
Part Of: Bayesianism sequence
See Also: [Excerpt] Fermi Estimates
Content Summary: 1500 words, 15 min read, 15 min exercise (optional)
The most important questions of life are indeed, for the most part, really only problems of probability.
Pierre Simon Laplace, 1812
Accessing One’s Own Predictive Machinery
Any analyst can describe the unnerving intimacy one develops while acclimating to a dataset. With data visualizations, we acclimate ourselves to the contours of the Manifold of Interest, one slice at a time. Human beings simply become more incisive, powerful thinkers when we choose to put aside the rhetoric and reason directly with quantitative data.
The Bayesian approach interprets learning as a plausibility calculus, where new data pays down uncertainty. What is uncertainty? Uncertainty is how “loosely held” our beliefs are. The more data we have, the less uncertain we must be, and the sharper the peaks in our belief distribution.
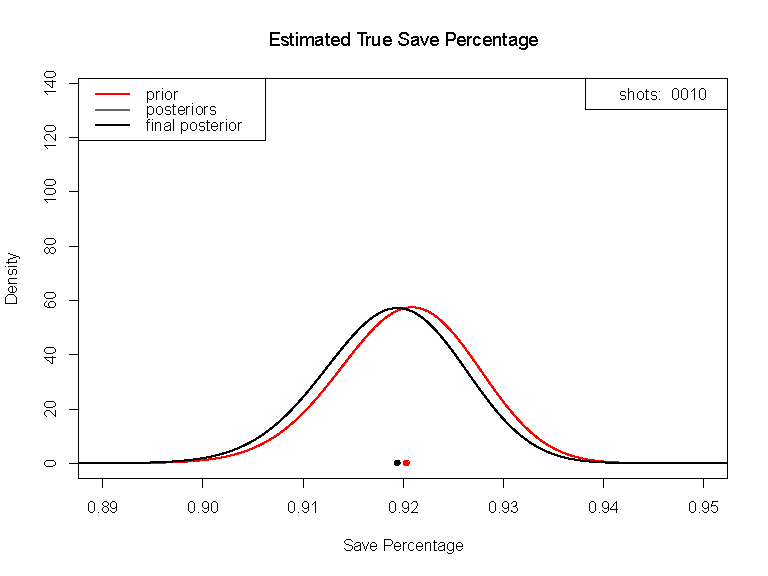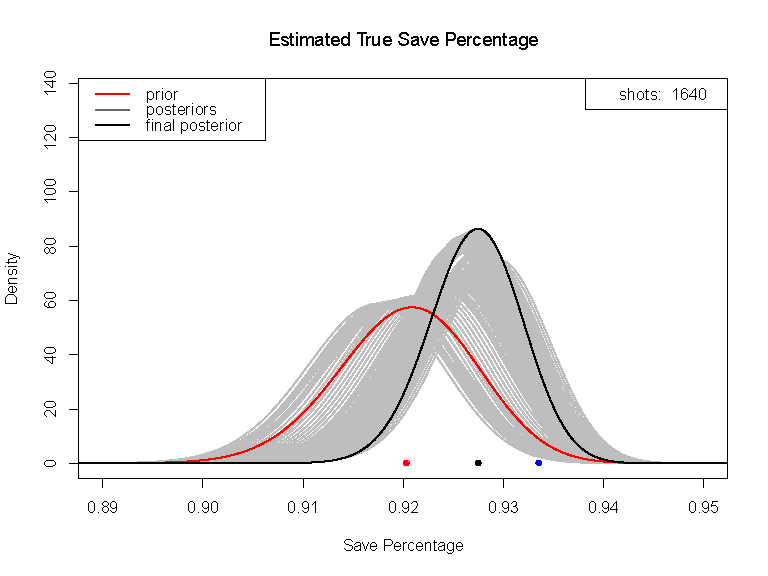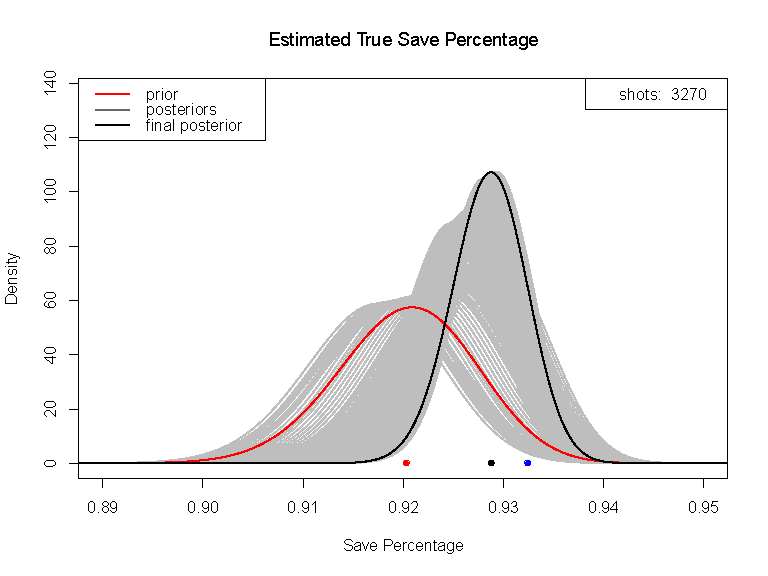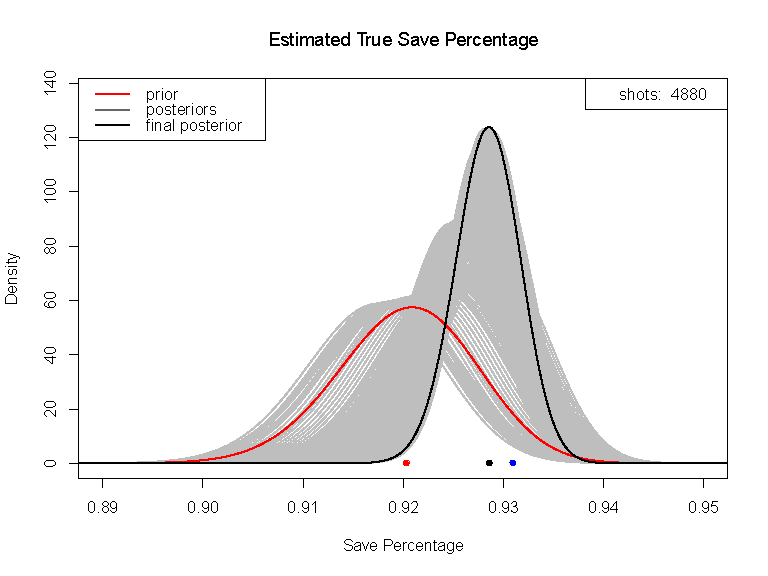
The Bayesian approach affirms silicon and nervous tissue conform to the same principles. Machines learn from digital data, our brains do the same with perceptual data. The chamber of consciousness is small. Yet, could there be a way to directly tap into the sophisticated inference systems within our subconscious mind?
Quantifying Error Bars
How many hours per week do employees spend in meetings? Even if you don’t know the exact values to questions like these, you still know something. You know that some values would be impossible or at least highly unlikely. Getting clear on what you already know is an absolutely crucial skill to develop as a thinker. To do that, we need to find a way to accurately report our own uncertainty.
One method to report our uncertainty is to use words of estimative probability.
