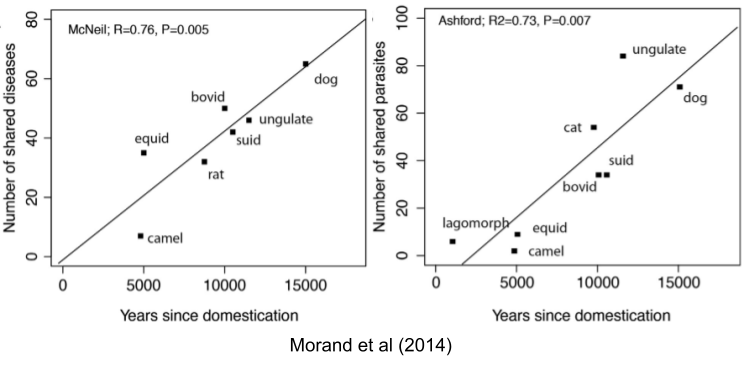
Eating mammal meat (aka red meat) promote chronic disease in humans, but not other animals. Why? Malaria uses the biochemical used to digest red meat – sialic acid – as a vehicle to enter primates. Some 4mya, a mutation altered Australopith sialic acid. The mutation helped our ancestors evade malaria!
Ultimately, of course, malaria caught up & regained the ability to infect us. Why has the sialic acid degradation been maintained since then? Domesticated mammals are a big source of disease. The longer they have been with us, the more “C19-like” zoonotic events have occurred. Living with domesticates has its benefits, but also increases risk of disease. Perhaps the inflammation produced by eating red meat provides some additional protection from mammal-born diseases. Such adaptive tuning of the immune system may increase inflammatory protection – only where it’s most needed.
In general, when getting vaccinated or boosted, you may consider a morning appointment. Immune response is literally twice as strong in the morning for most people. Like everything else in the body, the immune system fluctuates at a circadian rhythm.
Human RCT supports the “gravitostat” theory of fat mass regulation. Wearing a weighted vest 8h/d for 3 weeks caused fat loss. Possibly a parallel regulatory pathway to the one involving leptin.
More evidence for the role of persistent organic pollutants (POPs) in the sperm crisis.
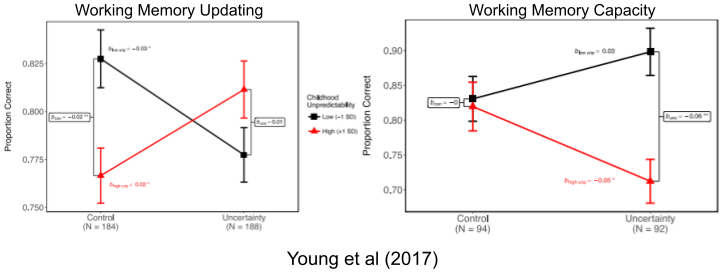
Poverty damages mental & physical health via chronic stress. But chronic stress isn’t exactly a disease. It can mold the child to make the best of a bad situation. Chronic stress damages working memory capacity (aka fluid intelligence). But poverty also IMPROVES flexibility & updating! In unpredictable environments with rapidly changing statistics, it should be advantageous to rapidly update information about the immediate environment. But retrieval and capacity are more beneficial in predictable environments, where past experiences will likely apply to the future. Study, replication.
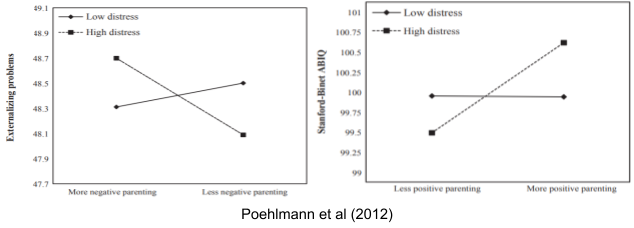
Some people (the Specialists) have strong, fixed personalities. Others (the Generalists) have weaker personalities, and adapt more to early life experience. Childcare quality doesn’t affect everybody. Specialist kids aren’t affected much by your parenting. Their genetic program is locked in. “Resilience” comes at a cost. But the Generalist kids! These are the ones at an advantage if are born in a happy home, and profoundly disadvantaged otherwise.This is the differential susceptibility model, aka “biological sensitivity to context”.
Did the sclera (whites of the eyes) evolve as a cooperative device, to share attentional information? The argument against.
UV vision in birds. Recall the evolution of color vision in primates: where duplication of long-range conopsin extended the dichromat ancestral pattern. Birds historically perceive a wider frequency range. A good example of umwelt.
AI
Most integrals are intractable (life is hard), so we must often integrate numerically. Sadly, numerical integrators are unreliable & computationally expensive. Why not use ML as a numerical method? Introducing Probabilistic Numerics.
GitHub CoPilot has been released, an ML tool that will help you write code for $10/month.
