Part Of: Demystifying Physics sequence
Prerequisite Post: An Introduction To Energy
Content Summary: 2100 words, 21 min reading time.
Prerequisite Mindware
Today, we’re going to go spelunking into the fabric of the cosmos! But first, some tools to make this a safe journey.
Energy Quanta
As we saw in An Introduction to Energy,
Energy is the hypothesis of a hidden commonality behind every single physical process. There are many forms of energy: kinetic, electric, chemical, gravitational, magnetic, radiant. But these forms are expressions of a single underlying phenomena.
Consider the analogy between { electrons spinning around protons } and { planets spinning around stars }. In the case of planets, the dominant force is gravitational. In the case of the atom, the dominant force is electromagnetic.
But the analogy strength of the above is weak. In contrast to gravitational acceleration, an accelerating electric charge emits electromagnetic waves. Thus, we would expect an orbiting charge to steadily lose energy and spiral into the nucleus, colliding with it in a fraction of a second. Why have atoms not gone extinct?
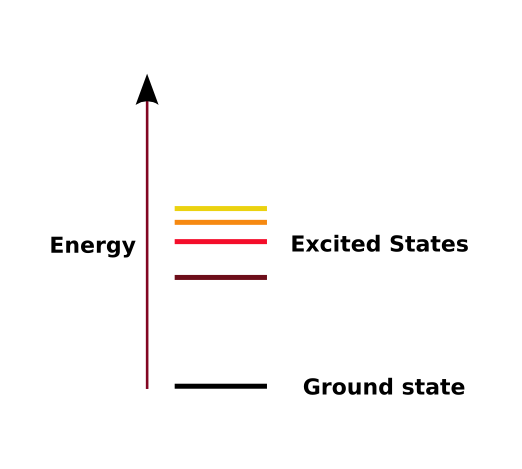
To solve this problem, physicists began to believe that in some situations, energy cannot be lost. Indeed, they abandoned the intuitive idea that energy is continuous. On this new theory, at the atomic level energy must exist in certain levels, and never in between. Further, at one particular energy level, something we will call the ground state, an electron may never lose energy.

Antiparticles
Let’s talk about antiparticles. It’s time to throw out your “science fiction” interpretive lens: antiparticles are very real, and well-understood. In fact, they are exactly the same as normal particles, except charge is reversed. So, for example, an antielectron has the same mass and spin as an electron, but instead carries a positive charge.
Why does the universe contain more particles than antiparticles? Good question. 😛
Meet The Fermions
Nature Up Close
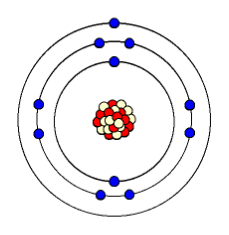
Consider this thing. What would you name it?

One name I wouldn’t select is “indivisible”. But that’s what the “atom” means (from the Greek “ἄτομος”). Could you have predicted the existence of this misnomer?
As I have discussed before, human vision can capture only a small subset of physical reality. Measurement technology is a suite of approaches that exploit translation proxies, the ability to translate extrasensory phenomena into a format amenable to perception. Our eyes cannot perceive atoms, but the scanning tunneling microscope translates atomic structures to scales our nervous systems are equipped to handle.
Let viable translation distance represent the difference in scale between human perceptual foci and the translation proxy target. Since translation proxies are facilitated through measurement technology, which is in turn driven by scientific advances, it follows that we ought to expect viable translation distance to increase over time.
We now possess a straightforward explanation of our misnomer. When “atom” was coined, its referent was the product of that time’s maximum viable translation distance. But technology has since moved on, and we have discovered even smaller elements. Let’s now turn to the state of the art.
Beyond The Atom
Reconsider our diagram of the atom. Do you remember the names of its constituents? That’s right: protons, neutrons, and electrons. Protons and neutrons “stick together” in the nucleus, electrons “circle around”.
Our building blocks of the universe so far: { protons, neutrons, electrons }. By combining these ingredients in all possible ways, we can reconstruct the periodic table – all of chemistry. Our building blocks are – and must be – backwards compatible. But are these particles true “indivisibles”? Can we go smaller?
