Excerpt From: Olson (2010). Power and Prosperity Content Summary: 1200 words, 6 min read Part Of: Politics sequence
Theft in Moderation
Let us contrast the individual criminal in a populous community with the head of a Mafia family that can monopolize crime in a neighborhood. Suppose that in some well-defined turf, a criminal gang cannot only steal more or less as it pleases but can prevent anyone else from committing crimes there. Will it gain from taking all it can on its own ground? Definitely not.
If business in this domain is made unprofitable by theft, or migration away from the neighborhood is prompted by crime, then the neighborhood will not generate as much income and there will not be as much to steal. Indeed, the Mafia family with a true and continuing monopoly on crime in a neighborhood will not commit any robberies at all. If it monopolizes crime in the neighborhood, it will gain from promoting business profitability and safe residential life there.
Thus, the secure Mafia family will maximize its take by selling protection- both against the crime it would commit itself (if not paid) as well as that which would be committed by others (if it did not keep out other criminals). Other things being equal, the better the community is as an environment for business and for living, the more the protection racket will bring in. Accordingly, if one Mafia family has the power to monopolize crime, there is little or no crime (apart from the protection racket). The considerable literature on monopolized crime makes it clear that secure monopolization of crime does, in fact, usually lead to protection rackets rather than ordinary crime. Outbreaks of theft and violence in Mafia-type environments are normally a sign that the controlling gang is losing its monopoly.
The individual robber in a populous society obtains such a narrow stake of any loss to society that he ignores the damage his thievery does to society. By contrast, the Mafia family that monopolizes crime in a community has, because of this monopoly, a moderately encompassing stake in the income of that community, so it takes the interest of the community into account in using its coercive power. Whereas the individual criminal in a populous society bears only a minuscule share of the social loss from his crime, the gang with a secure monopoly on crime in a neighborhood obtains a significant fraction of the total income of the community from its protection tax theft. Therefore, though the individual criminal normally takes all of the money in the wallet he steals, the secure and rational Mafia leader never sets a protection tax rate anywhere near 100 percent: this would reduce the neighborhood’s income so much that the Mafia family itself would be a net loser.
Preference for Stationary Bandits
The warlord who I was reading about, Feng Yu-hsiang, was noted for the exceptional extent to which he used his army for suppressing thievery and for his defeat of the relatively substantial army of a notorious roving bandit called White Wolf. Apparently, most people in Feng’s domain wanted him to stay as warlord and greatly preferred him to the roving bandits. At first, this situation was puzzling: Why should warlords who were simply stationary bandits continuously stealing from a given group of victims be preferred, by those victims, to roving bandits who soon departed? The warlords had no claim to legitimacy and their thefts were distinguished from those of roving bandits only because they took the form of relentless tax theft rather than occasional plunder.
There is a good reason for this preference. As we have seen, there is little production in an anarchy and thus not much to steal. If the leader of a roving bandit gang who finds only slim pickings is strong enough to take hold of a given territory and to keep other bandits out, he can monopolize crime in that area- he becomes a stationary bandit. The advantage of this monopoly over crime is not mainly that he can take what others might have stolen: it is rather that it gives him an encompassing interest in the territory. He actually has a stronger encompassing interest than the Mafia family, since the bandit leader who takes over an anarchic area does not have competition from any government’s tax collectors: he is the only one who is able to tax or steal in the domain in question.
A Benefactor to Those He Robs
The second way in which the encompassing interest of the stationary bandit changes his incentives is that it gives him an incentive to provide public goods that benefit his domain and those from whom his tax theft is taken. Paradoxically, he provides these public goods with money that he fully controls and could spend entirely on himself. We know that a public good benefits everyone in some area or group and that many public goods, such as levees that protect against floods, police that deter crime, and quarantines that limit contagious diseases, make a society more productive. He has an incentive to spend his resources on all productivity-enhancing public goods up to the point where his last dollar spent on these goods equals his share of the resulting increase in output. Thus, if the stationary bandit’s optimal rate of tax theft is 50 percent, he will spend on public goods up to the point where the last dollar spent on these goods adds $2 to the output of the domain, since he will then receive $1. Readers who want formal proofs and a mathematical and geometric exposition of this argument should consult McGuire & Olson (1996).
The bandit leader, if he is strong enough to hold a territory securely and monopolize theft there, has an encompassing stake in his domain. This encompassing interest leads him to
Limit and regularize the rate of his theft and to spend some of the resources that he controls on public goods that benefit his victims no less than himself.
Since the settled bandit’s victims are for him a source of tax payments, he prohibits the murder or maiming of his subjects.
Because stealing by his subjects, and the theft-averting behavior that it generates, reduces total in-come, the bandit does not allow theft by anyone but himself.
He serves his interests by spending some of the resources that he controls to deter crime among his subjects and to provide other public goods. A bandit leader with sufficient strength to control and hold a territory has an incentive to settle down, to wear a crown, and to become a public good- providing autocrat.
Autocracy has been commonplace at least since King Sargon’s conquests created the empire of Akkad in ancient Mesopotamia. Most of humanity over most of history has been subjected to autocracy and exploited by tax theft. It is very difficult to find examples of benevolent despots. The stationary bandit model fits the facts far better than the hypothesis that autocrats are altruistic.
References
McGuire & Olson (1996). The Economics of Autocracy and Majority Rule
Claudia Goldin earned the Nobel Prize for advancing our understanding of women’s labor market outcomes. Her book Career and Family synthesizes her work.
The text can be conceptualized as two separate books:
The first book (Ch2-7) discusses the demographics of the feminist movement from 1900-2000, which she partitions into five waves.
The second book (Ch1, 8-10) discusses the gender earnings gap, and her explanation for why this gap persists.
Her analysis in the former was interesting (particularly the discussion on the Pill vs divorce rates). But here, we will focus on the latter.
In fact, the gender earnings gap, defined as the difference in medium income across genders, has somewhat lessened over time. But, especially for the college educated, it remains troublingly large:
Before the 1980s, a considerable part of the earnings gap was due to differences in preparation for the labor market, such as education, training, and job experience. But by around 2000, differences between men’s and women’s job market preparation became small.
Goldin begins by reviewing the “standard theories” for the gender earnings gap. They are:
Occupational Segregation: women simply have different preferences for occupation (these differences may be culturally inherited, or more biological)
Negotiation Style: women are less competitive and less effective at labor negotiations (these differences may be culturally inherited, or more biological)
Employer Bias: employers have unconscious biases that add up to substantial impairment to women’s careers.
There are reasons to take these theories seriously:
Occupational segregation (genders choosing stereotypical professions) explains about one third of the gender gap.
Women do on average have higher Agreeableness on the Big-Five spectrum, and this personality facet predicts poor occupational outcomes.
And the implicit association test (IAT) suggests subconscious biases exist.
A whole cottage industry has emerged from these theories. We try to “fix” the women (negotiation training), to “fix” the managers (debiasing).
But the three hypotheses struggle to explain other features of the earnings gap. When you examine the earnings gap longitudinally, things become more clear.
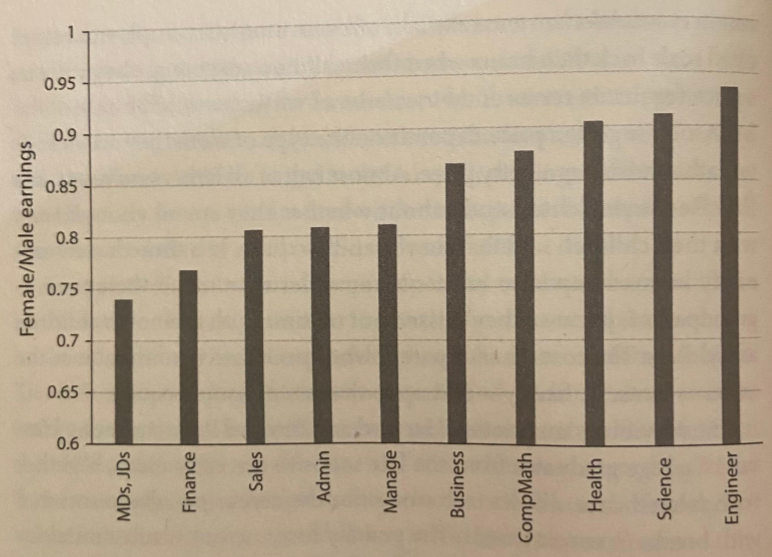
For MBA women with no kids (white bars), the earnings gap begins around 90% and is remarkably stable over time. For MBA women, including those with kids (black bars), the earnings gap steadily declines.This decline usually begins after childbirth.
Occupational segregation may explain the constant 10% gap (white bars). It is harder to explain the larger, ever-growing motherhood-specific gap. Why should negotiation style and managerial paternalism only affect mothers?
In the first five years after the birth, a woman whose spouse was in the top-earning group was 32 percent less likely to be working than if her husband was not. Butwomen who have high-earning husbands but no children put in as many years of employment and hours of work. Why should having a high-earning spouse.only matter for mothers?
The confusion deepens when you look at the earnings gap across occupations:
Are medicine and law uniquely paternalistic? Are science and engineering culture especially egalitarian?
Time Constraints Explain the Gap
Let’s turn to the legal profession. If you compare men and women lawyers five years after their JD, the number of hours worked is fairly equivalent. But if you take the same survey 15 years in, women are simply working much fewer hours, on average:
A similar trend holds when you consider work setting over time. Females are much more likely to be non-practicing, or not currently employed.
Are women actually receiving lower pay for equal work? Not so much anymore. Discrimination in terms of unequal earnings for the same work for a small fraction of the total earnings gap. Mothers are more likely to work fewer hours, and more likely to take breaks in their careers. According to Goldin, nearly all of the gender earnings gap is mediated by the number of hours worked, and the number of months taken off. The gender gap persists despite there being nearly “equal pay for equal work”.