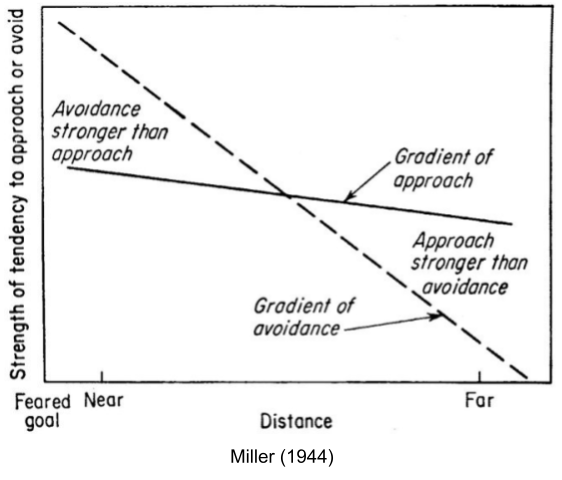
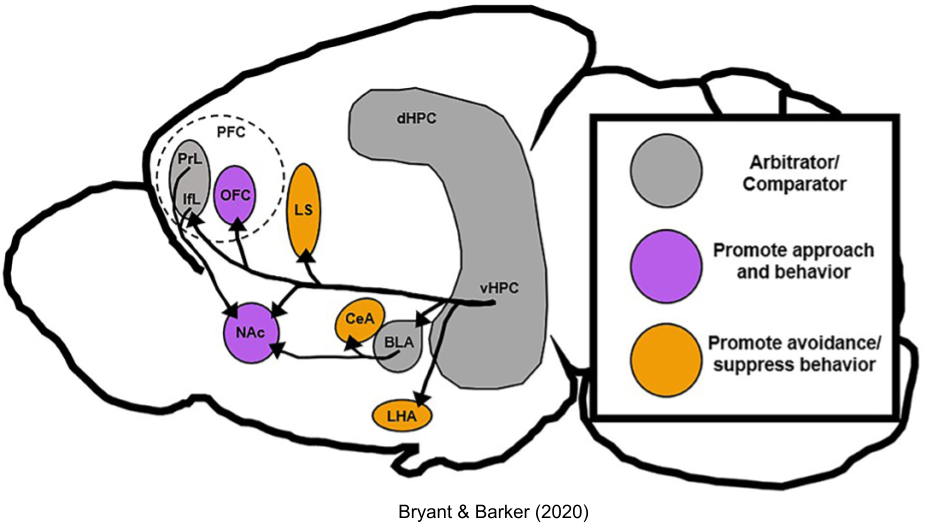
One might venture that approach and avoidance are produced by a unitary system. But early behaviorist experiments showed that the strength of avoidance decreased at a greater rate than that of approach (Miller 1944). If you present food and shock together in an alley at the appropriate volumes, the approach system will dominate… until the rat gets close enough for its avoidance system to counterbalance. The result: fidgeting. Drugs like sodium amylobarbitone can modify the location of the conflict point. These data suggest, distinct systems control approach and avoidance behaviors.
The stress response system (SRS) is not synonymous with “fight or flight”. As we noted previously, the SRS engages behavioral effectors to address challenges to homeostasis. Behavioral effectors include avoidance – but they also include approach (e.g., foraging). Let us call the distinction between approach vs avoidance the bivalent motivation theory.
What about anxiety? Several theorists have sought to locate anxiety within the avoidance system. But anxiety dissociates from fear. Panicolytic drugs, which mimic amygdala lesions, mitigate fear but not anxiety. Anxiolytic drugs, which mimic hippocampal lesions, mitigate anxiety but not fear (Blanchard et al. 1997).
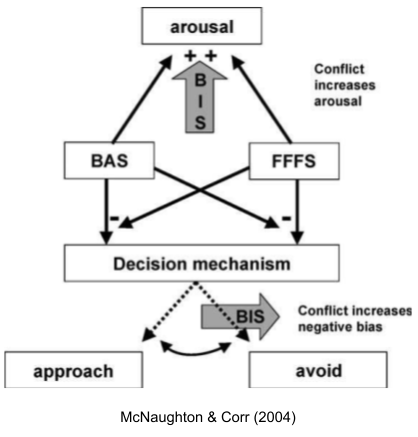
Gray & McNaughton (2004) argue that in some cases (novel objects, ambiguous social contexts) can concurrently activate the approach and avoidance systems. Rather than risking a disorganized response, this conflict resolution system is activated, and performs two functions:
To suppress prepotent behavior candidates generated by the approach and avoidance systems.
To elicit risk assessment behaviors to disambiguate the situation. And indeed, anxiolytic drugs suppress risk assessment behaviors (Blanchard et al 2011).
We will be referring to these three systems often.
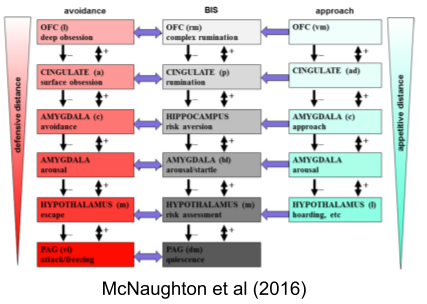
The avoidance system is also called the fight, flight, or freeze system (FFFS).
The approach system is also called the behavioral activation system (BAS).
The conflict resolution system is also called the behavioral inhibition system (BIS).
While much exploration occurs in a context of safety, BIS-mediated explorations are conducted in situations of high risk. Thus, the BIS promotes physiological arousal and the stress response, to prepare the body for a potential emergency. Finally, the BIS increases negative bias by sensitizing the FFFS avoidance system, which may reduce the risk of further wasteful approach-avoidance conflict.
Reactivity vs Coping Style
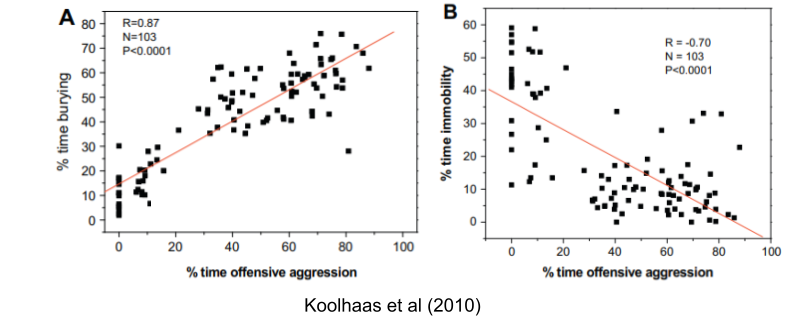
Koolhaas et al (2010) describe two coping styles: proactive coping (boldness) and reactive coping (shyness). These traits are consistently expressed in the same individual at different times and in different situations. For example, proactive individuals who response aggressively to resident intruders are more likely to produce defensive behavior in a burying test two weeks later.
