
Part Of: Causality sequence
See Also: Potential Outcomes model
Content Summary: 2300 words, 23 min read
Counterfactuals and the Control Group
If businesses were affected by one factor at a time, the notion of a control group would be unnecessary: just intervene and see what changes. But in real life, many causal factors can influence an outcome.
Consider click-through rates (CTR) for a website’s promotional campaign. Suppose we want to know how a website redesign will affect CTR. One naive approach would be to simply compare click-through rates before and after the change is deployed. However, even if the CTR did change, there are plenty of potential confounds: other processes that may better explain the change.
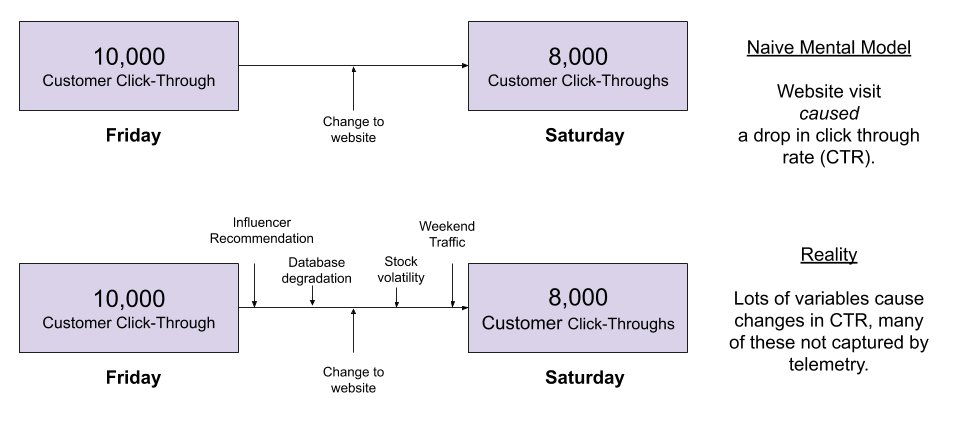
Can we conclude the website decreased click-throughs by 2,000? Only if the other causal factors driving CTR were fixed. Call this assertion ceteris paribus: other things being equal.
In practice, can we safely assert nothing else changed from Friday to Saturday? By no means! We have taken no action to ensure these factors are fixed, and the number of wrenches can be thrown at us.
The trick is to create an environment where other causal factors are held constant. The control group is the experimental group, except for the causal factor under investigation. So we create two servers, and ensure the product and its consumers are as similar as possible.
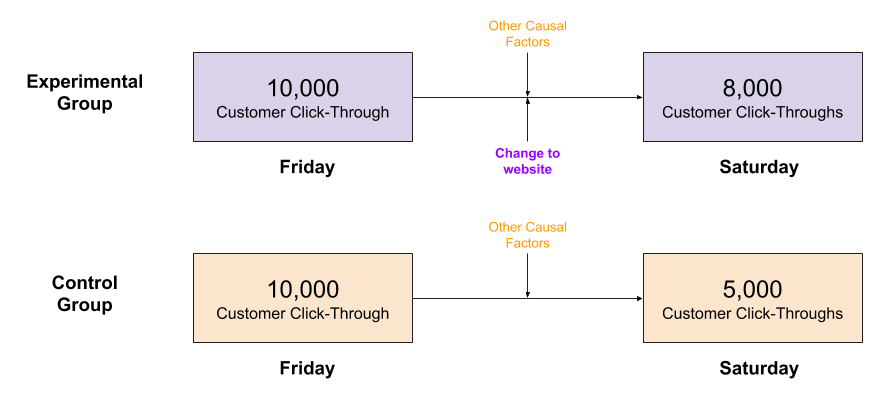
So long as the two groups are in fact similar, if the (sometimes unmeasured) causal forces are equivalent, then we can safely make a causal conclusion. From this data, we might conclude that the website helped, despite the drop in CTR.
It is imperative that the experimental group must be as similar to the control group as possible. If the control group outcome was measured on a different day, the weekend effect would disappear.