Let’s return to the earnings gap by occupation.
What differentiates high- from low-inequality occupations? Drawing on the O*NET database, the following occupational properties are predictive of a large earnings gap:
Contact with others: How much contact with others (by telephone, face-to-face, or otherwise) is required to perform your current job?
Frequency of decision making: In your current job, how often do your decisions affect other people or the reputation or finances of your employer?
Time pressure: How often does this job require the worker to meet strict deadlines?
Structured versus unstructured work: To what extent is this work predefined, rather than allowing the worker to determine tasks, priorities, and goals?
Establishing and maintaining interpersonal relationships: What is the importance of developing cooperative working relationships and maintaining them?
Time-intensive occupations have higher penalties for fewer hours and more frequent sabbaticals. This explains why the earnings gap has not closed much in recent decades. While women are graduating in record numbers, many occupations are becoming more time-intensive over time.
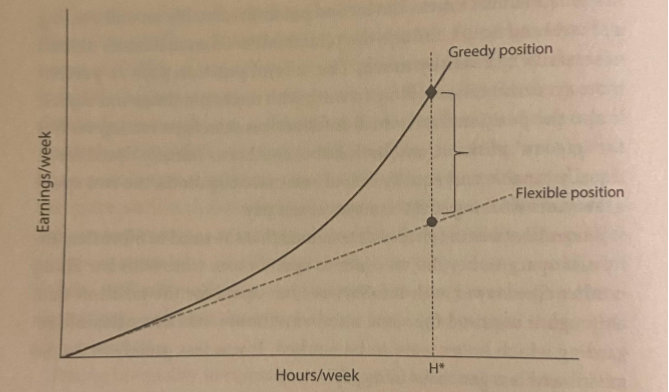
Greedy Work vs Couple Equity
Some jobs offer the same hourly rate to a worker who works 40 hours a week, to those who work 80. This linear payoff has the latter earning twice as much. Call this flexible work. But other jobs offer increasing rates for workers who go above and beyond. On greedy work, one person who works 80-hour weeks will receive significantly more than two people working 40-hour weeks.
Why are certain jobs, like being a lawyer, greedy? If the job involves personal relationships, and the transaction cannot be easily offloaded to a coworker, the price of unavailability and sabbaticals is difficult to manage. The more substitutable the labor, the less greedy the work.
Consider the relationship between couple equity vs earnings gap. Greedy work incentivizes partners to specialize in either career or family. Equal contributions to career and family leave a lot of money on the table. In other words, greedy work is a tax on couple equity. In heterosexual couples, the earnings gap directly reflects couple equity. But greedy work also harms couple equity in same-sex relationships, even if this impact doesn’t drive a (demographically measurable) earnings gap.
Promoting Gender Equality in Practice
On the time boundedness theory, the earnings gap should respond to more affordable childcare, and fathers participating more in childcare. But Goldin is particularly interested in mitigating greedy work. If you remove the tax on couple equity, how much of the earnings gap will evaporate?
Pharmacy is an example of a profession that moved from greedy to flexible work. Pharmacy used to be very time-intensive:
You would have a personal relationship with your local pharmacist
Pharmacists had specialized knowledge of drug combinations, and their skill sets were not easily interchangeable.
Your local pharmacist owned their own local business
Local pharmacists were on-call at all hours for late-night emergencies
But all of these time-intensive factors changed in the last four decades. Labor in pharmacy is now substitutable; skill set variance has been reduced by information technology. The corporate takeover of this industry (e.g., Walgreens, CVS) outsourced the time-intensive aspects of business ownership. And emergency pharmacist shops removed the “on-call” expectations for the rest. These changes made the profession move towards linear pay scales (flexible work), and brought the earnings gap from 0.65 to 0.90!
The pharmacy revolution was not engineered to promote gender equality; but we can take the lessons from this industry to achieve this effect. Perhaps the most effective way to combat the earnings gap is to bring the substitutability revolution to other industries. We could encourage a shift from personal bankers to personal banker teams, for example..
Concluding Thoughts
I was hoping to find data directly bearing on the paternalism hypothesis, such as IAT scores by occupation. I wish I had a better understanding of the role negotiation style plays. I tend to agree that the greedy work theory explains the lion’s share of the data, but there are surely other factors in play.
One interesting observation that came out of Goldin’s research:
Two anomalies [to the time-intensivity trend] are those in the health field and in financial operations. Health occupations (such as physical therapists and dietitians) generally have highly specific tasks. They have low levels of gender inequality, but also higher-than-average time demands. On the other end, occupations in financial operations (such as financial advisors and loan officers) have high gender inequality but lower-than-average time demands. Although these occupations do not fit the framework using the five characteristics concerning time demands, they are strongly related to the sixth characteristic: competition. Health occupations have among the lowest degree of competition. Finance occupations have among the highest… Occupations with the greatest income inequality among men have among the largest gender earnings gaps.
This competition factor seems possibly independent of the greedy work theory. I would like to learn more about the effect between-group competition relates to the gender gap.
Recall that patriarchal attitudes (marginalization of women) tend to be accentuated in polities with intensive agriculture. Perhaps the emergence of these attitudes is related to the increase in within-group competition in these political structures. If this speculation is on the right track, I would imagine paternalism and bias to be accentuated for competitive occupations, not just time-intensive ones.
Gemini will be released in December 2023, with ~5x more compute than GPT-4.
As they learn about their conversational partners, LLMs sometimes repeat back what they take to be a preferred answer (aka sycophancy). This includes preferentially giving inaccurate answers to less educated conversants. Short dialogs make it difficult to build a detailed model of the interlocutor, but dialog length is trending up. Discussed more here.
What will GPT-2030 look like? “GPT2030’s copies can share knowledge due to having identical model weights, allowing for rapid parallel learning: I estimate 2,500 human-equivalent years of learning in 1 day. This would create serious vectors for misuse. Its rapid parallel learning could be turned towards human behavior and thus used to manipulate and misinform with the benefit of thousands of “years” of practice.”
Biology
Although many biomolecules exist in distinct mirror-image forms, life tends to use just one of those forms exclusively. Homochirality is one of the most interesting clues about the origins of life. Geomagnetism may explain it.
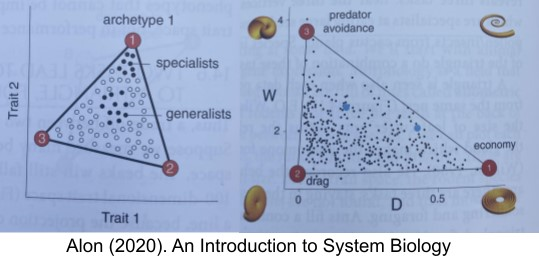
If you take physical attributes of a mollusk (like radius growth rate W and ratio between inner and outer shell radii D), and plot various species in this 2D trait space. They often reside on a polytope! Each vertex in the polytope is an archetype for a particular task. In Pareto task inference, you can reverse engineer the task by examining the specialists who reside near the archetype. Mollusks, for example, trade-off between three tasks: predator avoidance, low drag, and energy efficiency. In fact, during the P/T extinction event, only certain species survived – but as they recovered and diversified, their fossils reconstituted the entire polytope.
Modularity is a central organizing principle in biology. But non-modular solutions are the norm in many computer simulations of natural selection. Modularity can be recovered when you account for modularly varying goals (MVGs): goals retain a shared substructure. Each module learns a subtask which remain useful even after the goals change.
Physics
We have two ways of measuring the expansion rate of the Universe: from the CMB, and from supernovas. These measurements disagree: this is the Hubble tension. Physicists have recently devised a third way to measure the Hubble constant: using cosmic voids. Their results align more closely with the CMB measurement.
Where did supermassive black holes (SMBHs) come from? Very large SMBH from 0.7 by after the Big Bang have been found by JWST. It is difficult to explain their size, because black hole normally do not exceed the Eddington Limit on growth. Two competing theories to resolve the paradox: super-Eddington accretion of light seeds, or a “heavy seed”.
One possible resolution might lie in dark stars: stars that burn not by fusion, but with annihilation of dark matter particles. These stars would have comparable luminosity to entire galaxies. Some research groups have identified dark star candidates. If they exist, they might be the “heavy seeds” needed for early SMBHs.
Unlike chess, superhuman Go programs are vulnerable to adversarial attacks. Performance doesn’t always translate into robustness. “Notably, our adversaries do not win by learning to play Go better than KataGo – in fact, our adversaries are easily beaten by human amateurs,” the team wrote in their paper. “Instead, our adversaries win by tricking KataGo into making serious blunders.”
Automated method to jailbreak LLMs announced, that appear to jailbreak all publicly-available LLMs. “Instead of relying on manual engineering, our approach automatically produces these adversarial suffixes by a combination of greedy and gradient-based search techniques, and also improves over past automatic prompt generation methods.”
Deepmind claims its next chatbot Gemini will rival ChatGPT.
Cognitive Science
Whole-brain connectome of fruit fly. With our current compute, why can’t we create accurate computer simulations of these creatures in a virtual 3D environment?
Current Events
A preprint announces the discovery of a room-temperature, ambient-pressure superconductor, called LK-99. Revolutionary if true. At time of this writing, replication attempts are underway. Very preliminary data has the betting markets giving 25% credence to a successful replication.
The Panspermia Sibling Hypothesis of UAPs. Robin Hanson’s grabby aliens model holds that, if Earthly life originated independently, then we should expect the nearest alien species to be 100 million galaxies away, and should not expect to meet them for ~1 billion years. But life could have been seeded from an ancestral exoplanet Eden into our stellar nursery. This panspermia model is comparatively more likely, since it gives the universe ~10 billion years (vs 4.5) to incubate civilization-capable life. So, on the small chance that UAPs are indeed aliens (vs hoax or mistake or terrestrial technology), then we should expect those aliens to come from one of the ~1000 stars born in our Sun’s nursery.