Reactive coping is also associated with individual differences in behavioral flexibility and impulse control! To me, this suggests reactive coping is analogous to an overactive BIS (although de Boer et al 2017 deny reactive coping relates to anxiety, nor the primary role of hippocampus).
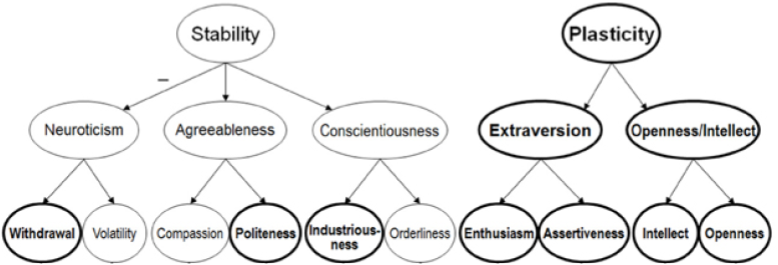
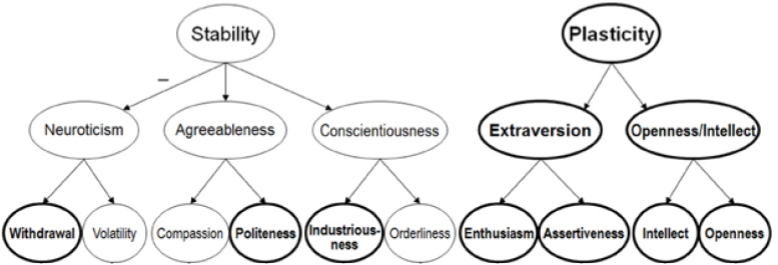
Most well-known personality tests have poor statistical reliability… except one. The Big 5 (OCEAN) theory of personality explains large amounts of behavioral variation. Factor analyses reveal a hierarchy (DeYoung et al 2007):
Neuroticism is associated with reactivity of the HPA axis. It has two major subfactors:
Withdrawal reflects risk of anxiety and depression;
Volatility a disposition towards irritability, anger, and emotional lability.
Koolhaas et al (2010) present a 2D model, with the HPA axis playing a role in reactivity, and serotonin playing a role in coping style. This nicely dovetails the personality constructs above.
Withdrawal (reactive coping) has been attributed to an overactive BIS system. In developmental psychology, this has been studied in children with behavioral inhibition (BI; see Kagan et al 1984), analogous to adult shyness (Barker et al 2018).
High BI children produce a larger startle (Barker et al 2014), and enhanced amygdala activity (Cremers et al 2010): sensitized avoidance.
High BI adults exhibit faster responses to both reward and punishment (Hardin et al 2006): sensitized approach (Helfinstein et al 2012).
Why does shyness occur? BIS only activates when the BAS and FFAS conflict. If both mechanisms expand, conflict occurs more frequently.
Evolution of Bivalence
These systems are extraordinarily ancient and conserved across phyla (Elliot & Covington 2001). In unicellular organisms, movement is dictated by gradients, such as foraging initiated by immediate chemical gradients in the immediate surroundings. While the representation capacities of these systems have clearly increased, the basic dichotomy persists.
Cisek (2021) proposes that bivalent motivation was a central organizing principle of neural evolution.
He also argues that
Contralateral innervation evolved to support the avoidance system: if a predator is sensed by the left hemisphere, the animal needs to move to the right and vice versa.
The approach system implemented winner-take-all decision-making, whereas the avoidance system is implements averaging. If you spot two predators, your escape vector should integrate both of them. But if you find two foraging patches, it is optimal to only approach one.
Biological Substrate
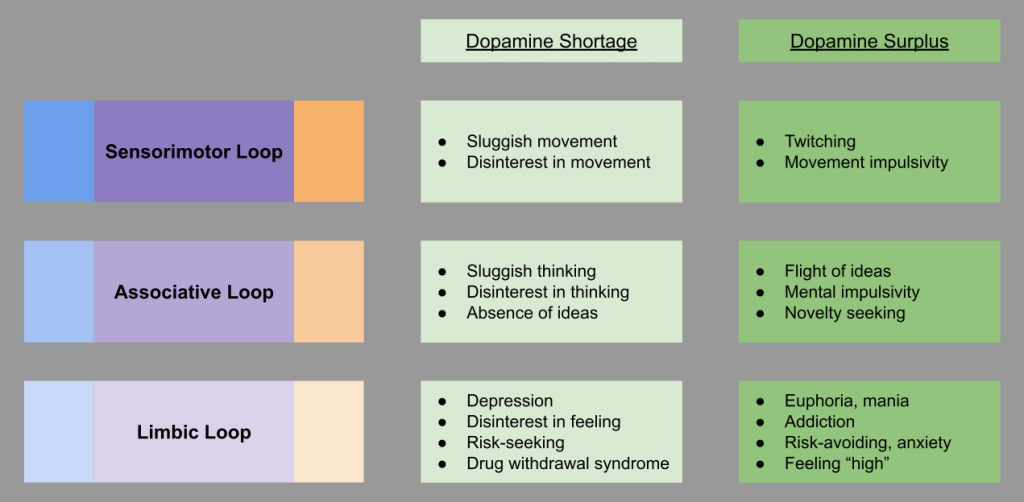
For the BAS approach system, tonic dopamine in the basal ganglia plays a central role in motivating approach. This is clearly seen in neurological conditions (Krack et al 2010):
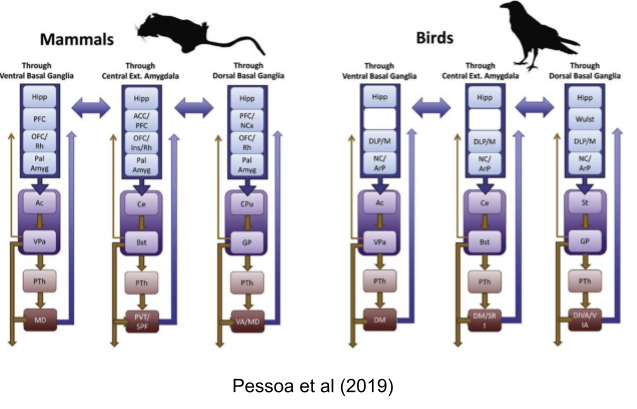
The FFAS avoidance system is grounded in the central amygdala and the bed nucleus of the stria terminalis (BNST). Just as the approach system calculates reward, the lateral habenula calculates antireward. This extended amygdala loop interoperates with the three “classical” basal ganglia loops above:
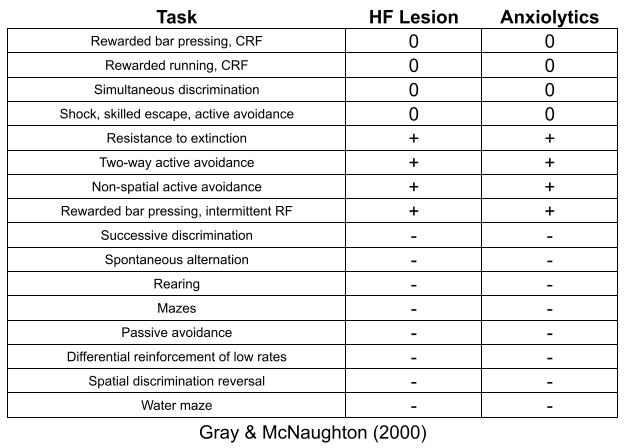
The BIS conflict detection system is closely associated with the septo-hippocampal system (Gray & McNaughton 1980). Anxiolytic drugs bear a strong resemblance to hippocampal lesions.
Of course, the cortex also plays an important role. Consider the pregenual cingulate (a.k.a. BA 25, or prelimbic cortex). This region has been implicated in depression (Pizzagalli 2011), addiction (Goldstein et al 2009), OCD (Fitzgerald et al 2005), and PTSD (Kasai et al 2008). While most of this surface had equal numbers of approach- and avoidance- representing neurons, one particular subregion (ventral pregenual anterior cingulate cortex, vPgACC) was predominated by avoidance processes.
Stimulation of vPgACC altered the decision boundary for approach-avoidance tasks, where the rat had to choose whether to experience food and an aversive airpuff, but not approach-approach tasks where the rat had to choose between two different kinds of food. These effects were cumulative: avoidance became increasingly pronounced as the number of stimulation trials increased. Finally, the effect of this region evaporated on administration of antianxiety drugs (Amemori & Graybiel 2012).
The striatum contains patches of cells (striosomes) in an otherwise homogenous population (matrix). The matrix appears to be only responsive to benefits; whereas the striosomes evaluates costs and benefits when both values are high. Striosomes in the dorsomedial associative striatum receive input preferentially from vPgACC, and their activity also changes the decision boundary by increasing loss aversion (Friedman et al 2015). Striosomes project gorgeous bouquets (Crittenden et al 2015) into the dopaminergic substantia nigra pars compacta (SNpc), which mediates their impact on decision making.
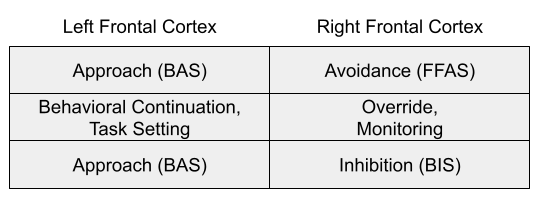
Lateralization in Frontal Cortex
In the cortex, some of the underlying mechanisms appear to be lateralized.
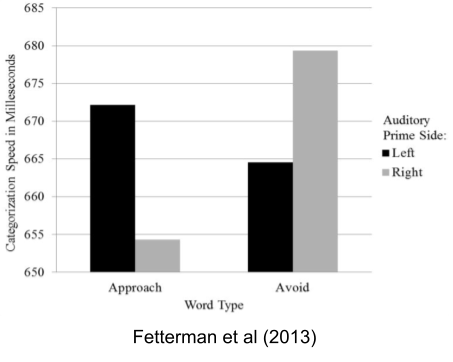
One tradition argues that the left frontal cortex participates in approach; the right in avoidance (Fetterman et al 2013; Carver & Harmon-Jones 2009).
Chemical suppression (via amytal injection) to the left hemisphere produced depression; right injections produce mania. (Terzian 1964).
Lesions to the left hemisphere produce depression, lesions to the right hemisphere produce mania (Robinson & Price 1982).
Experiments which elicit reward processes create left-asymmetric activity; punishment created right-biased activity (Coan & Allen 2004)
Personality differences in approach and avoidance are predicted by resting EEG asymmetries (Davidson 1999)
Another tradition argues that left vs right reflects behavioral continuation vs override (Wacker et al 2008), or task setting vs monitoring (Stuss & Alexander 2007). Both traditions seem close to convergence on the left hemisphere. I wonder if there might exist some middle ground, where the right hemisphere participates in the other avoidance system (BIS).