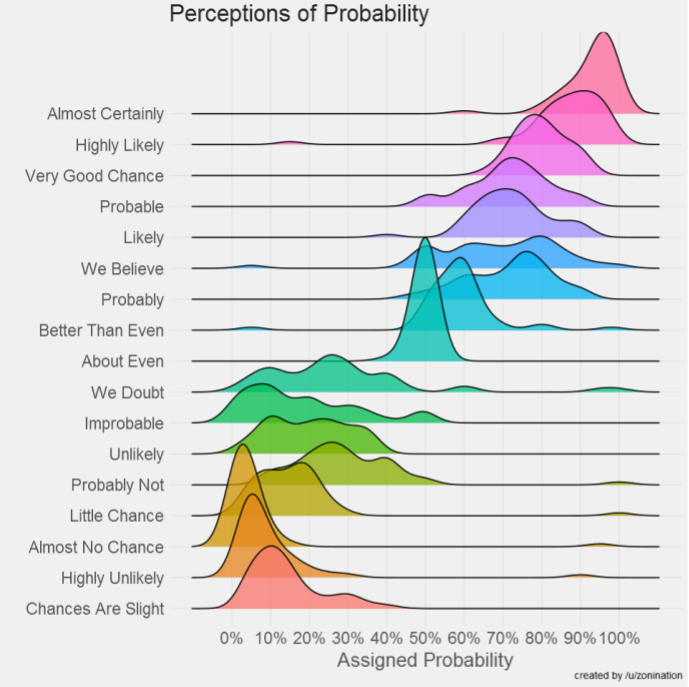
But these words are crude tools. A more sophisticated approach is to express uncertainty about a number is to think of it as a range of probable values. In statistics, a range that has a particular chance of containing the correct answer is called a confidence interval (CI). A 90% CI is a range that has a 90% chance of containing the correct answer. For example, if you are 90% sure the average number of hours spent in meetings is between 6 and 15 hours, then we can say you have a 90% CI [6, 15]. You might have produced this range with sophisticated statistical inference methods, but you might have just picked them out from your experience. Either way, the values should be a reflection of your uncertainty about this quantity.
When you say “I am 70% sure of X”, how do you know your stated uncertainty is correct? Suppose you make 10 such predictions. A calibrated estimator should get about 7 out of 10 predictions correct. An overconfident estimator will get less than 7 answers right (they knew less than they thought). An unconfident estimator will get more than 7 answers correct (they knew more than they thought). You can be a better thinker if you learn to balance the scales between under- and over-confidence.
Unfortunately, extensive research has shown that most people are systematically overconfident. For example, here are the results from 972 estimation tests for 90% CI intervals. If people were naturally calibrated, the number of correct responses would most typically be 9/10; but in practice the actual mean is roughly 5.5.

Here’s a real life example of overconfidence: overly narrow error bars in expert forecasts of US COVID-19 case load.
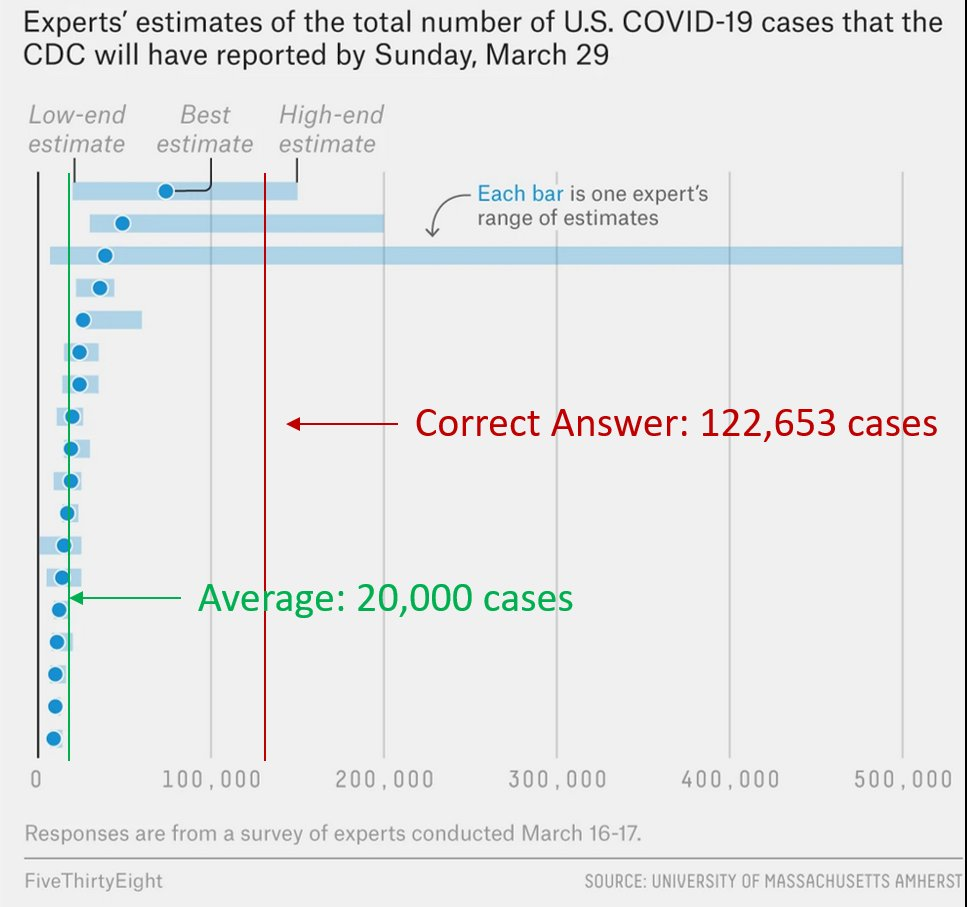