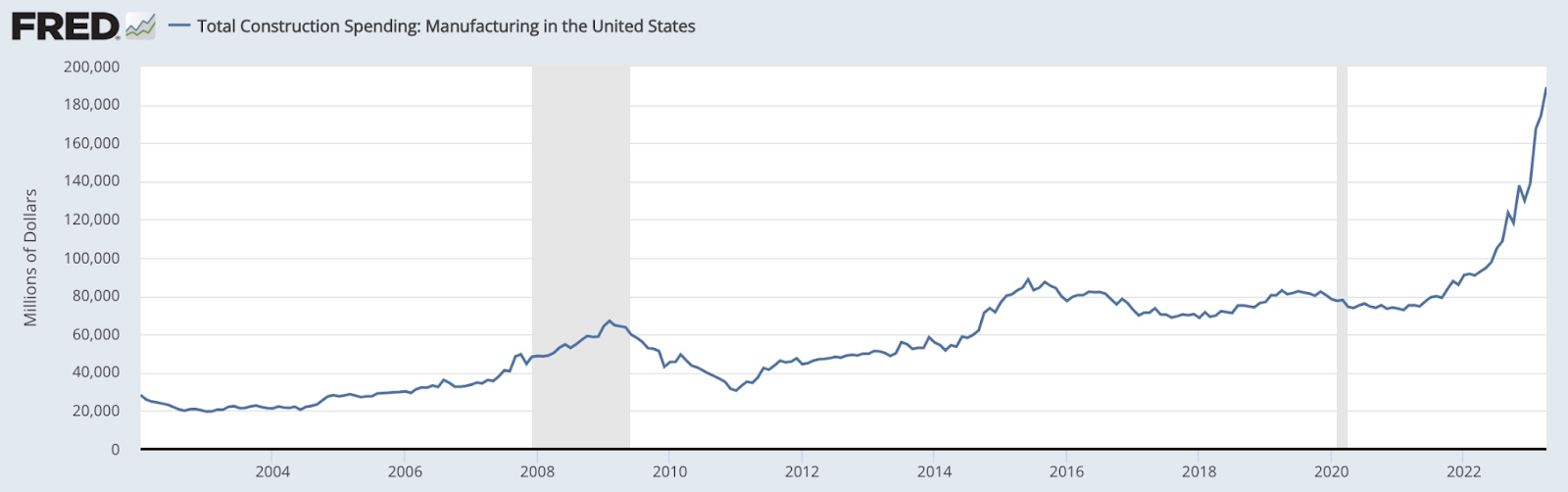
Total construction spending in the US. Related to the CHIPS and Science Act.
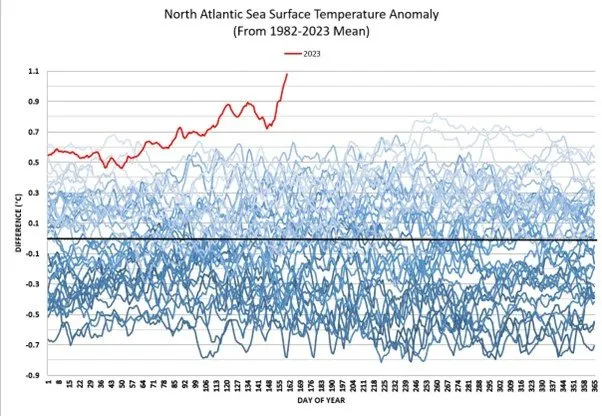
The Atlantic meridional overturning circulation (AMOC) may be failing. Related to the North Atlantic sea surface temperature anomaly.
Part Of:Affective Neuroscience sequence Content Summary: 1800 words, 9 min read Content Note: This post discusses Barrett (2017). How Emotions are Made.
Essentialism vs Constructionism
This book extends an old debate between essentialism and constructionism.
Essentialism interprets cognition as produced by innate mental modules which produce distinct behavioral programs. It seeks to localize function onto structures in the nervous system. Lesion evidence is considered suggestive. Essentialism relies on the abstraction hierarchy, with less abstract, more instinctive decisions operating underneath the cortex, with more abstract and reflective decisions manifesting under conscious control. It is often couched in terms of dual process theory.
Constructionism interprets cognition as whole-brain prediction cascades, with predictions flowing from control and body-oriented networks to primary sensory cortices. Perception is inference. These cascades flow through intrinsic connectivity networks (ICN), with each function subserved with ever-changing microcircuits that by their nature defy localization. This theory meshes nicely with Friston’s active inference theory, with descending predictions and ascending prediction errors.
Classical Model of Emotion
The classical model of emotion is essentialist in character. The classical view posits at least six primary emotions: anger, fear, disgust, surprise, sadness and happiness. Each basic emotion is supposed to have a unique neural substrate, physiological signature, and motor program. The basic emotion method, championed by Paul Ekman and others, asks people to match faces to emotions. People from every culture tested tend to draw the same map between these faces and the corresponding emotions, achieving about 72% accuracy. Such cross-cultural universality is taken as evidence of innateness.
Concerningly, performance plummets when you modify the experimental setup. If you remove the emotion words and ask subjects to describe the imagined feeling in their own words, performance drops from 72% to 58%. If you remove the language component entirely, and ask whether people in two different images are feeling the same emotion, accuracy drops to 42%. Finally, subjects were asked to repeat an emotion word like “anger” over and over”. Eventually, the word becomes just a sound to the subject (“ang-gurr”) that’s mentally disconnected from its meaning. People in such a state of semantic satiation are even more impaired at emotion masking tasks, achieving 36% accuracy.
Other evidence converges.
When you measure emotional expression with electromyography, there isn’t much muscular consistency within emotions. Extreme variation is the norm.
The search for physiological fingerprints has also failed. Anger and fear, for example, yield very similar effects on heart rate.
The search for neural fingerprints for various emotional circuits have also
Taken together, these data suggest that emotion may not be innate. Emotions may be conceptual in character, with a curious dependency on language.
Constructivist Model of Emotion
Having disputing the classical theory of emotion, Barrett turns to constructing her alternate account.
Her constructivist model of emotion is grounded in body budgets: interoceptive and visceromotor mechanisms that allostatically regulate the body. Body budgets are summarized in the two dimensions of affect: valence and arousal. While emotions are cultural constructions, affect is a human universal. The constructivist model dovetails with the circumplex theory of affect.
Next, Barrett addresses the formation of emotion concepts. There are several accounts of concept on offer:
Classical concepts which specify a list of necessary and sufficient properties, like a dictionary.
Prototype concepts which are grounded in perceptual similarity (c.f., “I know it when I see it”)
Affordance concepts which categorize not by perceptual similarity, but instead via similarity of their use.
The concept of “chair” is not perceptually coherent; chairs are instead united by how our bodies use them. Affordance concepts are specific to humans, because they require language:
> Waxman demonstrated this power of words in infants as young as three months. The infants first viewed pictures of different dinosaurs. As each image was shown, infants heard an experimenter speak a made-up word, “toma.? When these infants were later shown pictures of a new dinosaur and a non-dinosaur such as a fish, those who had heard the word could distinguish more reliably which pictures depicted a “toma,” implying that they had formed a simple concept. When the same experiment was performed with audio tones instead of human speech, the effect never materialized.
Emotions as Social Reality
Some affordance concepts can be understood as social reality. Most things in your life are socially constructed: your job, your street address, your government and laws, your social status. Money is a classic example of social reality. Given a rectangle of paper with a dead leader’s face printed on it, and you can “buy products”. Barrett suggests that emotions are affordance concepts, synchronized through language. Emotions are like money: a pillar of social reality.
Consider a man stamping his foot. The man thinks he is removing mud from his boot; you think he is angry; your friend thinks he is dejected. Who is right? On the constructivist model, questions of accuracy are unanswerable in an objective sense. There are no observer-independent measurements that can adjudicate. The best you can do is communicate reasons and seek consensus. This is not to say that emotions are “just in your head.” That phrase trivializes the power of social reality. Money, reputation, laws, government, friendship, and all of our most fervent beliefs are also “just” in human minds, but people live and die for them. They are real because people agree that they’re real.
Since emotions are synchronized within a culture, they tend to vary across cultures. You can see this in how individualistic countries interpret guilt and shame differently from collectivist ones.
You are probably unfamiliar with an emotion called liget. It’s a feeling of exuberant aggression experienced by a headhunting tribe from the Philippines, the Ilongot. Liget involves intense focus, passion, and energy while pursuing a hazardous challenge with a group of people who are competing against another group. The danger and energy instill a sense of togetherness and belonging. Liget is not just a mental state but a complex situation with social rules about which activities bring it on, when it is appropriate to feel, and how other people should treat you during an episode. To a member of the Ilongot tribe, liget is every bit as real an emotion as anger or surprise. Westerners surely do experience pleasant aggression, for example video game players cultivate it during first-person shooter games. But these people are not experiencing liget with all its meaning, prescribed actions, and body-budget changes.
People moving between cultures are often shocked by the difference in emotion concepts. Smiling was not associated with happiness in Roman culture, for example.
But American culture prefer high arousal, pleasant states; immigrants often complain that their cheeks ache from smiling more frequently. But the more time someone spends in America, the more their emotions become attuned to the American context. Your pleasant emotion concepts became more granular in a process known as emotion acculturation.
Because emotion concepts affect our body budgets, nurturing your emotional intelligence is a way to aspire towards health. For Barrett, this means practicing the use of new emotional concepts (e.g., borrowing them from other concepts) and generally pursuing emotional granularity. Emotional granular individuals were 30 percent more flexible when regulating their emotions, less likely to drink excessively when stressed, and less likely to retaliate aggressively against someone who has hurt them. In contrast, lower emotional granularity is associated with all sorts of afflictions. While the causal role for emotional granularity is not yet known, it conceivably plays a role. It would explain why parents find it helpful to teach their children to “use their words”.
