
Part Of: Machine Learning sequence
Content Summary: 800 words, 8 min read
Parameter Space vs Feature Space
Let’s recall the equation of a line.

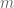
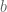
The equation of a line is a function that maps from inputs (x) to outputs (y). Internal to that model (the knobs inside the box) reside parameters like
Any model 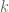

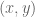
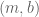
As we traverse parameter space, we can view the corresponding models in data space.

As we proceed, it is very important to hold these concepts in mind.
Loss Functions
Consider the following two regression models. Which one is better?

The answer comes easily: Model A. But as the data volume increases, choosing between models can become quite difficult. Is there a way to automate such comparisons?
Put another way, your judgment about model goodness is an intuition manufactured in your brain. Algorithms don’t have access to your intuitions. We need a loss function that translates intuitions into numbers.
Regression models are functions of the form 


The larger the residuals, the worse the model. Let’s use the residual vector to define a loss function. To do this, in the language of database theory, we need to aggregate the column down to a scalar. In the language of linear algebra, we need to compute the length of the vector.
Everyone agrees that residuals matter, when deriving the loss function. Not everyone agrees how to translate the residual vector into a single number. Let me add a couple examples to motivate:
Sum together all prediction errors.
But then an deeply flawed model with residual vector ![[ -30, 30, -30, 30]](https://s0.wp.com/latex.php?latex=%5B+-30%2C+30%2C+-30%2C+30%5D&bg=ffffff&fg=555555&s=0&c=20201002)
![[0, 0, 0, 0]](https://s0.wp.com/latex.php?latex=%5B0%2C+0%2C+0%2C+0%5D&bg=ffffff&fg=555555&s=0&c=20201002)
Sum together the magnitude of the prediction errors.
But then a larger dataset costs more than a small one. A good model against a large dataset with residual vector ![[ 1, -1, 1, -1, 1, -1 ]](https://s0.wp.com/latex.php?latex=%5B+1%2C+-1%2C+1%2C+-1%2C+1%2C+-1+%5D&bg=ffffff&fg=555555&s=0&c=20201002)
![[ 3, -3 ]](https://s0.wp.com/latex.php?latex=%5B+3%2C+-3+%5D&bg=ffffff&fg=555555&s=0&c=20201002)
Find the average magnitude of the prediction errors.
This loss function suffers from fewer bugs. It even has a name: Mean Absolute Error (MAE), also known as the L1-norm.
There are many other valid ways of defining a loss function that we will explore later. I just used the L1-norm to motivate the topic.
Grading Parameter Space
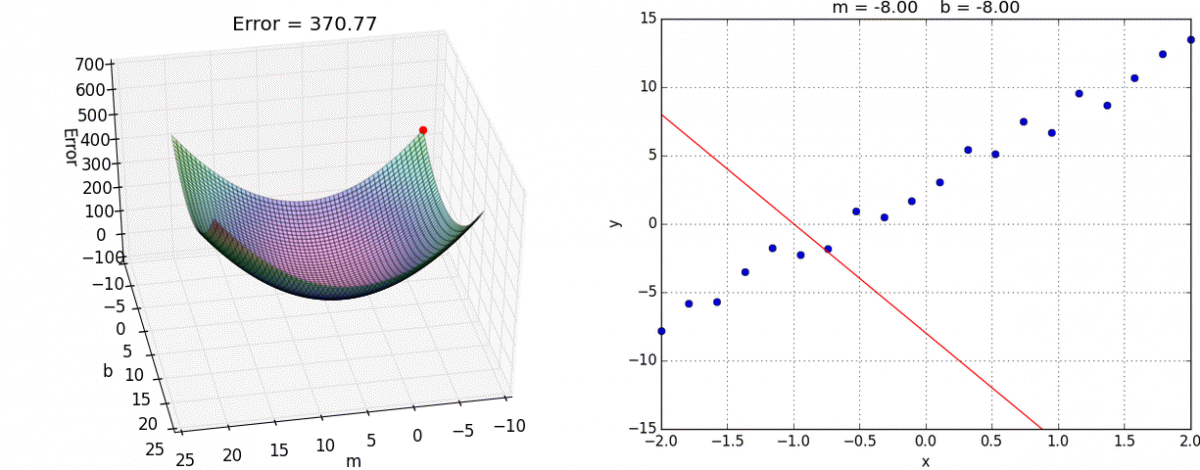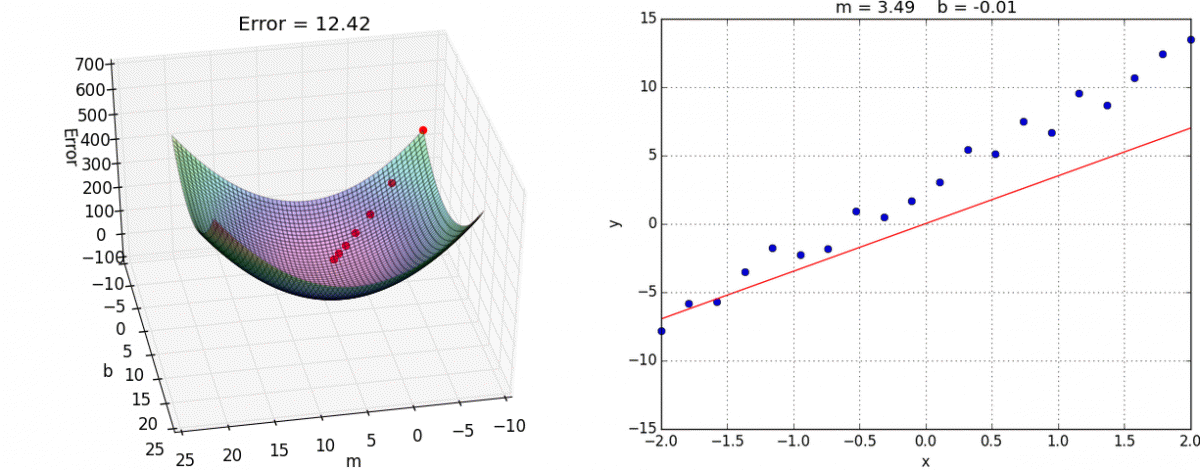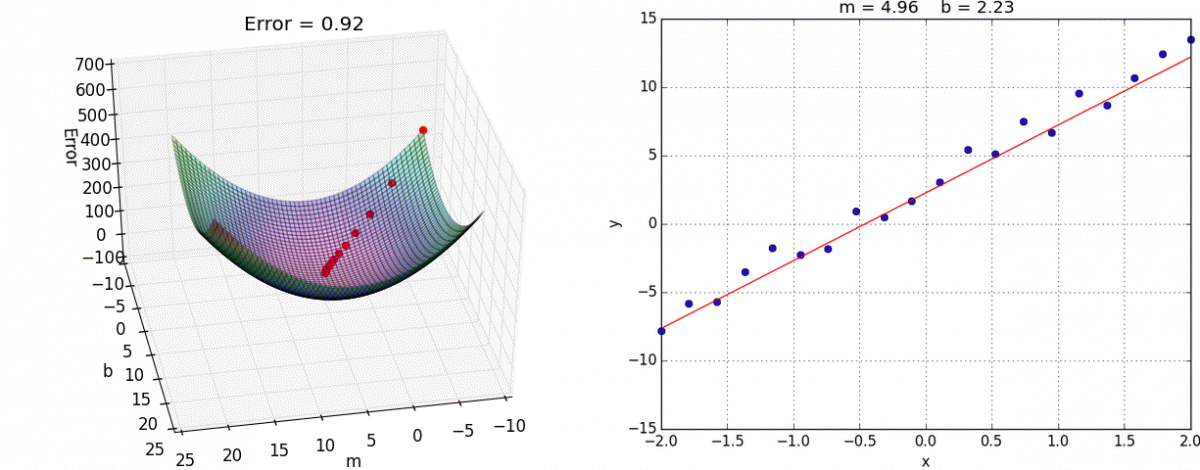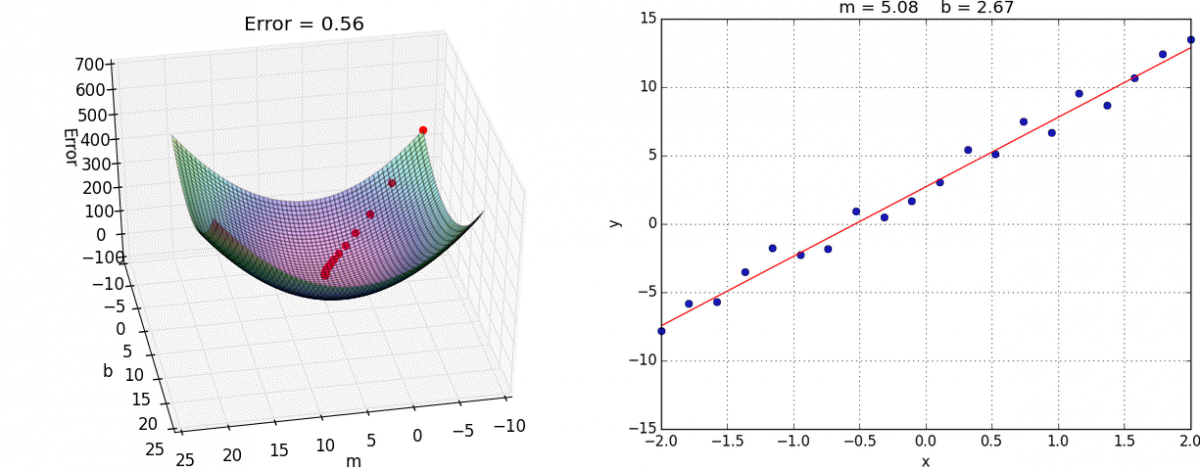
Let’s return to the question of evaluating model performance. For the following five models, we intuitively judge their performance as steadily worsening:

With loss functions, we convert these intuitive judgments into numbers. Let’s include these loss numbers in label space, and encode them as color.

Still with me? Something important is going on here.
We have examined the loss of five models. What happens if we evaluate two hundred different models? One thousand? A million? With enough samples, we can gain a high-resolution view of the loss surface. This loss surface can be expressed with loss as color, or loss as height along the z-axis.

In this case, the loss surface is convex: it is in the shape of a bowl.
Navigating the Loss Surface
The notion of a loss surface takes a while to digest. But it is worth the effort. The loss surface is the reason machine learning is possible.
By looking at a loss surface, you can visually identify the global minimum: the model instantiation with the least amount of loss. In our example above, that is 


Unfortunately, computing the loss surface is computationally intractable. It takes too long to calculate the loss of every possible model. How can we do better?
- Start with an arbitrary model.
- Figure out how to improve it.
- Repeat.
One useful metaphor for this kind of algorithm is a flashlight in the dark. We can’t see the entire landscape, but our flashlight provides information about our immediate surroundings.

But what local information can we use to decide where to move in parameter space? Simple: the gradient (i.e., the slope)! If we move downhill in this bowl-life surface, we will come to a rest at the set of best parameters.

A ball rolling down a hill.
This is how gradient descent works, in both spaces:

This is how prediction machines learn from data.
Until next time.

{kind=link}