From a psychological perspective, our ignorance of our state of knowledge is not a particularly surprising fact. All animals are metacognitively incompetent – we are truly strangers to ourselves. Our biasing towards overconfidence is easily explained by the argumentative theory of reasoning, and closely aligns with the Dunning-Kruger effect.
Bad news so far. However, with practice and some debiasing techniques, people can become much more reliably calibrated estimators. Consider the premise of superforecasting:
In Superforecasting, Tetlock and coauthor Dan Gardner offer a masterwork on prediction, drawing on decades of research and the results of a massive, government-funded forecasting tournament. The Good Judgment Project involves tens of thousands of ordinary people—including a Brooklyn filmmaker, a retired pipe installer, and a former ballroom dancer—who set out to forecast global events. Some of the volunteers have turned out to be astonishingly good. They’ve beaten other benchmarks, competitors, and prediction markets. They’ve even beaten the collective judgment of intelligence analysts with access to classified information. They are “superforecasters.”
Calibration is a foundational skill in the art of rationality. And it can be taught.
Try It Yourself
Like other skills, calibration emerges through practice. Let’s try it out!
Instructions:
- 90% CI. For each of the 90% CI questions, provide both an upper bound and a lower bound. Remember that the range should be wide enough that you believe there is a 90% chance that the answer will be between the bounds.
- Binary Questions. Answer whether each of the statements is true or false, then circle the probability that reflects how confident you are in your answer. If you are absolutely certain in your answer, you should say you have a 100% chance of getting the answer right. If you have no idea whatsoever, then your chance would be the same as a coin flip (50%). Otherwise (probably usually), it is one of the values between 50% and 100%.