Affective Programs in Subcortex
Barrett’s treatment of neuroscience is rather cortex-oriented. What about the subcortex? Barrett’s skepticism notwithstanding, I find the evidence for modules in the subcortex to be persuasive
Consider anger. Electrical stimulation of the brain in specific subcortical areas elicit three subvarieties of anger behavior: reactive anger, predatory behaviors (quiet biting attack), and inter-male aggression. These behaviors also are differentiated pharmacologically. Chlordiazepoxide reduces affective attack and increases predatory attack; amphetamine increases affective attack without no effect on predatory attack. In the evolution of Sapiens, affective anger and predatory behaviors seem to respond differentially to selection pressures. Modular circuits have also been identified for fear behaviors, anxious behaviors, seeking behaviors, and other behavioral expressions of emotion.
Such affective programs in the subcortex are organized hierarchically. For example, anger is organized as cortex > amygdala > hypothalamus > periaqueductal gray (specific nuclei within these structures). Lesions to higher areas does not diminish affective behaviors, but damage to lower areas are much more severe. Higher cognition appears to play a role in modulating these programs. Decorticate animals activate their affective programs more vigorously, and are less receptive to change. Affective programs are also evolutionarily ancient; we find them in nearly every species studied.
Approaching The Debate
Constructionists emphasize the role of cortex in emotional experiences and emotion perception, whereas essentialists emphasize the role of subcortical structures in emotional behaviors.
Barrett claims that emotions have no neural signature, and therefore disagreements about emotional attribution (“I did it because I was angry”) cannot be resolved by observer-independent measurement. Perhaps consciousness does not have privileged access to these states, and self-report defaults to confabulation. Perhaps emotion perception must resort to consensus seeking. But it seems possible to objectively resolve questions of emotional behavior and even changes in disposition.
If you assume that these subcortical programs generate conscious feelings, then you must conclude that animals have conscious feelings. But many constructionists believe that only affect (arousal and valence) are accessible to consciousness. In this view, the complexity of emotional experiences must come from concepts.
Barrett claims that only humans experience emotions. This claim rests on four propositions
Emotion concepts operate independently of affective programs, beyond the dimensions of salience and arousal.
Emotions are goal-concepts, with teleological rather than perceptual coherence.
Goal-concepts are only acquired from language, non-human primates cannot acquire them.
Emotional goal-concepts can be synchronized with language, and are embedded in the fabric of social reality.
I am skeptical that all four are true. That said, I am not in a position to properly evaluate them.
I will say that constructionism brings much-needed attention to the importance of conscious concepts, how they inform emotional inferences about e.g., facial expressions. It sheds light on how culture produces different responses to shame and guilt. And it makes me wonder exactly how
In transformer architectures, attention heads are used to tell the model “where to look”. Induction heads (a specific kind of attention head) reliably form at late stages of training, and several lines of evidence suggest they may be the substrate of in-context learning (metalearning).
More from the mechanistic interpretability (MI) agenda. One of the challenges to MI research has been superposition: where a single neuron responds to multiple features. Neurons can represent data points in superpositions (memorization) instead of features (generalization). In toy model of data double descent, where models transition from overfitting to generalization, neurons transition away from representing data.
Othello-GPT has a linear emergent world model. Despite being trained on move sequences, different neurons encode different positions of board state. If you change the color of the G5 neuron, the model suddenly starts predicting H6, for example.
Physics
The Ads/CFT correspondence draws from the holographic principle to postulate mathematical duality between QM and general relativistic formalisms. Susskind advocates ER=EPR: that quantum superposition is a kind of Einstein-Rosen bridge (wormhole). More generally, that spatial proximity itself is created by webs of entanglement. Physicists have begun empirically testing this in the lab using qubits to examine the properties of quantum teleportation. Recently one experiment purported to demonstrate ER=EPR, But while teleportation did in fact occur, the signature of gravitational teleportation (side winding) was less diagnostic than originally hoped.
Strong evidence for a gravitational wave background (GWB) has been discovered with 15 years of data from pulsar timing arrays. Two potential sources for these waves: traditional explanations invoke collision of supermassive black holes (SMBH), and also cosmological explanations which can invoke new physics such as superstrings. SMBH collisions almost certainly contribute to GWB, but the GWB data is a bit hard to explain using only the standard model. Modeling results suggest many beyond standard model (BSM) theories may have the capacity to explain more. Stay tuned!.
Why is the prompt “let’s think step by step” so effective? Andrej Karpathy suggests “models need tokens to think”: since each token requires a similar amount of compute, harder problems require longer reasoning traces. More generally, prompts can (hackishly) approximate a kind of System 2 reflection. An interesting framework for interpreting recent innovations like tree of thoughts.
Certain academics (e.g., Yann LeCun) like to focus on architecture design. But the scaling hypothesis predicts AGI will come simply with more data and compute. “OpenAI, lacking anything like DeepMind’s resources, is making a startup-like bet that they know an important truth which is a secret: the scaling hypothesis is true!” That’s why they got there first: the courage of their convictions.
We have no moat: an interesting (albeit controversial) discussion of open-source vs closed-source AI development.
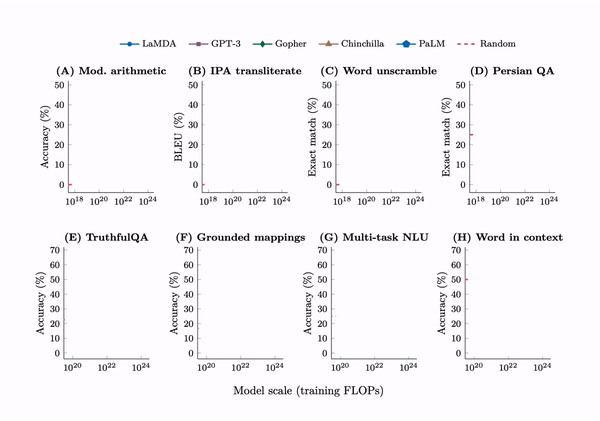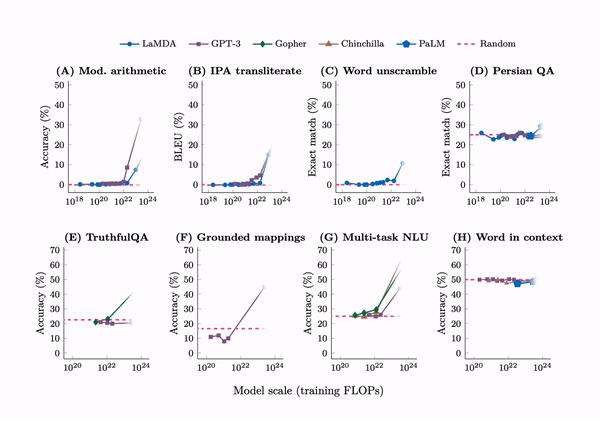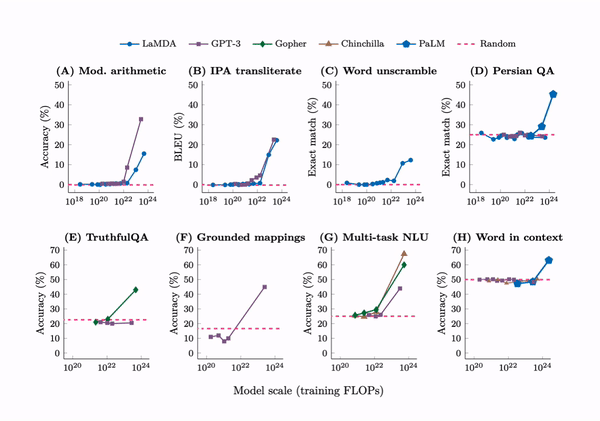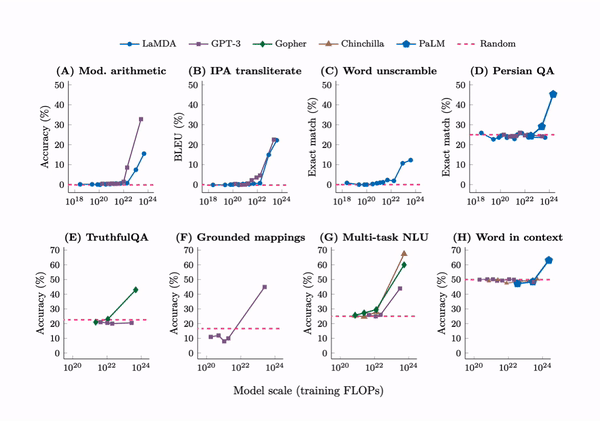
Emergence. A tabulation of 137 emergent abilities in LLMs. An explainer, “Somewhat mysteriously, all of these abilities emerge at a similar scale despite being relatively unrelated.” But see the misaligned evaluation metrics section for an important criticism.
Thomas Schelling described a kidnapper who suddenly gets cold feet. He wants to set his victim free, but is afraid he will go to the police. In return for his freedom, the victim gladly promises not to do so. The problem, however, is that both realize it will no longer be in the victim’s interest to keep this promise once he is free. And so the kidnapper reluctantly concludes that he must kill him.
Schelling suggests the following way out of the dilemma: “If the victim has committed an act whose disclosure could lead to blackmail, he may confess it; if not, he might commit one in the presence of his captor, to create a bond that will ensure his silence.” (Perhaps the victim could allow the kidnapper to photograph him in the process of some unspeakably degrading act.) The blackmailable act serves here as a commitment device, something that provides the victim with an incentive to keep his promise. Keeping it will still be unpleasant for him once he is freed; but clearly less so than not being able to make a credible promise in the first place.
Commitment Problems
In everyday economic and social interaction, we repeatedly encounter commitment problems like the one confronting Schelling’s kidnapper and victim. Being known to experience certain emotions enables us to make commitments that would otherwise not be credible. The clear irony here is that this ability, which springs from a failure to pursue self-interest, confers genuine advantages.