Consider the behavior of the electrons orbiting the nucleus. After fixing one theoretical problem (c.f., Energy Levels section above), we now can explain why electrons orbit the nucleus: electromagnetic attraction (“opposites attract”). But here is a problem: we have no such explanation for the nucleus. If “like charges repel”, then the nucleus must be something like holding the same poles of a magnet close together: you can do it, but it takes a lot of force. What could possibly be keeping the protons in the nucleus together?
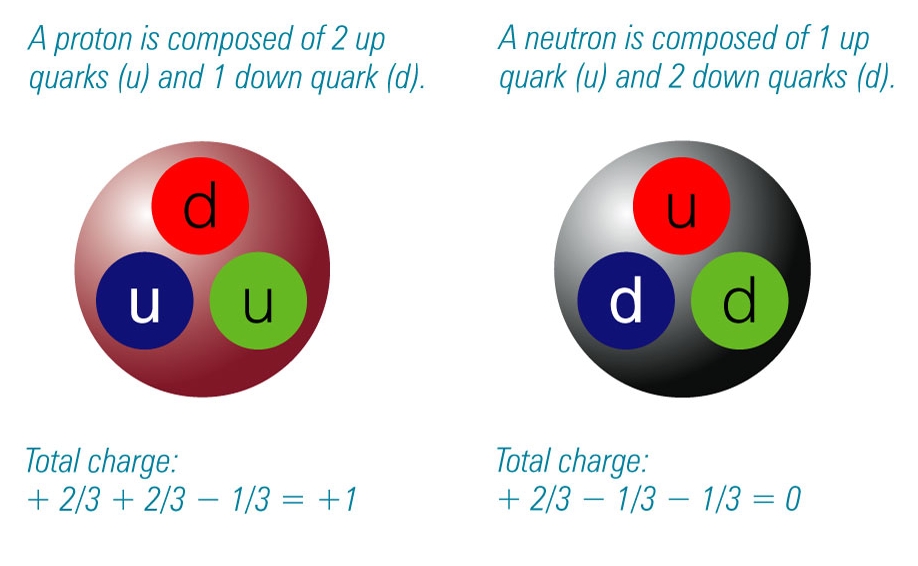
Precisely this question motivated a subsequent discovery: electrons may well be indivisible, but protons and neutrons are not. Protons and neutrons are instead composite particles made out of quarks. Quarks like to glue themselves together by a new force, known as the strong force. This new type of force not only explains why we don’t see quarks by themselves, it also explains the persistence of the nucleus.
The following diagram (source) explains how quarks comprise protons and neutrons:

Okay, so our new set of building blocks are: { electron, up, down }. With a little help from some new mathematics – quantum chromodynamics – we can again reconstitute chemistry. biology, and beyond.
Please notice how some of our building blocks are more similar than others: the up and down particle comprise particles with charge divisible by three, the electron particle carries an integer charge. Let us group like particles together.
- Call up and down particles part of the quark family.
- Call electrons part of the lepton family.
Neutrinos
So far in this article, we’ve gestured towards gravitation and electromagnetism. We’ve also introduced the strong force. Now is the time to discuss Nature’s last muscle group, the weak force.
A simple way to bind the weak force to your experience: consider what you know about radioactive material. The types of atoms that are generated in, to pick one source, nuclear power do not behave like other atoms. They emit radiation, they decay. Ever heard of the “half-life” of a material? That term defines how long is takes for half of an unstable radioactive material to decay into a more stable form. For example, { magnesium-23 → sodium-23 + antielectron }.
Conservation of energy dictates that such decay reactions must preserve energy. However, when you actually calculate the energetic content of decay process given above, you find a mismatch. And so, scientists were confronted with the following dilemma: either reject conservation of energy, or posit the existence of an unknown particle to “balances the books”. Which would you chose?
The scientific community began to speculated that a fourth type of fermion existed, even with an absence of physical evidence. And they found it 26 years later, in 1956.