Alright, good luck! 🙂
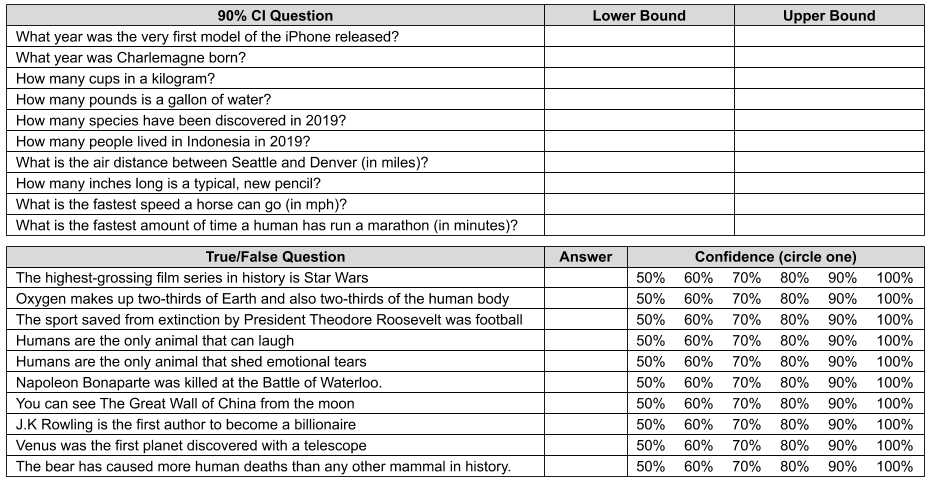
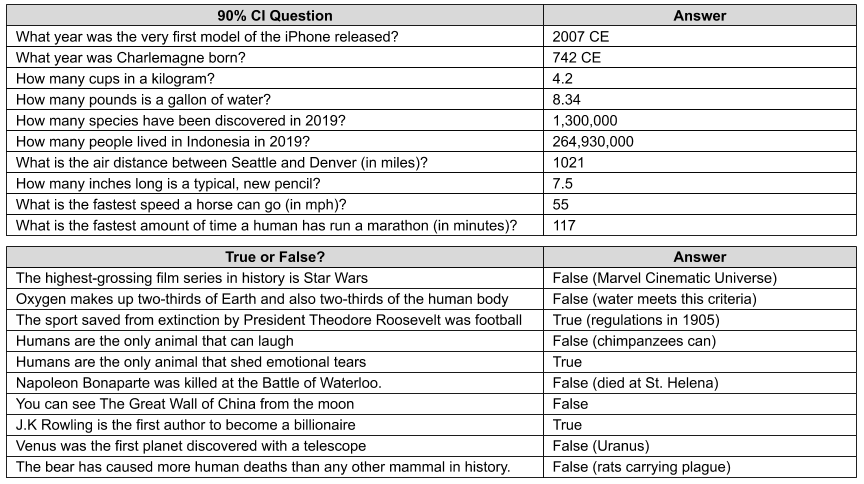
To evaluate your results, the answer key is an image at the end of this article. Go ahead and count how many answers you got correct.
- 90% CI. If you were fully calibrated, then you should have gotten 9 out of 10 answers right. Your test performance can be interpreted like this: if you got 7 to 10 within your range, you might be calibrated; if you got 6 right, you are very likely to be overconfident; if you got 5 or less right, you are almost certainly overconfident and by a large margin.
- Binary Questions. To compute the expected outcome, convert each of the percentages you circled to a decimal (i.e., .5, .6, … 1.0) and add them up. Let’s say your confidence in your answers was 0.5, 0.7, 0.6, 1, 1, 0.8, 0.5, 0.6, 0.5, 0.7, totaling to 6.9. This means your “expected” number is 6.9. For tests with 20 binary questions, most participants should get the expected score to within 2.5 points of the actual score.
Calibration Training is Possible
There are five tactics used to improve one’s calibration, in practice. We will discuss the most significant tactic first, in order of descending efficacy.
First, the most important thing we can do to improve is practice, and going over one’s mistakes. This simple advice has deep roots in global workspace theory, where the primary function of consciousness is to serve as a learning device. As I wrote elsewhere:
Consider the radical simplicity of the act of learning itself. To learn anything new, we merely pay attention to it, and thereby become conscious of it.
For a public example of self-evaluation, see SlateStarCodex annual predictions and his calibration scores. If you would like to practice against more of these general trivia tests, three are provided in the book which inspired this article, How to Measure Anything.
Second, a particularly powerful tactic for becoming more calibrated is to pretend to bet money.
