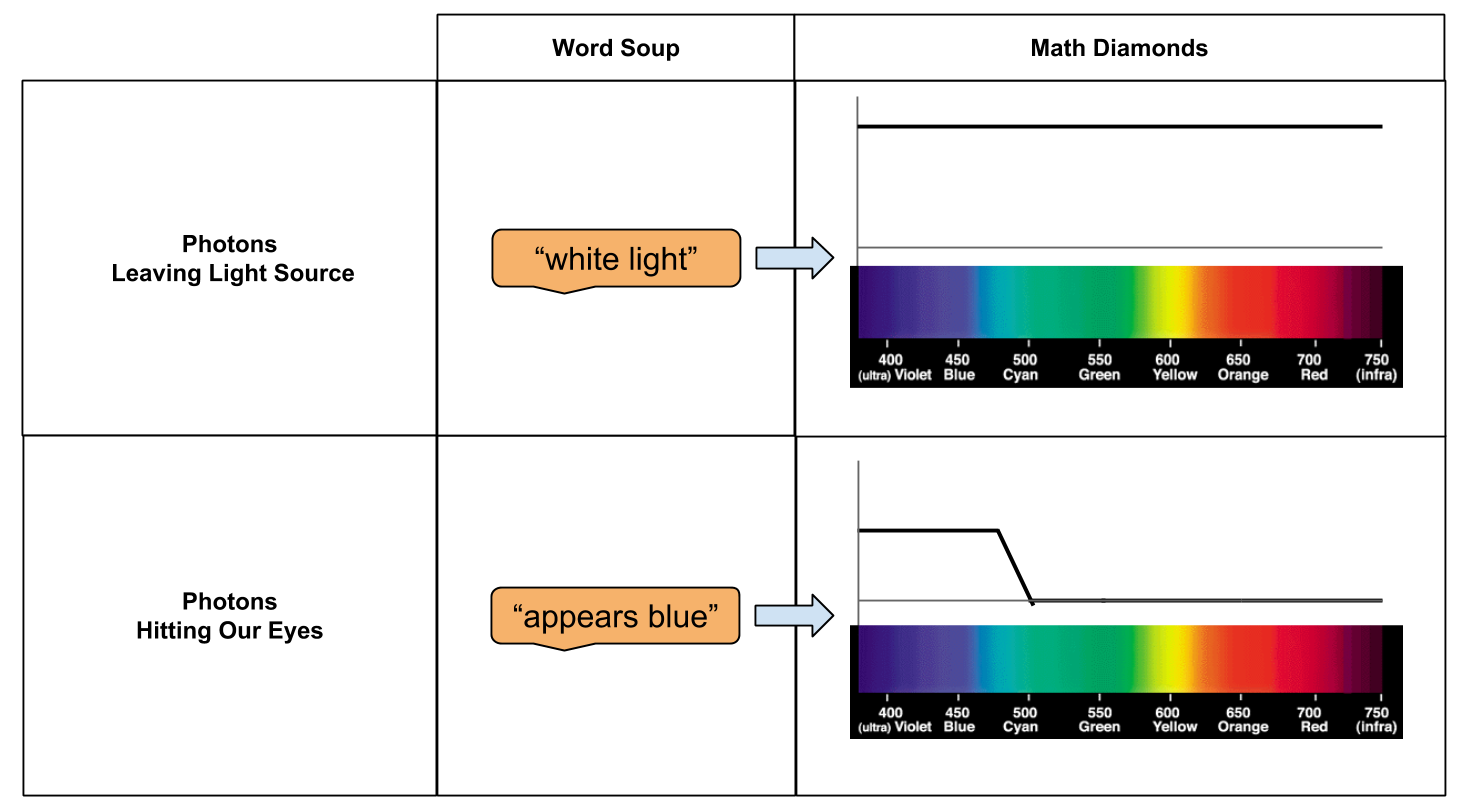
Under white light, O appears blue.
White is associated with the activation of all of the spectra (this is why prisms work). Blue is associated with high-energy light (this is why flames are more blue at the base). We are ready to cast our first sentence. To the spectrum-ifier!

Building A Prediction Machine
Here comes the key to solving the puzzle. We are given two data points: photon behavior at the light source, and photon behavior at the eye. What third location do we know is relevant, based on our intromission theory discussion above? Right: what is photon behavior at the object?
It is not enough to describe the object’s response to photons of energy X. We ought to make our description of the object’s response independent from details about the light source. If we could find the reflection spectrum (“reflection signature“) of the object, this would do the trick: we could anticipate its response to any wavelength. But how do we infer such a thing?
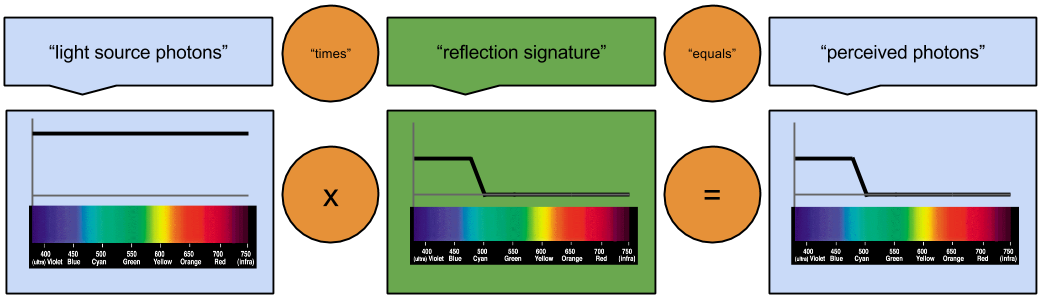
We know that light-source photons must interact with the reflection signature to produce the observed photon response. Some light-source photons may be always absorbed, others may be always reflected. What sort of mathematical operation might support such a desire? Multiplication should work. 🙂 Pure reflection can be represented as multiply-by-one, pure absorption can be represented as multiply-by-zero.
At this point, in a math class, you’d do that work. Here, I’ll just give you the answer.