To recap, how would things be different, if something else had occurred? Such counterfactual questions capture something important about causality. But we cannot access such parallel universes. The best you can do is create “clones” (maximally similar groups) in this universe. Counterfactuals are replaced with ceteris paribus; clones with the control group.

The Problem of Selection Bias
The above argument was qualitative. To get more clear on randomized control trial (RCT), it helps to formalize the argument.
Consider two individuals: hearty Alice and frail Bob. We want to know whether or not some drug improves their health.
Alice is assigned to the control group, Bob the treatment group. Despite taking the drug, Bob has a worse health outcome than Alice. While the treatment group is performing worse than the control group, this is not due to drug inefficacy. Rather, the difference in outcome is caused by difference in group demographics.
Let’s formalize this example. In Potential Outcome Models, we can represent whether or not she had the drug as 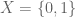


For each person, the individual causal effect (ICE) of health insurance is:


But these potential outcomes are fundamentally unobservable. The only observation we can make is:

Taken at face value, this suggests that Bob’s decision to accept health insurance is counterproductive. But this conclusion is erroneous. We can express this mathematically with the following device:

In other words,
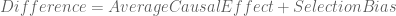
Different outcomes between experimental and control groups is a combination of the causal effect of the treatment, and the differences among groups before the treatment is applied. To isolate the causal effect, you must minimize selection bias.
Randomization versus Selection Bias
Group differences contaminate causal analyses. How often is observational data contaminated in this way?
Quite often. For example, here are a few comparisons between those who have health insurance versus those who do not. People with health insurance are 2.71 years older, have 2.74 more years of education, are 7% more likely to be employed, and have an annual income of $60,000 more. With so many large differences in our data, we should suspect other differences in unobserved dimensions, too.
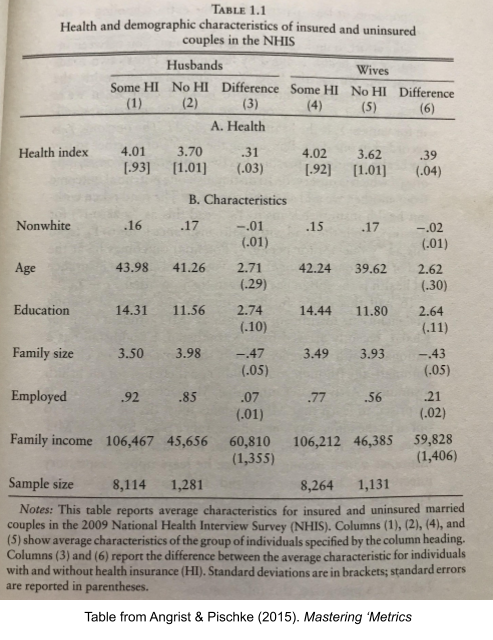
To minimize selection bias, we need our groups to be as similar as possible. We need to compare apples to apples.
Random allocation is a good way to promote between-group homogeneity, before the causal intervention. We can demonstrate this statistically. Let’s say that the causal effect of a treatment is the same across individuals, 
![E_{treatment}[Y_{1,i}] - E_{control}[Y_{0,i}]](https://s0.wp.com/latex.php?latex=E_%7Btreatment%7D%5BY_%7B1%2Ci%7D%5D+-+E_%7Bcontrol%7D%5BY_%7B0%2Ci%7D%5D&bg=ffffff&fg=555555&s=0&c=20201002)
![= E_{treatment}[\kappa + Y_{0,i}] - E_{control}[Y_{0,i}]](https://s0.wp.com/latex.php?latex=%3D+E_%7Btreatment%7D%5B%5Ckappa+%2B+Y_%7B0%2Ci%7D%5D+-+E_%7Bcontrol%7D%5BY_%7B0%2Ci%7D%5D&bg=ffffff&fg=555555&s=0&c=20201002)
![= \kappa + E_{treatment}[Y_{0,i}] - E_{control}[Y_{0,i}]](https://s0.wp.com/latex.php?latex=%3D+%5Ckappa+%2B+E_%7Btreatment%7D%5BY_%7B0%2Ci%7D%5D+-+E_%7Bcontrol%7D%5BY_%7B0%2Ci%7D%5D&bg=ffffff&fg=555555&s=0&c=20201002)
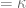
Consider, for example, the Health Insurance Experiment undertaken by RAND. They randomly divided their sample into four 1000-person groups: a catastrophic plan with essentially zero insurance, and then three treatment groups with variations of different forms of health insurance.