Right frontal theta is uniquely sensitive to approach-avoidance conflict, and is more pronounced in people suffering anxiety disorder (Shadli et al 2021). Such goal conflict-specific rhythmicity (GCSR) is now being used as a biomarker for anxiety disorder.
Consider posing asymmetries. The left side of the face is more active during emotional expression (Borod et al 1997). This explains why people prefer to show (and view) the left side of the face, and why people instructed to hide their emotions preferentially display the right.
The right hemisphere theory attributes perception & performance of all emotions to the right hemisphere. But there appears to be a second lateralization effect compatible with bivalent motivation (Demaree et al 2005). While on average the left hemiface is more expressive for all emotions, the left-bias was stronger for negative emotions, and weaker for positive emotions (Borod et al 1997).
Humans preferentially turn rightward in the (approach) act of kissing (Gunturkun 2003).
In general, left-hemisphere dominance for handedness and language might be compatible with a general specialization for routine action control (MacNeilage 1998), and can be reconciled with the postural origins theory of handedness (MacNeilage 2007).
The study of lateralization suffers several limitations:
The shadow of mythology looms large (McManus 2018), exemplified in popular brainedness theories (e.g. Jaynes 1976, McGilchrist 2009).
The comparative biology data of handedness is equivocal.
The difference scores method in comparing hemispheric activity is contentious.
These data often only permit macro-scale descriptions (“frontal cortex”), which inevitably conflate meso- and micro-scale structural circuits.
I have not found a unifying theory to explain the relationship of lateralization effects across domains.
Yet these low-resolution data still suggest to me a left-bias for approach, and a right-bias for avoidance.
Hierarchical Organization
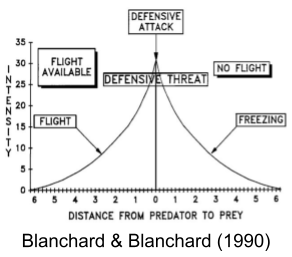
Stimulating avoidant nuclei in the hypothalamus produces fight, flight, or freezing. These behaviors depend not on the location of the probe, but on the context of the animal’s environment. Blanchard & Blanchard (1990) showed that considerable behavioral variation can be explained by defensive distance:
Defensive distance is more nuanced than physical distance. In a more dangerous situation, a greater real distance will be required to achieve the same defensive distance. Likewise, with a braver individual, a smaller real distance will be required to achieve the same defensive distance.
The behavioral hierarchy is driven by defensive distance. More distant threats produce slower, sophisticated defenses; more proximal threats produce faster, cruder defense mechanisms (Blanchard & Blanchard 1990). These are:
Undirected escape (emotional correlate: dread)
Directed escape (emotional correlate: panic)
Active avoidance (emotional correlate: fear and phobias)
Discriminated avoidance (which might include complex emotions such as guilt)
Recall the neural hierarchy: the further from the brainstem, the more conceptual the representations. Graeffe (1994) argues the behavioral hierarchy is isomorphic to a neural hierarchy, with phylogenetically newer structures layered on top of older systems. This is the hierarchical defense system.
The central amygdala supports fear conditioning (Le Doux 1994). Defense systems lower in the hierarchy do not support such learning, but directly respond to dangerous stimuli.
Just as BAS and FFFS are organized hierarchically, McNaughton & Corr (2004) argue the same for BIS:
Economics and Emotion
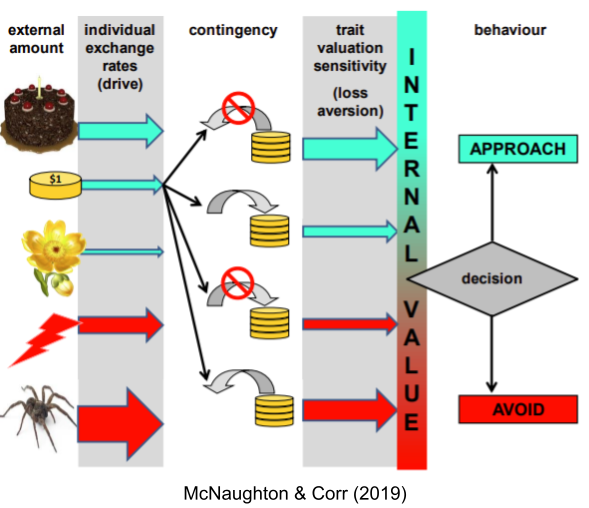
It is important to distinguish between valuation and motivation. Specific visceral states dynamically alter individual valuations (this is alliesthesia). But even holding visceral deprivation constant, there are individual differences in valuation sensitivity. In behavioral economics, the ratio of positive to negative sensitivity is known as loss aversion.
Loss aversion is not the same as repulsion sensitivity. Individual differences in valuation and motivation vary independently.
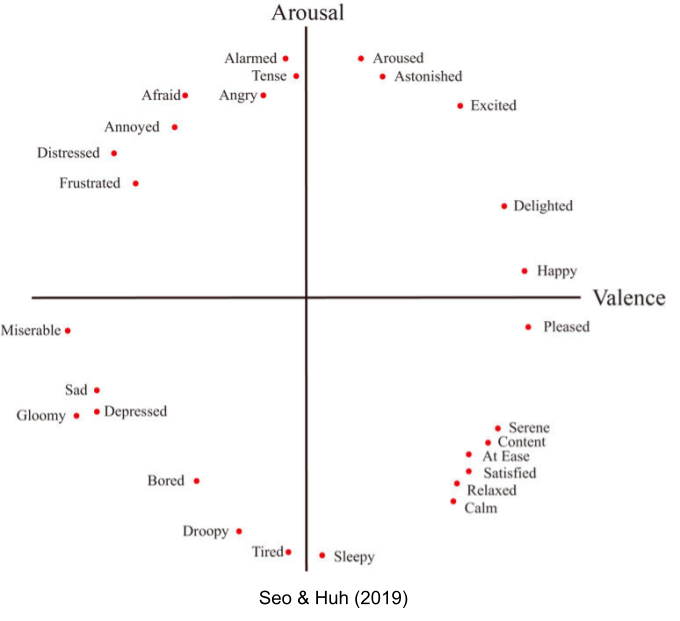
Modular theories of emotion (e.g Panksepp 1998) envision distinct neural circuitry for each basic emotion. In contrast, constructivist theories explore emotional states as emergent properties from a few core dimensions. The latter have been heavily influenced by Russel (1980) circumplex model, which organizes emotional experience into two dimensional space.