For all that “math talk”, this doesn’t feel very intimidating anymore, does it? The reflection signature is high for low-wavelength photons, and low for high-wavelength light. For a very generous light source, we would expect to see the signature in the perception.
Another neat thing about this signature: it is rooted in properties of the object atomic structure! Once we know it, you can play with your light source all day: the reflection signature won’t change. Further, if you combine this mathematical object with the light source spectrum, you produce a prediction machine – a device capable of anticipating futures. Let’s see our prediction machine in action.
And The Answer Is…
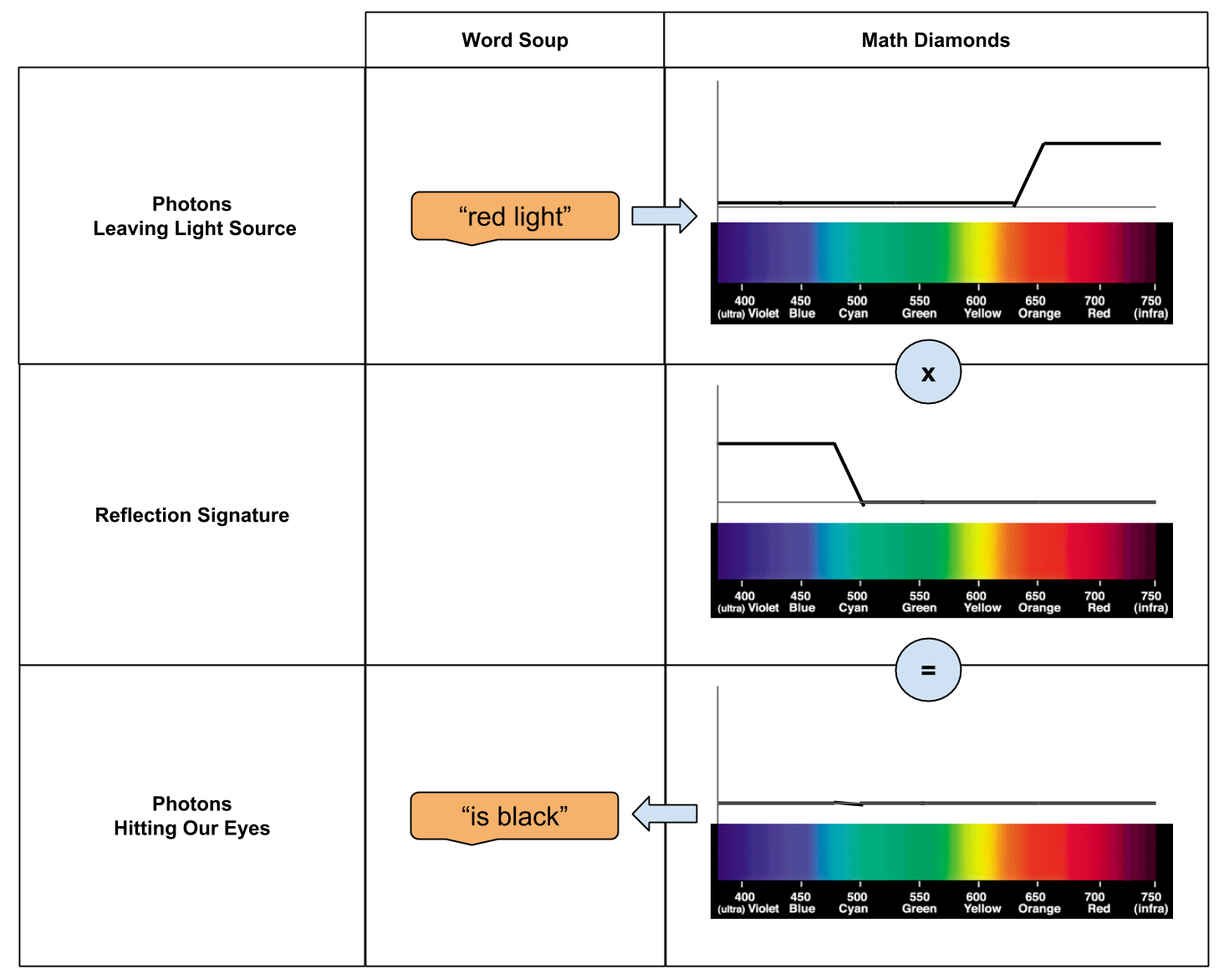
How would O appear, if it is placed under a red light?
We have all of the tools we need:
- We know how to cast “red light” into an emissions spectra.
- We have already built a reflection signature, which is unique to the object O.
- We know how to multiply spectra.
- We have an intuition of how to translate spectra into color.
The solution, then, takes a clockwise path:

The puzzle, again:
We see an object O. Under white light, O appears blue. How would O appear, if it is placed under a red light?
Our answer:
O would appear black.
Takeaways
At the beginning of this article, your response to this question was most likely “I’d have to try it to find out”.
To move beyond this, I installed three requisite ideas:
- A cursory sketch of the nature of photons (massless bosons),
- Intromission theory (photons enter the retinae),
- The language of spectra (map of possible photon wavelengths)
With these mindware applets installed, we learned how to:
- Crystallize the problem by casting English descriptions into spectra.
- Discover a hidden variable (object spectrum) and solve for it.
- Build a prediction machine, that we might predict phenomena never before seen.
With these competencies, we were able to solve our puzzle.