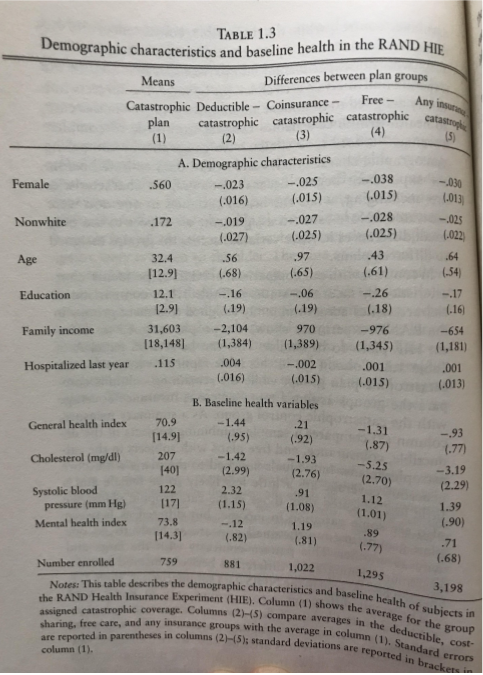
The left column shows means for each attribute (e.g. 56% of the catastrophic group are female). Other columns represent differences between the various treatment groups and control (e.g. 56-2 = 54% of the deductible group are female). How do we know if random allocation succeeded? We simply compare the group differences with standard error: if group difference is more than 2x greater than standard error, the difference is statistically significant.
In these data, only two group differences are statistically significant, and the differences don’t seem to follow obvious patterns, so we can conclude that random allocation appears to have executed successfully. But it’s worth underscoring that we didn’t perform randomization and then walk away, rather we empirically validate our group composition is homogenous.
(For those wondering, RCT studies like this consistently reveal that health insurance improves financial outcomes, but not health outcomes, for the poor. In general, medicine correlates weakly with health. On the aggregate, US consumes 50% more medical services than we need.)
This post doesn’t address null hypothesis significance testing (NHST) which is an analysis technology frequently paired with RCT methodology. There are also extensions of NHST such as factorial designs and repeated measures (within-subject tests) which merit future discussion.
External vs Internal Validity
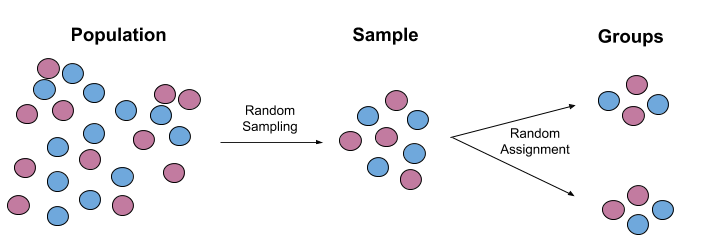
Randomness is a proven way to minimize selection bias. It occurs in two stages:
- Random sampling mitigates sampling bias, thereby ensuring the study results inferences generalize to the broader population. By the law of large numbers (LLN), with sufficiently large samples, the distribution of the sample is guaranteed to approach that of the population. Random sampling promotes external validity.
- Random allocation mitigates selection bias, thereby ensuring that the groups have a comparable baseline. We can then safely access a causal interpretation of the study results. Random allocation promotes internal validity.
RCTs were pioneered in the field of medicine. How do you test if a drug works? You might consider simply giving the pill to treatment subjects. But human beings are complicated. We often manifest the placebo effect, where even an empty pill can produce real physiological relief in the body. There is much debate how the mere expectation of health can produce health; recent research points to the top-down control signals containing the predictions of your body’s autonomic nervous system.