Granted, following through on these commitments will always involve avoidable losses not cheating when there is a chance to, retaliating at great cost even after the damage is done, and so on. The problem, however, is that being unable to make credible commitments will often be even more costly. Confronted with the commitment problem, an opportunistic person fares poorly.
Everyday Examples
Deterrence. Jones has a $200 leather briefcase that Smith cabinets. If Smith steals it, Jones must decide whether to press charges. If he does, he will have to go to court. He will get his briefcase back and Smith will spend 60 days in jail, But the day in court will cost Jones $300 in lost earnings. Since this is more than the briefcase is worth, it is clearly not in his material interest to press charges. (To eliminate an obvious complication, suppose Jones is about to move to a distant city, so deterrence is not a relevant consideration). Thus, if Smith knows that Jones is a rational, self interested person, he is free to steal the briefcase with impunity. Jones may threaten to press charges, but his threat will be empty.
Now suppose that Jones is not a pure rationalist; that if Smith steals the briefcase, Jones will become enraged, and think nothing of a day’s lost earnings, or even a week, in order to see justice done. If Smith knows that Jones will be driven by emotion, not reason, he will let the briefcase be. People expect us to behave rationally in response to theft of property, we will sell them need to behave irrationally in practice, because it is not in their interest to steal it. And predisposed to respond irrationally serves much better here than being guided only by material self interest.
Cheating. Two persons, Smith and Jones, can engage in a potentially profitable venture, say, a restaurant. Their potential for gain arises from the natural advantages inherent in the division and specialization of labor. Smith is a talented cook, but is shy and an incompetent manager. Jones, by contrast, cannot boil an egg, but is charming and has shrewd business judgment. Together, they have the necessary skills to launch a successful venture. Working alone, however, their potential is much more limited. Their problem is this: Each will have opportunities to cheat without possibility of detection. Jones can skim from the cash drawer without Smith’s knowledge. Smith, for his part, can take kickbacks from food suppliers. If only one of them cheats, he does very well. The non-cheater does poorly, but isn’t sure why. His low return is not à reliable sign of having been cheated, since there are many benign explanations why a business might do poorly. If the victim also cheats, he, too, can escape detection, and will do better than by not cheating; but still not nearly so well as if both had been honest. Once the venture is under way, self-interest unambiguously dictates cheating. Yet if both could make a binding commitment not to cheat, they would profit by doing so.
Bargaining. In this example, Smith and Jones again face the opportunity of a profitable joint venture. There is some task that they alone can do, which will net them $1000 total. Jones has no pressing need for extra money, but Smith has important bills to pay. It is a fundamental principle of bargaining theory that the party who needs the transaction least is in the strongest position. The difference in their circumstances thus gives Jones the advantage. Needing the gain less, he can threaten, credibly, to walk away from the transaction unless he gets the lion’s share of the take, say $800. Rather than see the transaction fall through, it will then be in Smith’s interest to capitulate. Smith could have protected his position, however, had he been able to make a binding commitment not to accept less than, say, half of the earnings. One possible way of accomplishing this would be to sign a contract that requires him to contribute $500 to the Republican party in the event he accepts less than $500 from his joint venture with Jones. (Smith is a lifelong Democrat and finds the prospect of such a gift distasteful.) With this contract in place, it would no longer be in his interest to give in to Jones’s threat. (If Smith accepted $200, for example, he would have to make the $500 contribution, which would leave him $300 worse off than if he hadn’t done the job with Jones at all.) Jones’s threat is suddenly stripped of all its power.
Marriage. As a final example of the commitment problem, consider the difficulty confronting a couple who want to marry and raise a family. Each considers the other a suitable mate. But marriage requires substantial investment, which each person fears could be undercut if the other were to leave for an even more attractive opportunity in the future. Without reasonable assurance that this will not happen, neither is willing to make the investments required to make the most of their marriage. They could solve their problem if they could write a detailed marriage contract that would levy substantial penalties on whichever of them attempted to leave. They are, after all, willing to forego potentially attractive opportunities in the future in order to make it in their interests to invest in the present effort of raising a family. It would serve their purposes to take steps now that would alter the incentives they face in the future.
Life, it seems, is rife with commitment problems.
Emotions as Commitment Devices
My claim is that specific emotions act as commitment devices that help resolve these dilemmas.
Retaliation and Deterrence. Consider a person who threatens to retaliate against anyone who harms him. For his threat to deter, others must believe he will carry it out. But if others know that the costs of retaliation are prohibitive, they will realize the threat is empty. Unless, of course, they believe they are dealing with someone who simply likes to retaliate. Such a person may strike back even when it is not in his material interests to do so. But if he is known in advance to have that preference, he is not likely to be tested by aggression in the first place.
Proportionality vs Bargaining. Similarly, a person who is known to “dislike” an unfair bargain can credibly threaten to walk away from one, even when it is in her narrow interest to accept it. By virtue of being known to have this preference she becomes a more effective negotiator.
Guilt vs Cheating. Consider, too, the person who “feels bad” when he cheats. These feelings can accomplish for him what a rational assessment of self-interest cannot–namely, they can cause him to behave honestly even when he knows he could get away with cheating. And if others realize he feels this way, they will seek him as a partner in ventures that require trust.
Love and Marriage. It is no surprise that the marriage problem is better solved by moral sentiments than by awkward formal contracts. The best insurance against a change in future material incentives is a strong bond of love. If ten years from now one partner falls victim to a lasting illness, the other’s material incentives will be to find a new partner. But a deep attachment will render this change in incentives irrelevant. (Indeed, research has shown the “active ingredient” of romantic and non-romantic attachment is derogation of alternatives).
Signaling Your Commitment
Emotions qua commitment devices would not have evolved unless a person can reliably signal possessing them. Consider:
One fall day, almost twenty years ago, black activist Ron Dellums was speaking at a large rally. But at least one young man was not moved by Dellums’s speech. He sat still as a stone on the steps of Sproul Plaza, lost to some drug, his face and eyes empty of expression. Presently a large Irish setter appeared, sniffing his way through the crowd. He moved directly to the young man sitting on the steps and circled him once. He paused, lifted his leg, and, with no apparent malice, soaked the young man’s back. He then set off again into the crowd. The boy barely stirred.
Now, the Irish setter is not a particularly intelligent breed. Yet this one had no difficulty locating the one person in that crowd who would not retaliate for being sprayed. Facial expressions and other aspects of demeanor apparently provide clues to behavior that even dogs can interpret. And although none of us had ever witnessed such a scene before, no one was really surprised when the boy did nothing. Before anything even happened, it was somehow obvious that he was just going to go right on sitting there.
Without doubt, however, the boy’s behavior was unusual. Most of us would have responded angrily, some even violently. Yet we already know that no real advantage inherent in this “normal” response. After all, once the boy’s shirt was soaked, it was already too late to undo the damage. And since he was unlikely ever to encounter that particular dog again, there was little point in trying to teach the dog a lesson. On the contrary, any attempt to do so would have courted the risk of being bitten.
Our young man’s problem was not that he failed to respond angrily, but that he failed to communicate to the dog that he was so predisposed. The vacant expression on his face was somehow all the dog needed to know he was a safe target. Merely by wearing “normal” expressions, the rest of us were spared.
There are numerous behavioral clues to people’s feelings. Posture, the rate of respiration, the pitch and timbre of the voice, perspiration, facial muscle tone and expression, and movement of the eyes, are among the signals we can read. We quickly surmise, for example, that someone with clenched jaws and a purple face is enraged, even when we do not know what, exactly, may have triggered his anger. And we apparently know, even if we cannot articulate, how a forced smile differs from one that is heartfelt. At least partly on the basis of such clues, we form judgments about the emotional makeup of the people with whom we deal. Some people we sense we can trust, but of others we remain forever wary.
Takeaways
A commitment problem is one where maximizing immediate material welfare is maladaptive in the long run.
A commitment device hijacks one’s own reward mechanism towards irrational behavior (insensitive to one’s material welfare).
Many emotions (including guilt, rage, love) and intuitions (including fairness) may be best seen as commitment devices.
A commitment device must be advertised to work effectively: the organism must emit (hard to fake!) signals of their presence.
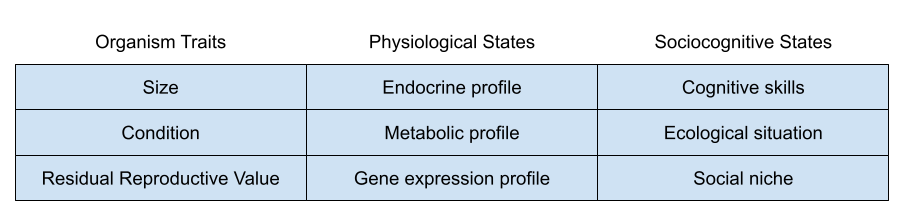
Across the life course, an organism must choose between somatic investment (growth, learning, maintenance) vs reproductive effort (parenting, alloparenting, mating). But there are also trade-offs within each of these investment categories. For example, within reproductive effort, should I emphasize mating or parenting?
We can reformulate these tradeoffs as current vs future reproduction, and offspring quantity vs quality. Due to sexual selection asymmetries, first trade-off tends to be more salient to females, and the second is more salient to males.