Why did it take relatively longer to discover this fourth particle? Well, these hypothesized neutrinos do not carry an electric charge or a color charge. As such, they only interact with other particles via the weak force (which has a very short range) and the atomic force (which is 10^36 times less powerful than electromagnetic force). Due to these factors, neutrinos such as those generated by the Sun pass through the Earth undetected. In fact, in the time it takes you to read this sentence, hundreds of billions of neutrinos have passed through every cubic centimeter of your body without incident. Such weak interactivity explains the measurement technology lag.
Are you sufficiently creeped out by how many particles pass through you undetected? 🙂 If not, consider neutrino detectors. Because of their weak interactivity, our neutrino detectors must be large, and buried deep inside the earth (to shield from “noise” – more common particle interactions). Here we see a typical detector, with scientists inspecting their instruments in the center, for contrast:

The Legos Of Nature
Here, then, is our picture of reality:
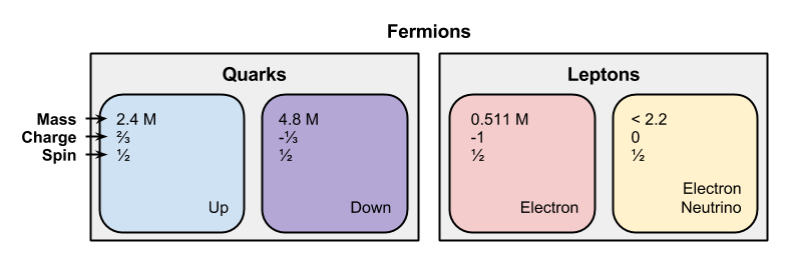
Notice that all fermions have spin ½; we’ll return to this fact later.
A Generational Divide
Conservation of energy is a thing, but conservation of particles is not. Just as particles spontaneously “jump” energy levels, sometimes particles morph into different types of particles, in a way akin to chemical reactions. What would happen if we were to pump a very large amount of energy into the system, say by striking an up quark with a high-energy photon? Must the output energy be expressed as hundreds of up quarks? Or does nature have a way to “more efficiently” spend its energy budget?
It turns out that you can: there exist particles identical to these four fermions with one exception: they are more massive. And we can pull this magic trick once more, and find fermions even heavier than these fermions. To date, physicists have discovered three generations of fermions:
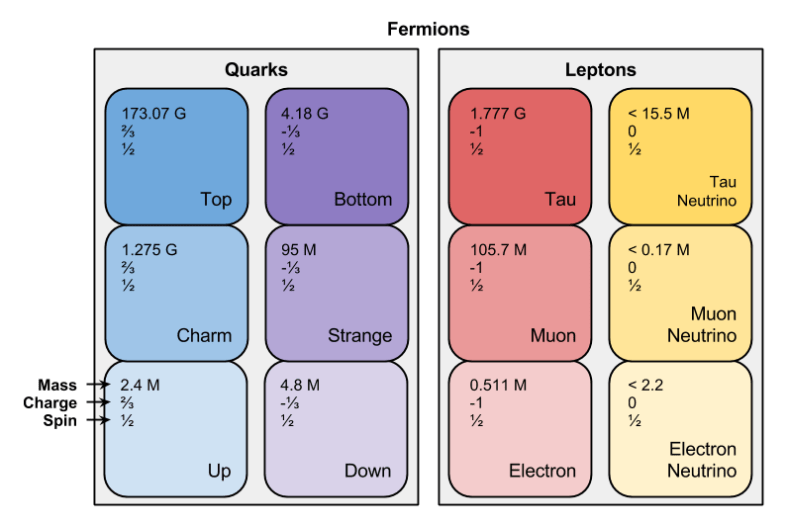
The latter generation took lots of time to “fill in” because you only see them in high-energy situations. Physicists had to close the translation distance gap, by building bigger and bigger particle accelerators. The fermion with the highest mass – the Top quark – was only discovered in 1995. Will there be a fourth generation, will we discover some upper bound on fermion generations?
Good question.