Remember our guiding principle: To minimize selection bias, we need our groups to be as similar as possible. If you want to isolate the medicinal properties of a drug, you need both groups to believe they are being treated. Giving the control group sugar-water pills is an example of blinding: your group similarity increases if subjects can’t see what group they are in.
Blinding can mitigate our psychological penchant for letting expectations structure our experience in other domains too. Experimenters may unconsciously measure trial outcomes differently if they are financially vested in the outcome (detection bias). The most careful RCTs are double-blind trials: both experimenters and participants are ignorant of their group status for the duration of the trial.
There are other complications to bear in mind:
- The Hawthorne effect: people behave differently if they are aware of being watched
- Meta-analyses have revealed high levels of unblinding in pharmacological trials.
- Often patients will fail to comply with experimental protocol. Compliance issues may not occur at random, effectively violating ceteris paribus.
- Often patients will drop out from the study. Just as before, attrition issues may not occur at random, effectively violating ceteris paribus.
How do you deal with noncompliance and attrition?
- Intention to treat studies will leave them in the analysis: more external validity, less internal validity
- Per protocol studies will exclude them from the analysis: less statistical power, more internal validity.
RCTs in Medical History
The field of medicine is a story of learning to trust experimental results over the opinions of the knowledgeable. Here’s an excerpt from Tetlock’s Superforecasting.
Consider Galen, the second-century physician to Roman emperors. No one has influenced more generations of physicians. Glaen’s writings were the indisputable source of medical authority for more than a thousand years. “It is I, and I alone, who has revealed the true path to medicine,” Galen wrote with his usual modesty. And yeti Galen never conducted anything resembling a modern experiment. Why should he? Experiments are what people do when they aren’t sure what the truth is. And Galen was untroubled by doubt. Each outcome confirmed he was right, no matter how equivocal the evidence might look to someone less wise than the master. “All who drink of this treatment recover in a short time, except those whom it does not help, who all die,” he wrote. “It is obvious, therefore, that it fails only in incurable cases.”
Galen is the sort of figure who pops up repeatedly in the history of medicine. They are men of strong conviction and a profound trust in their own judgment. They embrace treatments, develop bold theories for why they work, denounce rivals as quacks and charlatans, and spread their insights with evangelical passion. So it went from the ancient Greeks to Galen to Paracelsus to the German Samuel Hahnemann and the American Benjamin Rush. In the nineteenth century, American medicine saw pitched battles between orthodox physicians and a host of charismatic figures with curious new theories like Thomsonianism, which posited that most illness was due to an excess of cold in the body. Fringe or mainstream, almost all of it was wrong, with the treatments on offer ranging from the frivolous to the dangerous. Ignorance and confidence remained defining features of medicine. As the surgeon and historian Ira Rutkow observed, physicians who furiously debated the merits of various treatments and theories were like blind men arguing over the colors of the rainbow.”
Not until the twentieth century did the idea of RCTs, careful measurement, and statistical inference take hold. “Is the application of the numerical method to medicine a trivial and time-wasting idea as some hold, or is it an important stage in the development of our art, as others proclaim it”, the Lancet asked in 1921.
Unfortunately, this story doesn’t end with physicians suddenly realizing the virtues of doubt and rigor. The idea of RCTs was painfully slow to catch on and it was only after World War II that the first serious trials were attempted. They delivered excellent results. But still the physicians and scientists who promoted the modernization of medicine routinely found that the medical establishment wasn’t interested, or was even hostile to their efforts.