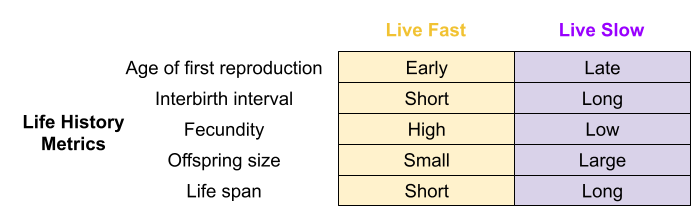
The effect of these tradeoffs can be detected in various life history (LH) traits:
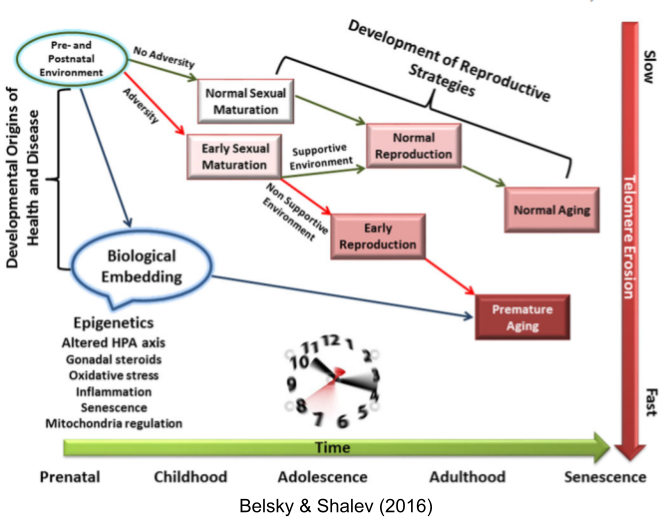
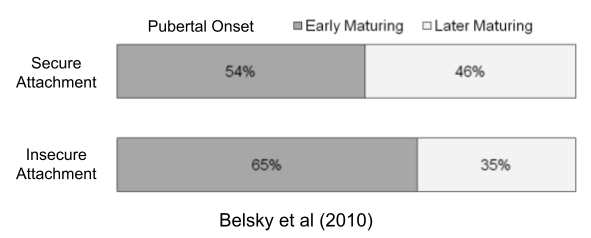
The disposable soma theory posits a causal chain: higher environmental mortality → prioritized reproductive effort → increased senescence. But faster aging also correlates with early puberty (Belsky & Shalev 2016). Perhaps both LH traits respond to the same life-history tradeoff?
If you compare all five life history traits from species-typical traits across all species, they all run together (Jeschke et al 2008).
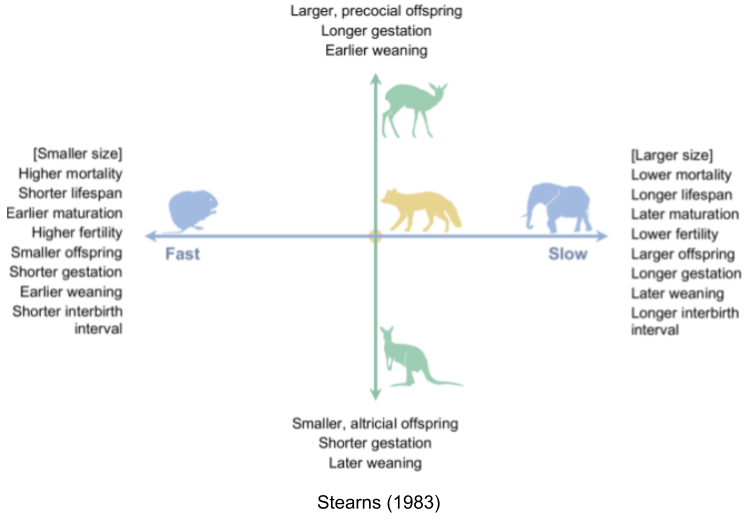
Fast species show early reproductive maturity and short lives. Semelparous species like salmon undergo “programmed death” immediately after reproduction.
Slow species live longer, and take more time to reach reproductive maturity. For example, iteroparous species like blue whales have extremely slow lifespans.
This is the fast-slow continuum. This is supported by comparative analyses in mammals (Bielby et al. 2007), birds (Saether 1988), reptiles (Bauwens & Diaz-Uriarte 1997), fish (Winemiller & Rose 1992), insects (Johansson 2000) and plants (Salguero-Gómez et al. 2016).
In fact, two components stand out in dimensionality reduction analyses. A fast-slow axis that accounts for 70-80% of the variance in the traits, and a precocial-altricial axis that explains 10-15% of the variance. While smaller species tend to be fast and vice versa, controlling for body size does not make the continuum disappear; rather, the respective variances change to 30-50% and 20-30% (Del Guidice 2020).
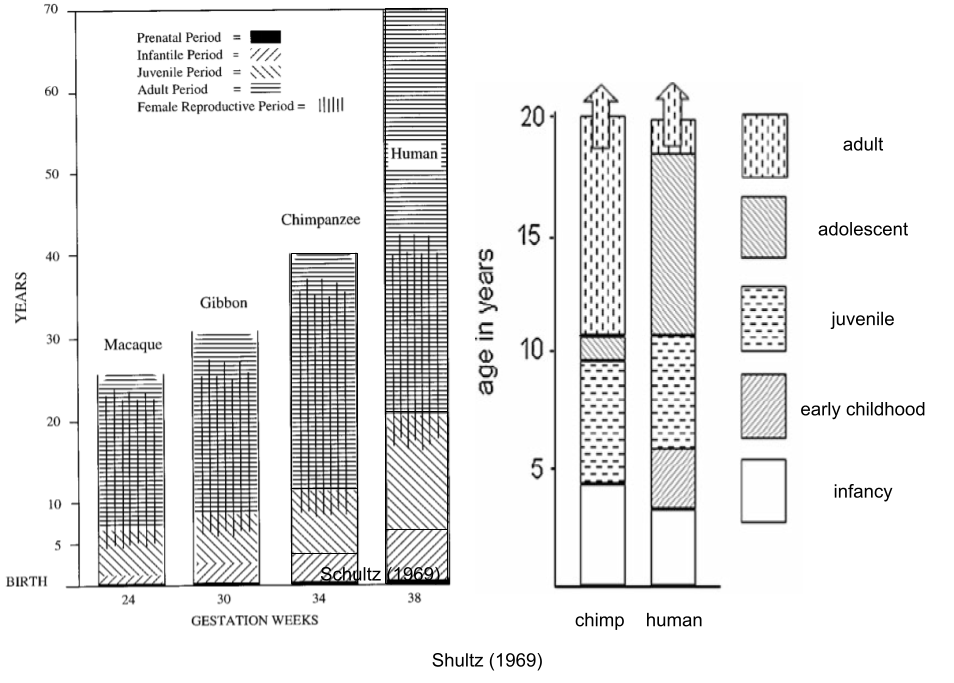
As an aside, our species presents a kind of exception to the fast-slow continuum! Human longevity is more “slow” than chimpanzees. But we also have a shorter interbirth interval, a “fast” characteristic. This energetic paradox is explained by a lifting of energetic constraints (somatic vs reproductive effort – why not both?). It was funded by an increase in human basal metabolic rate (Pontzer et al 2016); this expanded energy budget funded both increased reproductive output (some ~100 kcal per day) and somatic costs (larger brains, longer lifespans, etc).
Explaining The Continuum
The fast-slow continuum is a reliable empirical pattern. Why does it exist? What causes these interspecies differences in the pace of life (POL)?
In the 1970s, three US ecologists proposed the r/K theory of life history, which strove to explain it by appealing to population density and carrying capacity of the environment. But by the 1980s it was clear that carrying capacity could not explain the continuum.
Three theoretical approaches stand out:
Modern density dependent models (e.g., Engen & Sæther 2016) do away with carrying capacity, but extend classical r/K density concepts.
Allometric models (e.g., the metabolic theory of ecology in Brown et al 2004) can explain body size covarying with life history; but struggle to predict the continuum’s persistence after body size is partialed out.
Other models invoke extrinsic mortality (risk beyond an individual’s control). Extrinsic mortality affects LH traits only through modifying the intensity of competition: higher extrinsic mortality reduces the intensity of competition and vice versa (Andre & Rousset 2020).
But I haven’t yet encountered a “theory of everything” that integrates across these perspectives. Data in quantitative ecology tends to be rather sparse, making generalizations difficult.
Personality & Plasticity
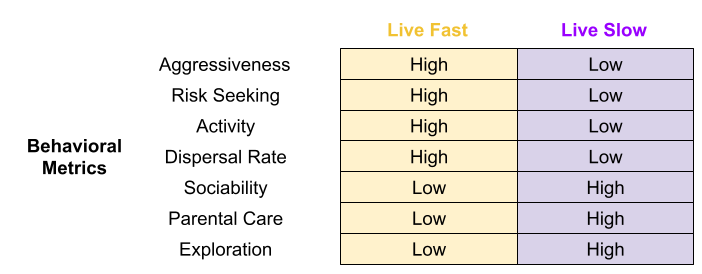
Let’s talk about animal personality. Numerous studies have found that some individuals are consistently bolder (Wilson et al 1994) or more aggressive (Johnson & Sih 2007) than others across multiple situations, and indeed that boldness and aggressiveness are often positively correlated (Bell & Sih 2007). Such behavioral syndromes have been seen in a wide range of taxa (Gosling 2001).
Why should animals have a personality as opposed to being completely flexible? Why are human personalities so pervasive that when someone is a behavioral chameleon, we often view them as psychopathic?
Behavior could be, in principle, completely flexible (i.e, an animal could be highly aggressive one moment, and then cautious shortly thereafter). But if optimal behavior is connected to a slow-changing state variable, then adaptive behavior should also be consistent over long periods. A few examples from Sih (2011):
Personality is thought to emerge from feedback loops between state and behavior (Sih et al 2015). Negative feedback tends to remove individual differences; positive feedback tends to accentuate them. A few more examples:
Individual differences are often grounded in genetics. For example, twin studies models suggest that 50-80% of the variance from pubertal onset is genetic (Rowe 2002). But the above data suggests a role for environmental influence. We must therefore model organism plasticity, or conditional adaptations in response to environmental conditions.
The Pace of Life Syndrome
Behavioral syndromes within species bear a striking resemblance to interspecific fast-slow differences. Links have been found:
… between aggressive, risky behaviors and high reproductive success but also to lower survival (Smith & Blumstein 2008). Found in bighorn sheep (Reale et al 2009) and red squirrels (Boon et al 2008).