Approach/avoidance theorists are more aligned with dimensional models. But rather than interpreting valence as one-dimensional (bipolar), they claim each object is simultaneously attributed a positive and a negative valence score (bivalenced). Ambivalence is universal. Psychological evidence (van Harreveld et al 2004) and neural evidence (Man et al 2017) suggests brains retain multiple representations of valence. For example, the basolateral nucleus of the amygdala (BLA) contains three subpopulations of neurons: positive valence, negative valence, and arousal (Shabel & Janak 2009).
Barker et al (2014). Individual Differences in Fear Potentiated Startle in Behaviorally Inhibited Children
Borod et al (1997). Neuropsychological aspects of facial asymmetry during emotional expression: A review of the normal adult literature
Blanchard et al (1997). Differentiation of anxiolytic and panicolytic drugs by effects on rat and mouse defense test batteries
Blanchard & Blanchard (1990). An ethoexperimental analysis of defense, fear and anxiety.
Bruno & Bertamini (2013). Self-Portraits: Smartphones Reveal a Side Bias in Non-Artists
Calabrese (2010) L’arte dell’autoritratto: storia e teoria di un genere pittorico
Carver & Harmon-Jones 2009. Anger is an approach-related affect: evidence and implications.
Cisek (2021). Evolution of behavioural control from chordates to primates.
Coan & Allen (2004). Frontal EEG asymmetry as a moderator and mediator of emotion.
Corr (2008). The reinforcement sensitivity theory of personality.
Cremers et al (2010). Neuroticism modulates amygdala-prefrontal connectivity in response to negative emotional facial expressions
Crittenden et al (2015). Striosome–dendron bouquets highlight a unique striatonigral circuit targeting dopamine-containing neurons
Davidson (1999). Neuropsychological perspectives on affective styles and their cognitive consequences
Demaree et al (2005). Brain lateralization of emotional processing: historical roots and a future incorporating “dominance”
d’Alfonso et al (2000). Laterality effects in selective attention to threat after repetitive transcranial magnetic stimulation at the prefrontal cortex in female subjects
de Boer et al (2017). Untangling the neurobiology of coping styles in rodents: towards neural mechanisms underlying individual differences in disease susceptibility
DeYoung et al (2007). Between Facets and Domains: 10 Aspects of the Big Five
Depue & Collins (1999). Neurobiology of the structure of personality: Dopamine, facilitation of incentive motivation, and extraversion
Elliot & Covington (2001). Approach and avoidance motivation
Fetterman (2013). For Which Side the Bell Tolls: The Laterality of Approach-Avoidance Associative Networks
Fitzgerald et al (2005). Error-related hyperactivity of the anterior cingulate cortex in obsessive-compulsive disorder
Friedman et al (2015). A Corticostriatal Path Targeting Striosomes Controls Decision-Making under Conflict
Goldstein et al (2009). Anterior cingulate cortex hypoactivations to an emotionally salient task in cocaine addiction
Gray & McNaughton (1980). The Neuropsychology of Anxiety (first edition)
Gray & McNaughton (2004). The Neuropsychology of Anxiety (second edition)
Graeff (1994). Neuroanatomy and neurotransmitter regulation of defensive behaviors and related emotions in mammals.
Gunturkun (2003). Adult persistence of head-turning asymmetry
Helfinstein et al (2012). Approach-withdrawal and the role of the striatum in the temperament of behavioral inhibition
Jaynes (1976). The Origin of Consciousness in the Breakdown of the Bicameral Mind
Kagan et al (1984). Behavioral inhibition to the unfamiliar
Kasai et al (2008). Evidence for acquired pregenual anterior cingulate gray matter loss from a twin study of combat-related posttraumatic stress disorder
Koolhaas (2010). Neuroendocrinology of coping styles: towards understanding the biology of individual variation.
Krack et al (2010) Deep brain stimulation: from neurology to psychiatry
Le Doux (1994). Emotion, memory, and the brain
MacNeilage (2007). Present status of the postural origins theory
MacNeilage (1998). Towards a unified view of cerebral hemispheric specializations in vertebrates.
Man et al (2017). Hierarchical brain systems support multiple representations of valence and mixed affect.
McGilchrist (2009). The Master and His Emissary: The Divided Brain and the Making of the Western World
McManus (2019). Half a century of handedness research: myths, truths; fictions, facts; backwards, but mostly forwards
McNaughton & Corr (2004). A two-dimensional neuropsychology of defense: fear/anxiety and defensive distance.
McNaughton et al (2016). Approach/Avoidance
Miller (1944). Experimental studies of conflict.
