
Part Of: Machine Learning sequence
Content Summary: 800 words, 8 min read
Projection as Geometric Approximation
If we have a vector 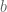


The closest point 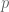

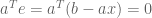
This formula captures projection onto a vector. But what if you want to project to a higher dimensional surface?
Imagine a plane, whose basis vectors are 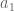


Suppose we want to project vector

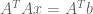
Matrices like 
We shall assume that the columns of 
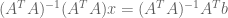

Recall that,
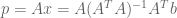
Since matrices are linear transformations (functions that operate on vectors), it is natural to express the problem in terms of a projection matrix 

By combining these two formula, we solve for

Thus, we have two perspectives on the same underlying formula:

Linear Regression via Projection
We have previously noted that machine learning attempts to approximate the shape of the data. Prediction functions include classification (discrete output) and regression (continuous output).
Consider an example with three data points. Can we predict the price of the next item, given its size?
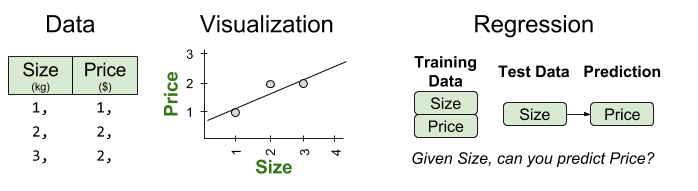
For these data, a linear regression function will take the following form:

We can thus interpret linear regression as an attempt to solve 

In this example, we have more data than parameters (3 vs 2). In real-world problems, it is an extremely common predicament. It yields matrices with may more equations than unknowns. This means that
If exact solutions are impossible, we can still hope for an approximating solution. Perhaps we can find a vector p that best approximates b. More formally, we desire some 

Since projection is a form of approximation, we can use a projection matrix to construct our linear prediction function 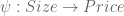

A Worked Example
The solution is to make the error 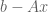
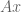
To repeat, the best combination 


We can use Guass-Jordan Elimination to compute the inversion:

A useful intermediate quantity is as follows:
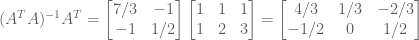
We are now able to compute the parameters of our model, 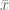
![\bar{x} = \left[ (A^TA)^{-1}A^T \right] b = \begin{bmatrix} 4/3 & 1/3 & -2/3 \\ -1/2 & 0 & 1/2 \\ \end{bmatrix} \begin{bmatrix} 1 \\ 2 \\ 2 \\ \end{bmatrix} = \begin{bmatrix} 2/3 \\ 1/2 \\ \end{bmatrix}](https://s0.wp.com/latex.php?latex=%5Cbar%7Bx%7D+%3D+%5Cleft%5B+%28A%5ETA%29%5E%7B-1%7DA%5ET+%5Cright%5D+b+%3D+%5Cbegin%7Bbmatrix%7D+4%2F3+%26+1%2F3+%26+-2%2F3+%5C%5C+-1%2F2+%26+0+%26+1%2F2+%5C%5C+%5Cend%7Bbmatrix%7D+%5Cbegin%7Bbmatrix%7D+1+%5C%5C+2+%5C%5C+2+%5C%5C+%5Cend%7Bbmatrix%7D+%3D+%5Cbegin%7Bbmatrix%7D+2%2F3+%5C%5C+1%2F2+%5C%5C+%5Cend%7Bbmatrix%7D&bg=ffffff&fg=555555&s=0&c=20201002)
These parameters generate a predictive function with the following structure:
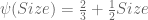
These values correspond with the line that best fits our original data!
Wrapping Up
Takeaways:
- In linear algebra, projection approximates a high-dimensional surface in a lower-dimensional space. The projection error can be measured.
- In linear regression, we usually cannot solve
- We can find the closest vector in the column space by projecting onto
- Thus, the operation of projection can be used to perform parameter estimation, and produce a model that best approximates the training data.
Related Resources:
- This article is largely based on MIT lecture Projections onto Subspaces and Projection Matrices and Least Squares. If you’d like to test whether you understood this method, try the example problems for yourself!