… between aggressive individuals and dispersal (Dingemanse et al. 2003).
… between aggressive males and less parental care (Duckworth & Badyaev 2007).
… between sociability and reduced propensity to disperse (Cote et al 2010).
Perhaps the conditions that generate interspecific POLS also generate interindividual POLS. This working assumption is known as the ecological gambit. The gambit becomes riskier if causal factors are known to operate at one level of analysis, but not another (Pollet et al., 2014). But the assumption is not without support. Some density dependent models that explain species POLS concurrently explain individual differences (Wright et al 2019). Finally, the Andre & Rousset (2020) model shows that extrinsic mortality influences individual, not just species, differences in life histories.
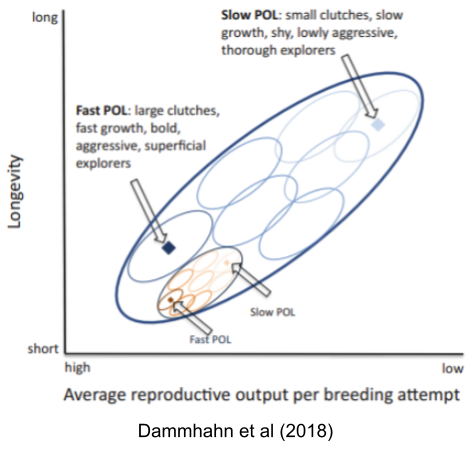
We can visualize the relationship between species and individual-level pace of life with the following cartoon. The biggest dark-blue oval represents the entire fast-slow continuum, the smaller blue ovals each represent a species, and the yellow ovals represent communities or individuals within a given species.
Behavior co-evolves with anatomy. If an individual’s body decays more quickly (preferentially investing resources into growth and reproductive effort), we should expect that individual to adopt different behaviors. Fast bodies should exhibit behaviors such as aggressiveness (especially in the context of intrasexual contest competition), and risk seeking. In fact, many behavioral metrics arguably conform to the fast-slow continuum.
Most sections in this article are fairly uncontroversial. However, the topics of this section are more contentious. Not everyone agrees that POLS can be applied to individuals and behaviors; some prefer to keep the analysis to average traits across species.
Evaluating the Syndrome
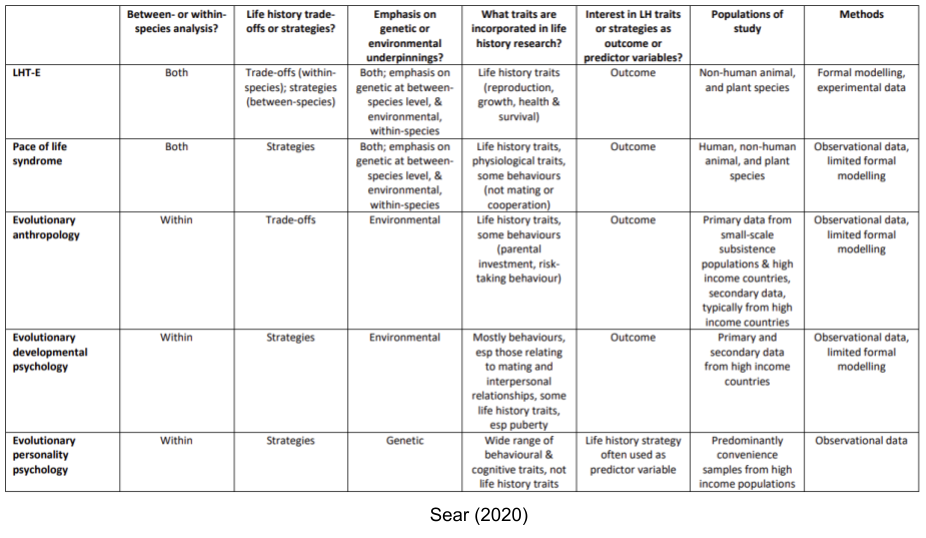
Life history theory (LHT) can be usefully understood as two sub-disciplines, whose literatures operate largely independently of one another (Nettle and Frankenhuis 2019)
LHT-E, or life history theory as practiced in ecology and evolutionary biology.
LHT-P, or life history theory as practiced in evolutionary psychology.
LHT-E tends to focus on the POLS traits across species. Within LHT-P, there are four separate movements, with decreasing levels of contact with evolutionary biology: pace of life syndrome research, evolutionary anthropology, evolutionary developmental psychology, and evolutionary personality psychology.
One of the strongest criticisms of LHT-P is its reliance on verbal models in lieu of formal models. As argued by Stearns & Rodrigues (2020), our capacity to develop complex verbal arguments is limited (the chamber of consciousness is small!). Our intuition often misleads, and the sensitivity of predictions to their underlying assumptions is not easy to see within informal arguments.
For example, Darwin’s several attempts to explain verbally the evolution of 50:50 sex ratios were unsuccessful: “I now see that the whole problem is so intricate that it is safer to leave its solution for the future” (Darwin 1874, pp. 259, 260). This problem was later solved in a few lines of algebra (Edwards 1998, 2000).
Another important criticism is a reliance on questionable assumptions of “extrinsic mortality”, which too often conflates random vs condition-dependent forms of environmental mortality.
The fast-slow continuum seems to be settled science. But animal personality research in general, and POLS in particular, is on empirically shaky ground (Mathot and Frankenhuis 2018). Yet I suspect more conservative examples of LHT-P are worth attending to.
But the construct seems to explain a great deal of physiology. Chronic stress may not be a disease; it may canalize the fast phenotype.
Chronic Stress vs. Pubertal Onset
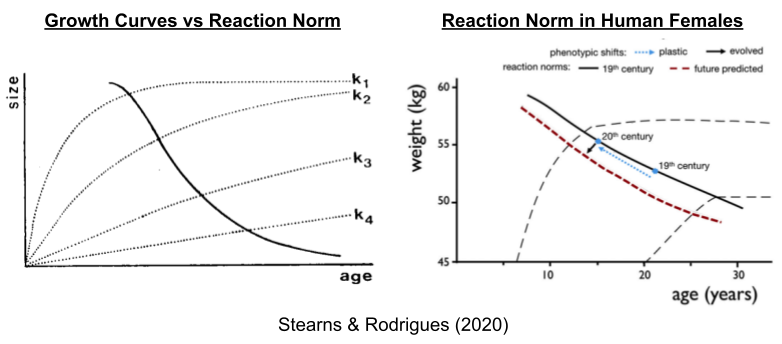
The development of individual organisms is subject to ecological factors that drive interspecific differences. Human females, for example, can experience rapid (k1) or slow (k4) somatic growth. Each growth curve corresponds to a different optimal age of reproductive maturity; the solid line denotes this reaction norm.
Compared to the 19th century, women have become younger and taller at age of maturity (Worthman 1999). This secular trend has been most intense within groups of low socioeconomic status (SES) (e.g., Abioye-Kuteyi et al 1997). This class effect only pertains to countries where low SES groups do not suffer from systematic malnutrition and disease (it is absent in e.g., Denmark Helm & Lidegaard 1989). Interestingly, the link between nutrition and earlier puberty may be partially mediated by fiber content in the diet (Koo et al 2002). Other physical stressors can delay female puberty. While some exercise promotes androgens (Elias 1981), professional athletes often experience delayed puberty (e.g., Bale et al 1996).
Taken together, the shift up the reaction norm occurred with the Industrial Revolution and its concomitant energy surplus. Higher activity in the HPG axis is associated with earlier puberty; which may explain why levels of testosterone are also higher in developed countries (Henrich 2020 pp 551).
But some stressors can have the opposite effects. Survivors of the Great Sichuan earthquake were twice as likely to experience early puberty than controls (Lian et al 2018; see also Pesonen et al 2008). And more generally, a substantial literature indicates that early exposures to childhood adversities (e.g., socioeconomic adversity, childhood attachment, heightened parent–child conflict, father absence) tend to predict earlier pubertal development in females (Ellis 2004).
How to reconcile these findings? It seems like pubertal timing is contingent firstly on health and nutrition (see especially Kyweluk et al. 2018) and secondly, when these are adequate, on socioemotional conditions (Coall & Chisholm 2003).
Biological Substrate
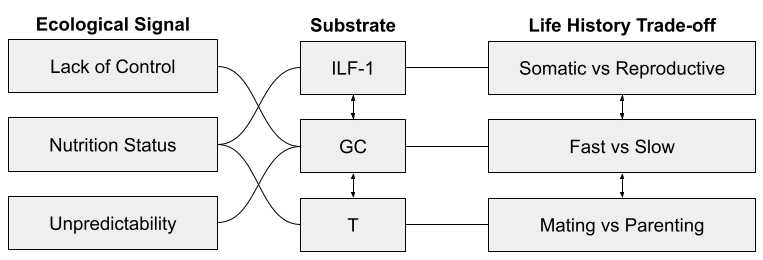
Recall the big life history tradeoffs faced by organisms:
Three endocrine systems are involved in these dimensions:
I’ve previously noted how insulin-like growth-factor 1 (IGF-1) seems involved in the tradeoff between somatic and reproductive effort. It is especially responsive to nutritional status.
I have elsewhere noted how glucocorticoids (GC), and the stress response system (SRS) more generally, seem to mediate fast and slow phenotypes. The SRS is especially responsive to unpredictability and lack of control.