Mueller et al (2014). Dopamine modulates frontomedial failure processing of agentic introverts versus extraverts in incentive contexts
Panksepp (1998). Affective neuroscience
Perl et al (2019). Human non-olfactory cognition is phase locked with inhalation
Pessoa et al (2019). Neural architecture of the vertebrate brain: implications for the interaction between emotion and cognition
Pizzagalli (2011). Fronto cingulate dysfunction in depression: towards biomarkers of treatment response
Robinson & Price (1982). Post-stroke depressive disorders: a follow-up study of 103 patients.
Russel (1980). A circumplex model of affect
Seo & Huh (2019). Automatic Emotion-Based music classification for supporting intelligent IoT applications.
Shabel & Janak (2009). Substantial similarity in amygdala neuronal activity during conditioned appetitive and aversive emotional arousal
Shadli et al (2021). Right frontal anxiolytic‑sensitive EEG ‘theta’ rhythm in the stop‑signal task is a theory‑based anxiety disorder biomarker
Siegel & Victoroff (2009). Understanding human aggression: New insights from neuroscience
Smillie (2008). What is Reinforcement Sensitivity? Neuroscience Paradigms for Approach-avoidance Process Theories of Personality
Stuss & Alexander (2007). Is there a dysexecutive syndrome?
Terzian (1964). Behavioral and EEG effects of intracarotid sodium amytal injection
Wacker et al (2008). Is running away right? The behavioral activation-behavioral inhibition model of anterior asymmetry.
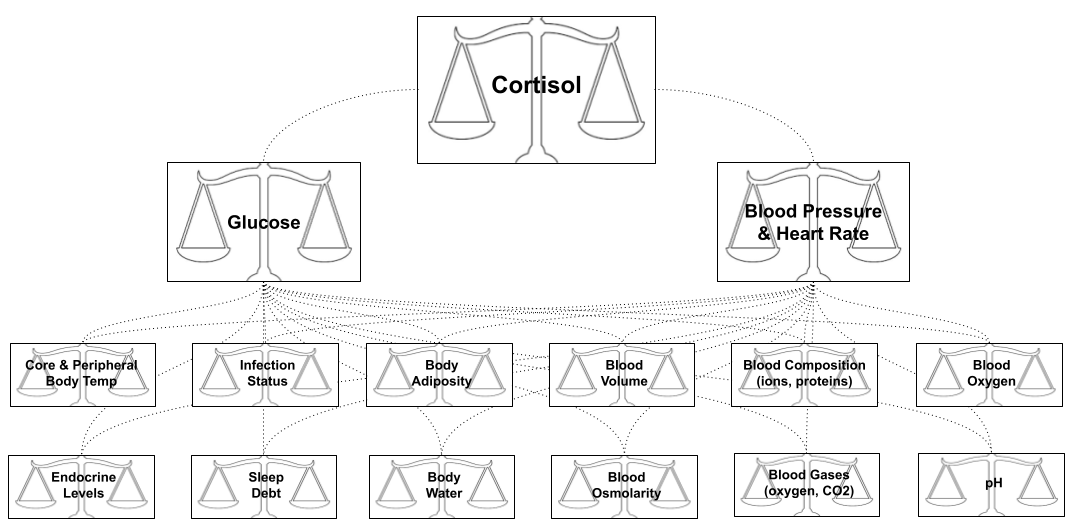
We have previously learned how the brain engages in biological defense of physiological balance points conducive to life. For example, temperature is regulated by deploying both internal effectors (e.g., shivering, goose flesh, vasoconstriction) and external effectors (i.e., seeking warmth in the environment).
On this view, a stressor is anything in the outside world that knocks you out of homeostatic balance, and the stress-response is what your body does to reestablish homeostasis.
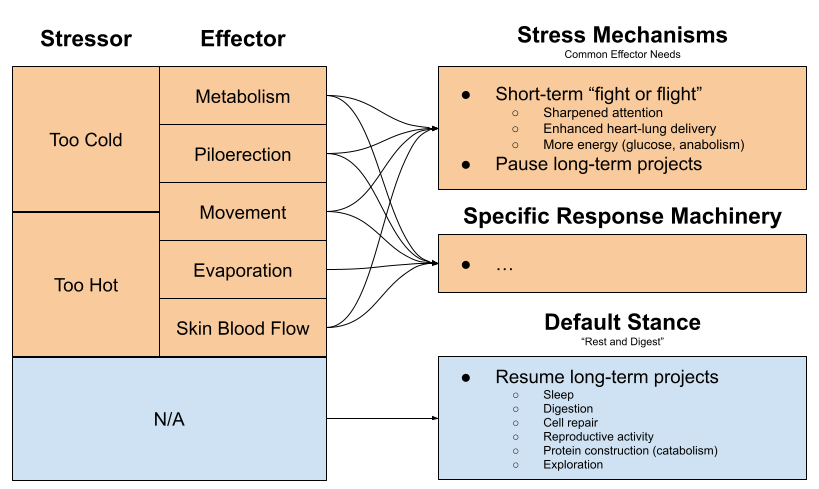
What happens when the organism is severely stressed? Hunting your prey, being hunted, fighting for females, freezing to death, and having sex each levy unique behavioral demands. But they also require many things in common:
Sharpened attention & faster reflexes
High heart rate & blood pressure to enhance blood supply to the organs.
More energy (more glucose in the bloodstream, intracellular anabolism) to subsidize rapid movement.
Pausing long-term projects (e.g., digestion consumes 10-20% of the mammalian energy budget)
What happens when an organism is comfortable? We might predict these effectors to be offline, and bodily resources to be engaged in projects with long-term benefits: sleep, digestion, cell repair, reproductive activity, protein construction (catabolism) etc.
The stress response is not identical to physiological actions required to sustain life. But it is the embodiment of overlapping needs within the effector ecosystem. Call this the effector overlap theory of stress. The generality of the stress response explains why its discoverer Selye dubbed it the General Adaptation Syndrome.