Even though we know of three generations, in practice only the first generation “matters much”. Why? Because the higher-energy particles that comprise the second and third generations tend to be unstable: give them time (fractions of a second, usually), and they will spontaneously decay – via the weak force – back into first generation forms. This is the only reason why we don’t find atomic nuclei orbited by tau particles.
Towards A Mathematical Lens
General & Individual Descriptors
The first phase of my lens-dependent theorybuilding triad I call conceptiation: the art of carving concepts out of a rich dataset. Such carving must be heavily dependent on descriptive dimensions: quantifiable ways that an entity may differ from one another.
For perceptual intake, the number of irreducible dimensions may be very large. However, for particles, this set is surprisingly small. There is something distressingly accurate in the phrase “all particles are the same”.
Each type of fermion is associated with one unique value for the following properties (particle-generic properties):
- mass (m)
- electric charge (e)
- spin (s)
Fermions may differ according to their quantum numbers (particle-specific properties). For an electron, these numbers are:
- principal. This corresponds to the energy level of the electron (c.f., energy level discussion)
- azimuthal. This corresponds to the orbital version of angular momentum (e.g., the Earth rotating around the Sun). These numbers correspond to the orbitals of quantum chemistry (0, 1, 2, 3, 4, …) ⇔ (s, p, d, f, g, …); which helps explain the orbital organization of the periodic table.
- magnetic. This corresponds to the orientation of the orbital.
- spin projection. This corresponds to the “spin” version of angular momentum (e.g., the Earth rotating around its axis). Not to be confused with spin, this value can vary across electrons.
Quantum numbers are not independent; their ranges hinge on one another in the following way:
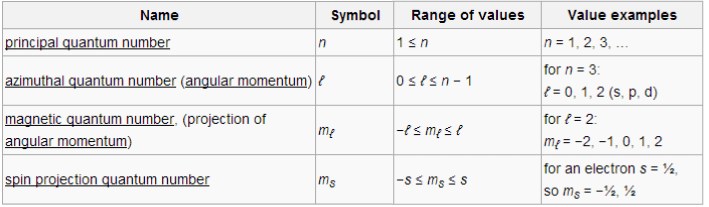
Statistical Basis
With our fourth building block in place, we are in a position to answer the question: what does the particulate basis of matter have in common?
All elementary particles of matter we have seen have spin ½. By the Spin-statistics Theorem, we must associate all such particles with Fermi-Dirac statistics. Let us name all particles under this statistics – all particles we have seen so far – “fermions”. It turns out that this statistical approach generates a very interesting property known as the Pauli Exclusion Principle. The Pauli Exclusion Principle states, roughly, that two particles cannot share the same quantum state.
Let’s take an example: consider a hydrogen atom with two electrons. Give this atom enough time, and both electrons will be on its ground state, n=1. What happens if the hydrogen picks up an extra electron, in some chemical process? Can this third electron also enter the ground state?
No, it cannot. Consider the quantum numbers for our first two electrons: { n=1, l=0, m_l=0, m_s=1/2 } and { n=1, l=0, m_l=0, m_s=-1/2 }. Given the range constraints given above, there are no other unique descriptors for an electron with n=1. Since we cannot have two electrons with the same quantum numbers, the third electron must come to rest at the next highest energy level, n=2.
The Pauli Exclusion Principle has several interesting philosophical implications:
- Philosophically, this means that if two things have the same description, then they cannot be two things. This has interesting parallels to the axiom of choice in ZFC, which accommodates “duplicate” entries in a set by conjuring some arbitrary way to choose between them.
- Practically, the Pauli Exclusion Principle is the only thing keeping your feet from sinking into the floor right now. If that isn’t a compelling demonstration of why math matters, then I don’t know what is.
Composite Fermions
In this post, we have motivated the fermion particulate class by appealing to discoveries of elementary particles. But then, when we stepped back, we discovered that the most fundamental attribute of this class of particles was its subjugation to Fermi-Dirac statistics.
Can composite particles have spin-½ as well as these elementary particles? Yes. While all fermions considered in this post are elementary particles, that does not preclude composite particles from membership.