When hospitals created cardiac care units to treat patients recovering from heart attacks, Cochrane proposed an RCT to determine whether the new units delivered better results than the old treatment, which was to send the patients home for monitoring and bed rest. Physicians balked. It was obvious the cardiac care units were superior, they said, and denying patients the best care would be unethical. But Cochrane persisted in running a trial. Partway through the trial, Cochrane told a group of cardiologists preliminary results. The difference in outcomes between the two treatments was not statistically significant, he emphasized, but it appeared that patients might do slightly better in the cardiac care units. They were vociferous in their abuse: “Archie,” they said, “we always thought you were unethical. You must stop the trial at once.” But then Cochrane revealed that he had reversed the results: home care had done slightly better than the cardiac units. There was dead silence, and a palpable sense of nausea.
Today, evidence-based medicine (EBM) rightly privileges RCTs as more authoritative than expert opinion. This movement has put forward a hierarchy of evidence, to gesture at which sources of evidence to take lightly.
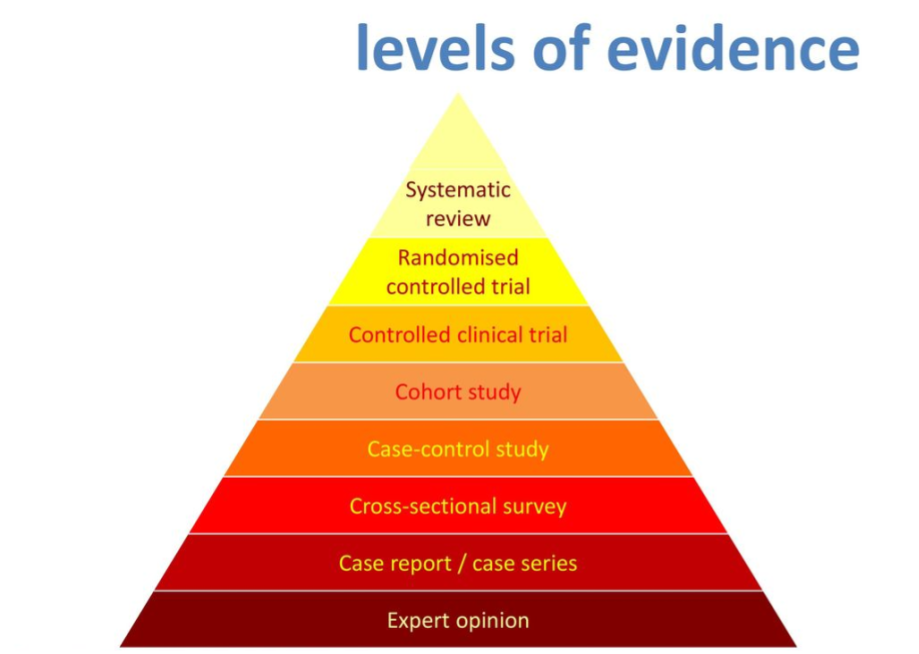
I personally deny that evidence-based medicine is the best approach to evidence. It gets confused by how to interpret “absence of evidence”, as we have seen in the Covid-19 debate on mask efficacy. Yet EBM is undeniably a big improvement from the epistemic learned helplessness that was ancient medicine.
Limitations & Prospects
Everyone agrees that RCTs are the gold standard at drawing conclusions about cause and effect. It is worth seriously considering whether RCTs can be effectively deployed to answer questions besides medicine. Can we use RCTs to get better at policy making? Charity? Managerial science?
There are several important criticisms of RCTs that are worth mentioning:
- Ecological Sterility. The more rigorously you attempt to enforce ceteris paribus, the less your laboratory environment resembles the real world.
- Ethical Limitations of Scope. RCTs were never employed to test whether smoking causes cancer, because it is unethical to force someone to smoke.
- Expense. Pharmacological RCTs cost $12 million dollars to implement, on average.
- Statistical Power. Because of their expense, sample sizes for RCTs are often much lower than observational studies.
RCTs are the gold standard for causal inference, but they are not the only product on the market. As we will see later, there are other technologies in the Furious Five toolbox, which statistics and econometrics use to learn causal relationships. These are,
- Random Controlled Trials (RCTs)
- Regression
- Instrumental Variables
- Regression Discontinuity
- Differences-in-Differences
Until next time.
