
Part Of: Language sequence
Content Summary: 1500 words, 15 min read
Why Language Models?
In the English language, ‘e’ appears more frequently than ‘z’. Similarly, “the” occurs more frequently than “octopus”. By examining large volumes of text, we can learn the probability distributions of characters and words.
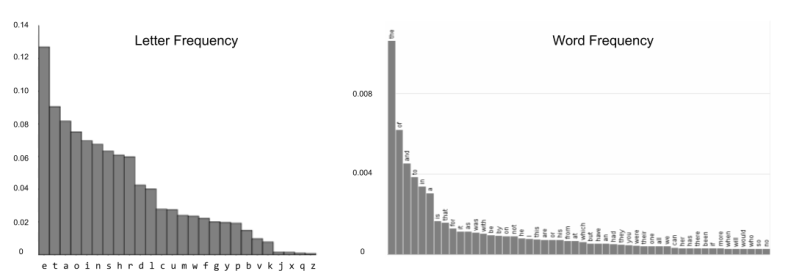
Roughly speaking, statistical structure is distance from maximal entropy. The fact that the above distributions are non-uniform means that English is internally recoverable: if noise corrupts part of a message, the surrounding can be used to recover the original signal. Statistical structure is also used to reverse engineer secret codes such as the Roman cipher.
We can illustrate the predictability of English by generating text based on the above probability distributions. As you factor in more of the surrounding context, the utterances begin to sound less alien, and more like natural language.

A language model exploits the statistical structure of a language to express the following:
- Assign a probability to a sentence
- Assign probability of an upcoming word


Language models are particularly useful in language perception, because they can help interpret ambiguous utterances. Three such applications might be,
- Machine Translation:
- Spelling correction:
- Speech Recognition:



Language models can also aid in language production. One example of this is autocomplete-based typing assistants, commonly displayed within text messaging applications.
Towards N-Grams
A sentence is a sequence of words 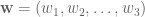


As the number of words grows, the size of our conditional probability tables (CPTs) quickly becomes intractable. What is to be done? Well, recall the Markov assumption we introduced in Markov chains.

The Markov assumption constrains the size of our CPTs. However, sometimes we want to condition on more (or less!) than just one previous word. Let 
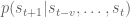

We have already discussed Markov Decision Processes, used in reinforcement learning applications. We haven’t yet discussed MRFs and HMMs. VOMs represent a fourth extension: the formalization of N-grams. Hopefully you are starting to appreciate the richness of this “formalism family”. 🙂
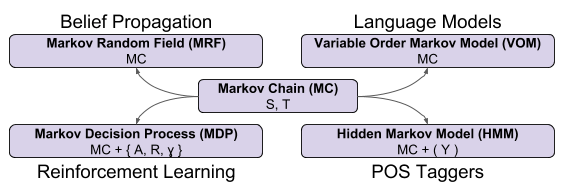
Estimation and Generation
How can we estimate these probabilities? By counting!

Let’s consider a simple bigram language model. Imagine training on this corpus:
This is the cheese.
That lay in the house that Alice built.
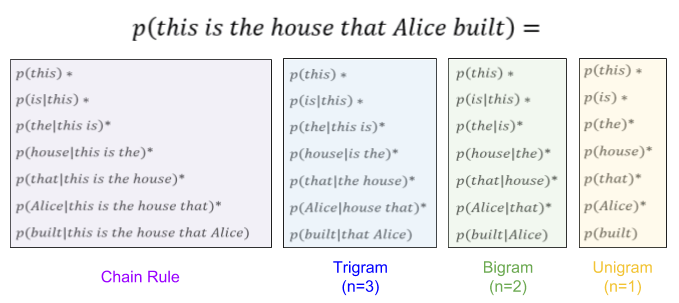
Suppose our trained LM encounters the new sentence “this is the house”. It estimates its probability as:


How many problems do you see with this model? Let me discuss two.
First, we have estimated that 
Second, recall what happens when language models generate speech. Once they begin a sentence, they are unable to end it! Adding a new END token will allow our model the terminate a sentence, and begin a new one.
With these new tokens in hand, we update our products as follows:
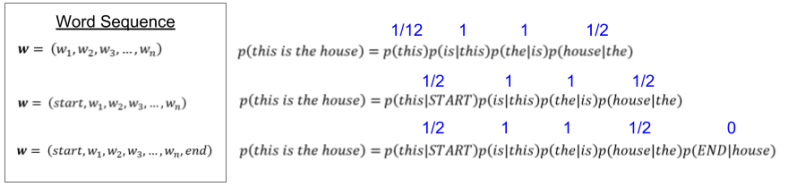
A couple other “bug fixes” I’ll mention in passing:
- Out-of-vocabulary words are given zero probability. It helps to add an unknown (UNK) pseudoword and assign it some probability mass.
- LMs prefer very short sentences (sequential multiplication is monotonic decreasing). We can address this e.g., normalizing by sentence length.
Smoothing
In the last sentence in the image above, we estimate 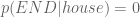
This problem of zero probability increases as we increase the complexity of our N-grams. Trigram models are more accurate than bigrams, but produce more 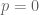
How can we remove zero counts? Why not add one to every word? Of course, we’d then need to increase the size of our denominator, to ensure the probabilities still sum to one. This is Laplace smoothing.

In a later post, we will explore how (in a Bayesian framework) such smoothing algorithms can be interpreted as a form of regularization (MAP vs MLE).
Due to its simplicity, Laplace smoothing is well-known But several algorithms achieve better performance. How do they approach smoothing?
Recall that a zero count event in an 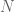

While a trigram model may balk at the above sentence, we can fall back on the bigram and/or unigram models. This technique underlies the Stupid Backoff algorithm.
As another variant on this theme, some smoothing algorithms train multiple
Beam Search
We have so far seen examples of language perception, which assigns probabilities to text. Let us consider language perception, which generates text from the probabilistic model. Consider machine translation. For a French sentence 
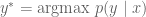
This seemingly innocent expression conceals a truly monstrous search space. Deterministic search has us examine every possible English sentence. For a vocabulary size 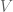


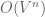
Since deterministic search is so costly, we might consider greedy search instead. Consider an example French sentence
: Jane is visiting Africa in September
: Jane is going to Africa in September
: In September, Jane went to Africa
Of these, 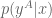
Greedy search generates the English translation, one word at a time. If “Jane” is the most probable first word 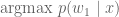
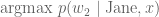
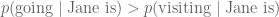
The deterministic search space is too large, and greedy search is too confining. Let’s look for a common ground.
Beam search resembles greedy search in that it generates words sequentially. Whereas greedy search only drills one such path in the search tree, beam search drills a finite number of paths. Consider the following example with beamwidth


As you can see, beam search elects to explore
Strengths and Weaknesses
Language models have three very significant weaknesses.
First, language models are blind to syntax. They don’t even have a concept of nouns vs. verbs! You have to look elsewhere to find representations of pretty much any latent structure discovered by linguistic and psycholinguistic research.
Second, language models are blind to semantics and pragmatics. This is particularly evident in the case of language production: try having your SMS autocomplete write out an entire sentence for you. In the real world, communication is more constrained: we choose the most likely word given the semantic content we wish to express right now.
Third, the Markov assumption is problematic due to long-distance dependencies. Compare the phrase “dog runs” vs “dogs run”. Clearly, the verb suffix depends on the noun suffix (and vice versa). Trigram models are able to capture this dependency. However, if you center-embed prepositional phrases, e.g., “dog/s that live on my street and bark incessantly at night run/s”, N-grams fail to capture this dependency.
Despite these limitations, language models “just work” in a surprising diversity of applications. These models are particularly relevant today because it turns out that Deep Learning sequence models like LSTMs share much in common with VOMs. But that is a story we shall have to take up next time.
Until then.