What Fermions Mean
In this post, we have done nothing less than describe the basis of matter.
But are fermions the final resolution of nature? Our measurement technology continues to march on. Will our ability to “zoom in” fail to produce newer, deeper levels of reality?
Good questions.






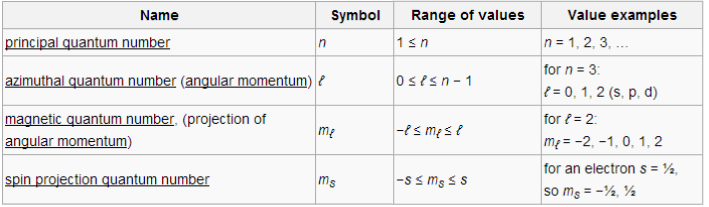

 ? It is justly famous for demonstrating mass-energy interchangeability. If you are set up a situation to facilitate a “trade”, you can purchase energy by selling mass (and vice versa). Not only that, but you can purchase a LOT of energy with very little mass (the ratio is about 90,000,000,000,000,000 to 1). This kind of lopsided interchangeability helps us understand why things like nuclear weapons are theoretically possible. (In nuclear weapons, a small amount of uranium mass is translated into considerable energy). Anyways, given
? It is justly famous for demonstrating mass-energy interchangeability. If you are set up a situation to facilitate a “trade”, you can purchase energy by selling mass (and vice versa). Not only that, but you can purchase a LOT of energy with very little mass (the ratio is about 90,000,000,000,000,000 to 1). This kind of lopsided interchangeability helps us understand why things like nuclear weapons are theoretically possible. (In nuclear weapons, a small amount of uranium mass is translated into considerable energy). Anyways, given 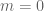 to
to 