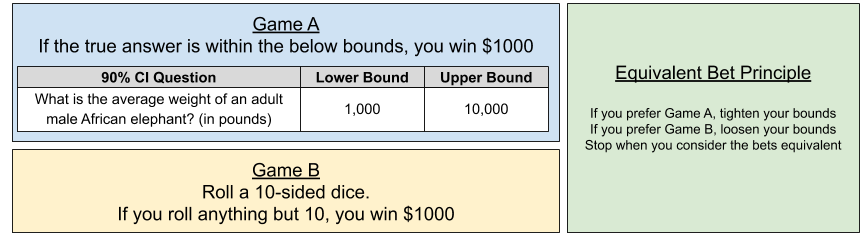
Consider another 90% CI question: what is the average weight in tons of an adult male African elephant? As you did before, provide an upper and lower bound that are far apart enough that you think there is a 90% chance the true answer is between them. Now consider the two following games:
- Game A. You win $1000 if the true answer turns out to be between your upper and lower bound. If not, you win nothing.
- Game B: You roll a 10-sided die. If the die lands on anything but 10, you win $1000. Else you win nothing.
80% of subjects prefer Game B. This means that their “90% CI” is actually too narrow (they are unconsciously overconfident).
Give yourself a choice between betting on your answer being correct or rolling the dice. I call this the equivalent bet test. Research indicates that even just pretending to bet money significantly improves a person’s ability to assess odds (Kahneman & Tversky, 1972, 1973). In fact, actually betting money turns out to be only slightly better than pretending to bet.
Third, people apply sophisticated evaluation techniques to evaluate the claims of other people. These faculties are typically not employed for the stuff coming out of our mouth. But there is a simple technique to promote this behavior: the premortem. Imagine you got a question wrong, and on this hypothetical scenario, ask yourself why you got it wrong. This technique has also been shown to significantly improve your performance (Koriat et al 2012).
Fourth, it’s worth noting that the anchoring heuristic can contaminate bound estimation (an example of anchoring might be, if I ask you whether Gandhi died at 120 year old, your estimate will be likely older than if I had not provided the anchor). In order not to be unduly influenced by your initial guess, it can help to determine bounds separately. Instead of asking yourself “Is there a 90% chance the answer is between LB and UB”, ask yourself “Is there a 95% chance the answer is below (above) my LB (UB)”?
Fifth, rather than approaching estimately by generating guesses, it can sometimes help to instead eliminate answers that seem absurd. Rather than guess 5,000 pounds for the elephant, explore what weights you consider absurd.

In practice, these techniques are fairly effective at improving calibration in people. Here are the results of Hubbard’s half-day of training (n=972); as you can see most people did achieve nearly perfect calibration within half a day.
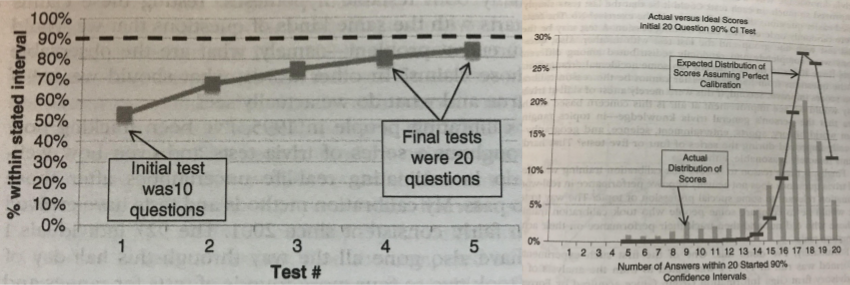
All of this training was done on general trivia. Does calibrative skill generalize to other domains? There is not much research on this question, but provisionally speaking – generalization seems plausible. Individual forecasters who completed calibration training had their job performance measured and they saw improvements to their job performance.
Until next time.
Quiz Answer Key
References
- Kahneman & Tversky (1972) Subjective Probability: A judgment of representativeness.
- Kahneman & Tversky (1973) On the psychology of prediction
- Koriat et al (1980). Reasons for confidence