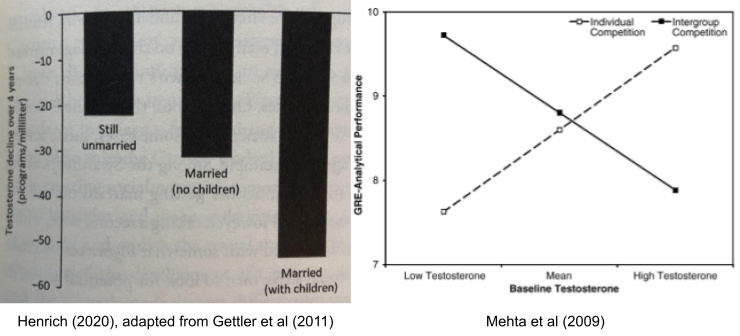
Finally, testosterone (T) plays a role in mating vs parenting decisions, at least in males. Testosterone drops substantially after marriage, and again on the birth of a child. It also appears to promote intragroup competition, consistent with sexual selection theory:
It may be worth exploring interactions between these different endocrine systems as they unfold across development.
Until next time.
References
Abioye-Kuteyi et al (1997). The influence of socioeconomic and nutritional status on menarche in Nigerian school girls
Andre & Rousset (2020). Does extrinsic mortality accelerate the pace of life? A barebones approach
Baams et al (2015). Transitions in body and behavior: a meta-analytic study on the relationship between pubertal development and adolescent sexual behavior
Bale et al (1996). Gymnasts, distance runners, anorexics body composition and menstrual status.
Belsky et al (2010). Infant attachment security and the timing of puberty: testing an evolutionary hypothesis
Belsky & Shalev (2016). Contextual adversity, telomere erosion, pubertal development, and health: two models of accelerated aging, or one?
Bergmuller et al (2010). Animal personality due to social niche specialization
Boon et al (2008). Personality, habitat use, and their consequences for survival in North American red squirrels (Tamiasciurus hudsonicus).
Brown et al (2004). Toward a metabolic theory of ecology
Clark (1994). Antipredator behavior and the asset protection principle.
Cote et al (2010). Social personalities influence natal dispersal in a lizard.
Dall et al (2012). An evolutionary ecology of individual differences.
Dammhahn et al (2018)
Del Guidice (2020). Rethinking the Fast-Slow Continuum of Individual Differences
Dingemanse et al (2003) Natal dispersal and personalities in great tits (Parus major).
Duckworth & Badyaev (2007). Coupling of dispersal and aggression facilitates the rapid range expansion of a passerine bird.
Elias (1981). Serum cortisol, testosterone, and testosterone-binding globulin responses to competitive fighting in human males
Ellis (2004). Timing of pubertal maturation in girls: an integrated life history approach
Engen & Sæther (2016). Optimal age of maturity in fluctuating environments under r- and K-selection
Gettler et al (2011). Cortisol and Testosterone in Filipino Young Adult Men: Evidence for Co-regulation of Both Hormones by Fatherhood and Relationship Status
Helm & Lidegaard (1989). The relationship between menarche and sexual, contraceptive, and reproductive life events
Henrich (2020). The WEIRDest people in the world: how the West became psychologically peculiar and particularly prosperous
Jeschke et al (2008) r-Strategist/K-strategists.
Koo et al (2007). A cohort study of dietary fibre intake and menarche
Kyweluk et al (2018). Menarcheal timing is accelerated by favorable nutrition but unrelated to developmental cues of mortality or familial instability in Cebu, Philippines.
Lian et al (2020). The impact of the Wenchuan earthquake on early puberty: a natural experiment
Mathot and Frankenhuis (2018). Models of pace-of-life syndromes (POLS): a systematic review
Mehta et al (2009). When are low testosterone levels advantageous? The moderating role of individual versus intergroup competition
Nettle & Frankenhuis (2020). Life-history theory in psychology and evolutionary biology: one research programme or two?
Pollet et al (2014). What can cross-cultural correlations teach us about human nature?
Pontzer et al (2016). Metabolic acceleration and the evolution of human brain size and life history
Pesonen et al (2008). Reproductive traits following a parent-child separation trauma during childhood: a natural experiment during World War II.
Reale et al (2009). Male personality, life-history strategies and reproductive success in a promiscuous mammal
Reale et al (2010). Personality and the emergence of the pace-of-life syndrome concept at the population level
Sear (2020). Do human ‘life history strategies’ exist?
Stearns & Rodrigues (2020).
Shultz (1969). The life of primates
Smith & Blumstein (2008). Fitness consequences of personality: a metanalysis.
Stearns (1983). The influence of size and phylogeny on patterns of covariation among life-history traits in the mammals.
Worthman (1999). Evolutionary perspectives on the onset of puberty.
Wright et al (2019). Life-history evolution under fluctuating density-dependent selection and the adaptive alignment of pace-of-life syndromes
Two research traditions provide very different accounts of hippocampal function:
Cognitive Account: The hippocampus has been linked to spatial navigation (reviewed here) and declarative memory.
Emotional Account: The hippocampus has been linked to the behavioral inhibition system, and its correlate – anxiety.
This situation is exacerbated by the radical simplicity of hippocampal circuitry. Buzsaki & Tingley (2018) attempt to unify the cognitive account, by exploring equivalencies between memory and navigation (both rely on sequential representations, with memory as “internal navigation at an attention-derived velocity”). But the cognitive and emotional strands are more difficult to reconcile. Strange et al (2014) attributes cognitive function to dorsal, and emotional function to ventral hippocampus. And there is strong lesion evidence in rats (Bannerman et al 2004) and neuroimaging studies in humans to support this view. It has a grain of truth.
But theta oscillations are found throughout the dorso-ventral axis. Yet these accounts attribute both emotional and cognitive properties to theta. This is puzzling. Is it reasonable to expect anxiety to lessen if running speed is reduced?
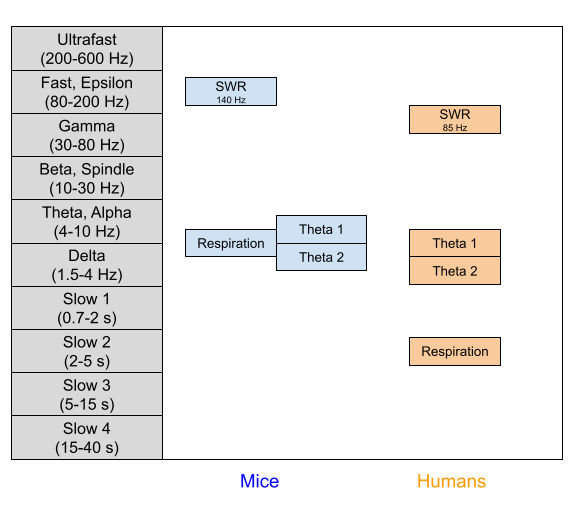
Varieties of Theta
Korotkova et al (2017) adduce evidence that cognitive and emotional elements contribute to the slope and y-intercept of theta, respectively. This dissociation was predicted by the Burgess (2008) model, which received empirical support in Wells et al (2013). These separate contributions to theta also cohere with developmental measures: large changes in intercept occurring between day 18 and 24 of the rat, despite much slower, gradual changes in slope (Wills et al., 2010).
But theta is not unitary. More precisely, the theta frequency band contains more than one oscillator. In rats, rabbit, and guinea pigs, two types of theta have been identified (Sainsbury & Montoya 1983). We recently found both oscillators in human neurosurgery patients (Goyal et al 2020), with very similar functional properties.
Type 1 Theta (~9 Hz in rats, ~8 Hz in humans). Correlates with movement speed, and dependent on entorhinal cortex
Type 2 Theta (~6 Hz in rats, ~3 Hz in humans). Does not correlate with movement speed.
The Respiration Oscillator
Theta is not the only biomarker relevant to behavioral inhibition. The hippocampus is also home to another rhythm entrained to breathing (Tort et al 2018). This respiration oscillator has been found in rat hippocampus (Lockmann et al 2016), and respiration-locked activity has been found in human cortex (Perl et al 2019). Beta oscillators peak at inspiration onset (Kluger & Gross 2021), which may explain why most voluntary behaviors are also initiated during this phase (Park et al 2020). Importantly, slow breathing promotes parasympathetic activity, mitigating the sympathetic arousal associated with BIS anxiety. This may mediate the health benefits provided by breath-centric meditation.
The nucleus incertus is one of four nuclei known to modulate theta rhythms, and it preferentially projects to the ventral hippocampus (Ma & Gundlach 2015). Within this nucleus, relaxin-3-positive neurons can be excited by the stress hormone corticotropin releasing factor (CRF) (Ma et al 2013). This constitutes a direct link between the stress response and hippocampal theta. This neuronal population also participates in respiratory activity (Furuya et al 2020), which strikes me as suggestive.
References
Bannerman et al (2004). Regional dissociations within the hippocampus–memory and anxiety
Burgess (2008). Grid cells and theta as oscillatory interference: theory and predictions
Buzsaki & Tingley (2018). Space and time: the hippocampus as a sequence generator
Furuya et al (2020). Relaxin-3 receptor (RXFP3) mediated modulation of central respiratory activity
Goyal et al (2020). Functionally distinct high and low theta oscillations in the human hippocampus
Korotkova et al (2017). Reconciling the different faces of hippocampal theta: the role of theta oscillations in cognitive, emotional and innate behaviors
Lockmann et al (2016). A Respiration-Coupled Rhythm in the Rat Hippocampus Independent of Theta and Slow Oscillations
Ma et al (2013). Heterogeneous responses of nucleus incertus neurons to corticotrophin-releasing factor and coherent activity with hippocampal theta rhythm in the rat.
Ma & Gundlach (2015). Ascending control of arousal and motivation: role of nucleus incertus and its peptide neuromodulators in beharioral responses to stress
Park et al (2020). Breathing is coupled with voluntary action and the cortical readiness potential
Sainsbury & Montoya (1983). The relationship between type 2 theta and behavior
Strange et al (2014). Functional organization of the hippocampal longitudinal axis
Tort et al (2018). Respiration-entrained brain rhythms are global but often overlooked
Wells et al (2013). Novelty and anxiolytic drugs dissociate two components of hippocampal theta in behaving rats.
Wills et al (2010). Development of the hippocampal cognitive map in preweanling rats