 (“energy equals momentum times speed-of-light”). We also know that that
(“energy equals momentum times speed-of-light”). We also know that that  (“momentum equals Planck’s constant divided by wavelength”). Putting these together yields the cumulative value for energy of a photon:
(“momentum equals Planck’s constant divided by wavelength”). Putting these together yields the cumulative value for energy of a photon:
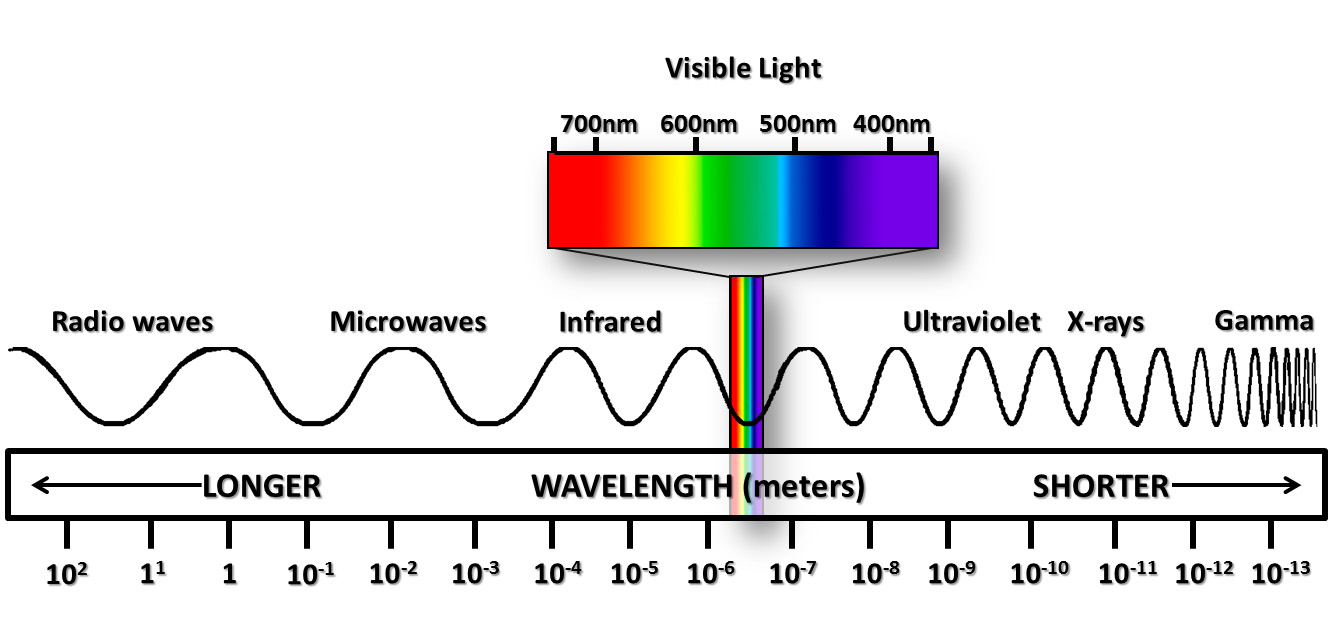
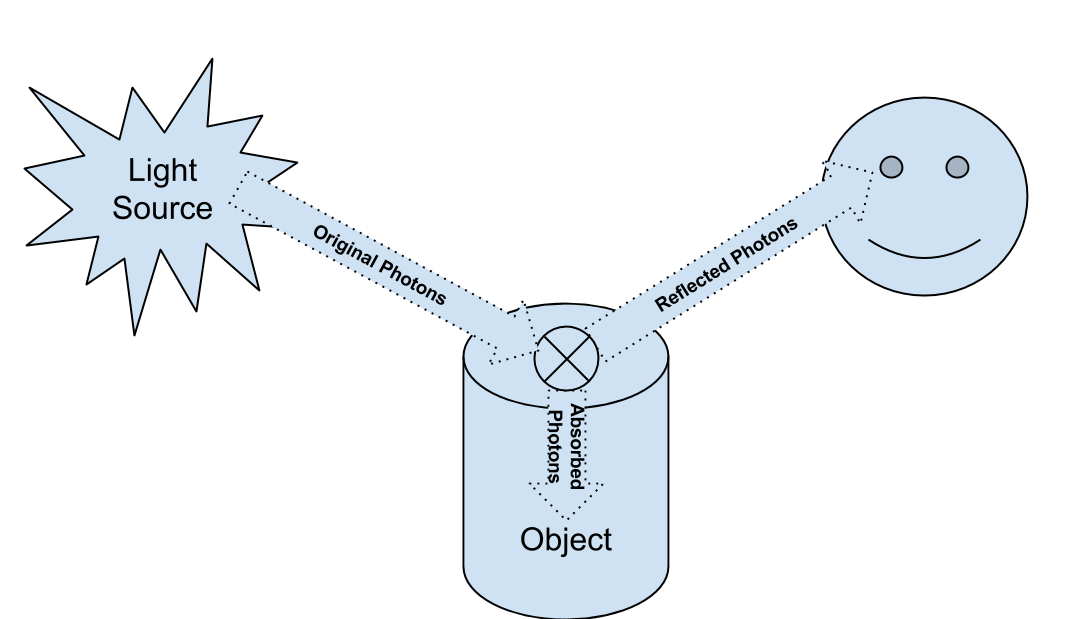
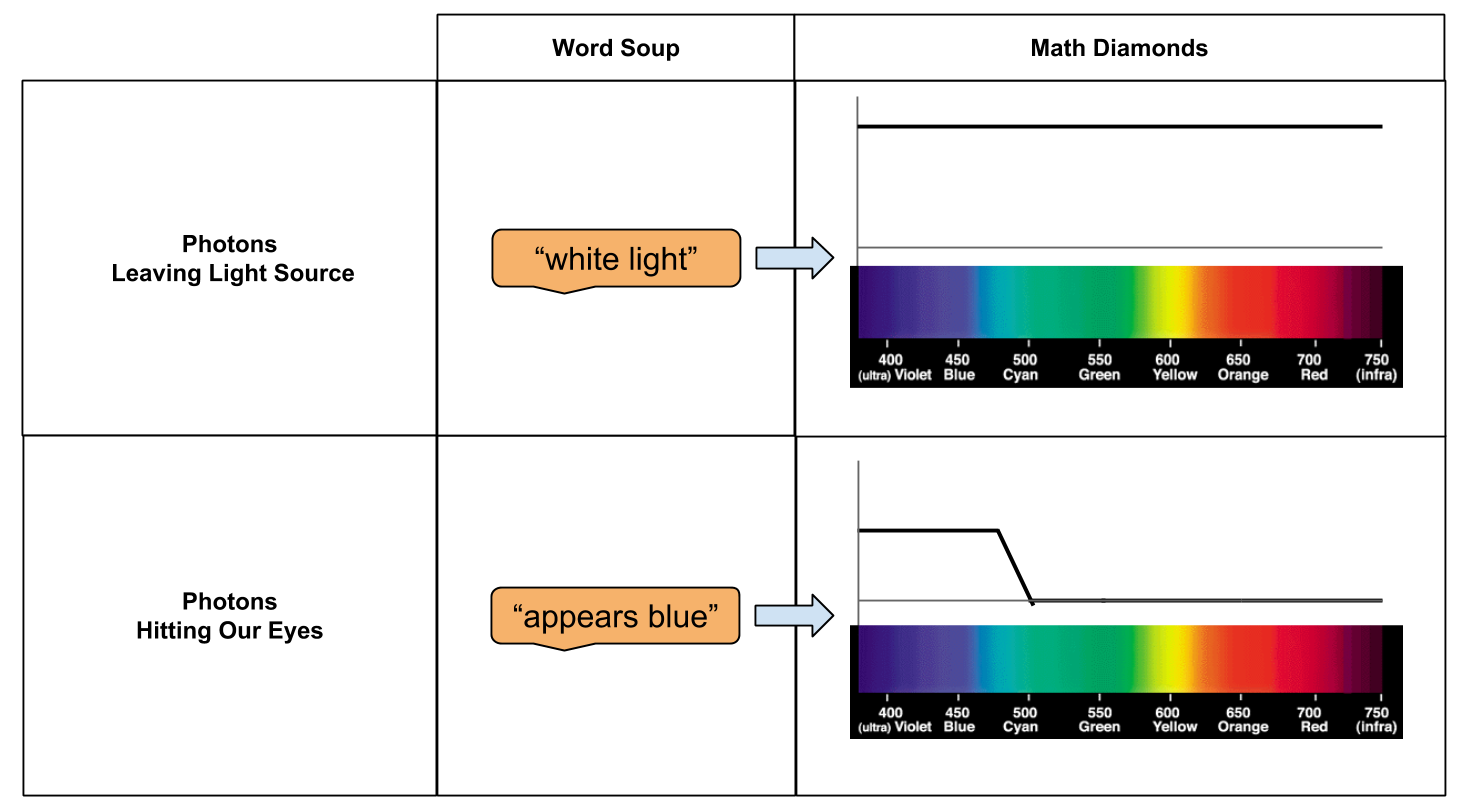
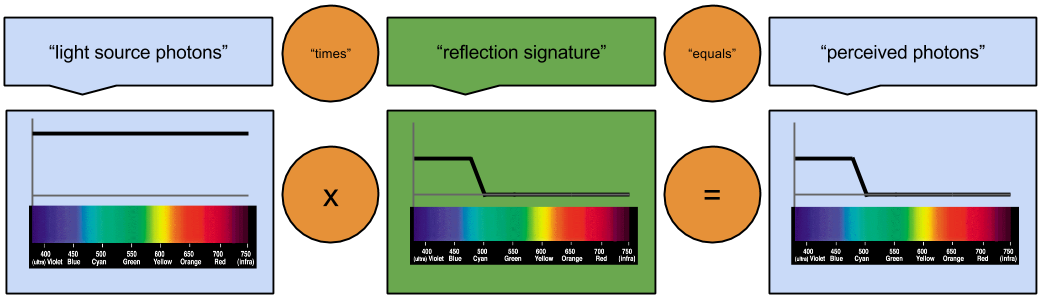








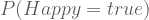






 . So we can glue the above equations together.
. So we can glue the above equations together.