
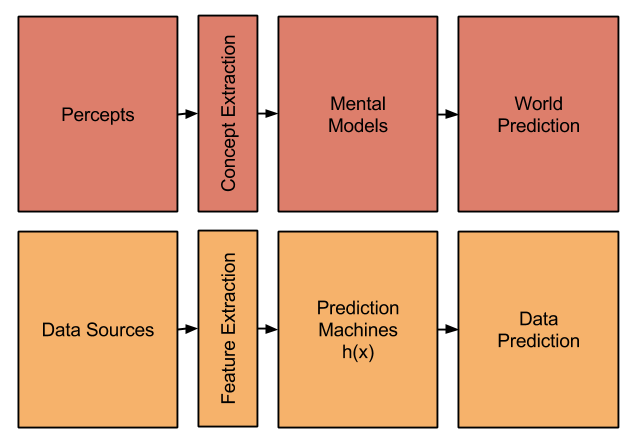
This series discusses a startling, and some would say anti-democratic, idea: hiding data from ourselves may be an effective way to move faster than science.
This sequence is composed of four articles.
- About A Noise. Discusses the origins of noise within data.
- Data Partitioning: Bias vs Variance. Covers a core idea in the machine learning community: building fences around data sources protects machines from underestimating noise.
- Overfitting: Failure Mode of Meat Science. Surveys evidence of overfitting within human scientific communities (“meat science”). Connects to philosophy of science, and motivates the application of data partitioning into the human realm.
- [Planned] Reconstructing The Shoulders Of Giants. A look at what data partitioning would look like in practice, including how I am applying it on this blog.