The above account distinguishes between short-term emergencies versus long-term projects. On the life history theory of stress, stress involves postponing long-term projects. We can see this in semelparous species like salmon or which evolved to die immediately after reproduction. These salmon die from a prolonged stress response. Remove their overactive adrenal gland, and they are suddenly able to live for another year.
We previously distinguished between reactive vs predictive homeostasis. On the overlap theory, it should not be surprising that the stress response also exhibits a predictive, circadian component.
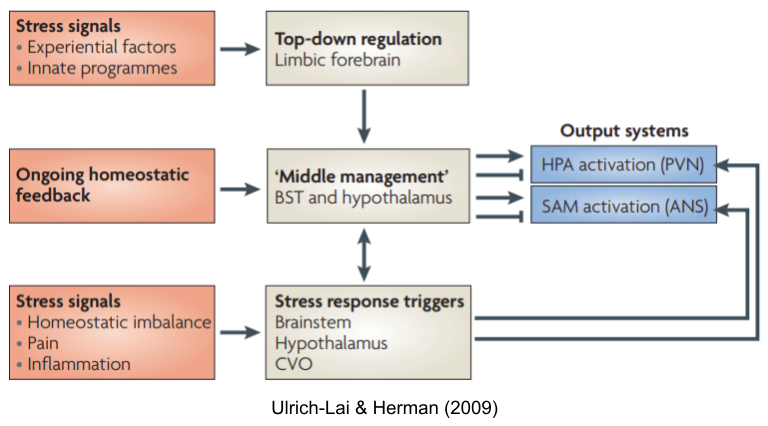
The Anatomy of Stress
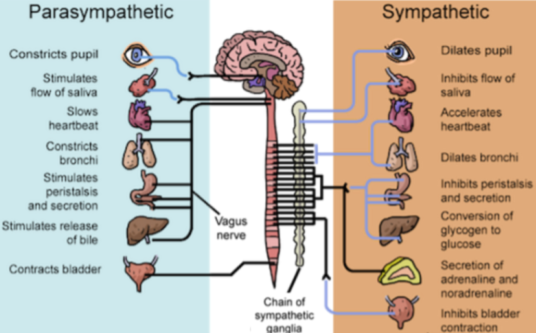
This basic dichotomy manifests in the parasympathetic (PNS) “rest and digest” and sympathetic (SNS) “fight or flight” systems. Nearly every organ is dually innervated by both systems, with the vagus nerve carrying most parasympathetic signals, and the sympathetic trunk mediating sympathetic signals. Moreover, these two subsystems often constitute opponent processes; that is, they exhibit functional antagonism.
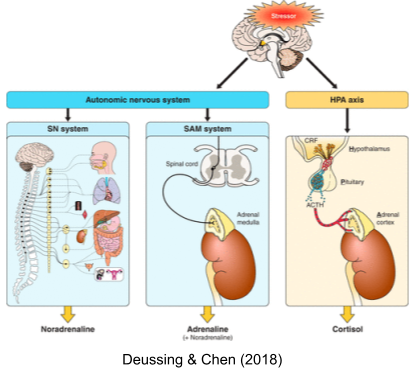
But the stress response involves more than just the SNS. We have previously introduced circumventricular organs (CVOs), which puncture the blood-brain barrier in a controlled way. These organs provide neuroendocrine integration. There are many neuroendocrine axes, including HPG (reproduction), HPT (metabolism) and HPS (growth). The hypothalamus-pituitary-adrenal (HPA) axis also regulates levels of glucocorticoids (cortisol in humans). Stressors also evoke other hormonal responses, including
glucagon (energy mobilization),
prolactin (suppressing reproduction),
endorphins (blunting pain perception), and
vasopressin (mediating the cardiovascular stress response)
osteocalcin (inhibits the parasympathetic branch) Berger et al (2019).
Another branch coordinates activity between SNS and HPA: the sympathomedullary (SAM) pathway.
The affective dimension of arousal involves increased alertness to sensory stimuli, increased motor activity and increased emotional reactivity (Pfaff, 2006). Levels of arousal typically vary in a circadian fashion, but various events, including exposure to a stressor, can rapidly increase arousal levels. The orexin system appears to mediate the relationship between stress and arousal in the brain (Berridge et al 2010).
In periphery, norepinephrine (NE) and acetylcholine (ACh) mediate the SNS and PNS, respectively. In the brain, loosely speaking, these same neuromodulators are associated with arousal and learning. A good example of core-periphery functional consilience.
Taken together, these systems (SNS, HPA axis, SAM, etc) are known as the stress response system (SRS).
Stress Signatures
There are two kinds of stress response
Interoceptive (systemic) stress, where the body detects homeostatic imbalance. Related to reactive homeostasis.
Exteroceptive (psychogenic) stress, or predicted future dysregulation. Related to predictive homeostasis.
These forms of stress are handled differently by the brain,
There are two kinds of stress responses:
Bodily stress response (e.g., physical exercise). Mediated primarily by noradrenaline via the SNS system.
Mental stress response (e.g., working memory tasks). Mediated primarily by adrenaline via the SAM system.
Many interoceptive stressors require bodily responses, whereas some exteroceptive stressors only require mental responses.
The Experience of Stress
Our experience frequently toggles between these two systems. As Sapolsky (2004) writes:
If you are a growing kid and you have gone to sleep, your parasympathetic system is activated. It promotes growth, energy storage, and other optimistic processes. Have a huge meal, sit there bloated and happily drowsy, and the parasympathetic is going like gangbusters. Sprint for your life across the savanna, gasping and trying to control the panic, and you’ve turned the parasympathetic component down.
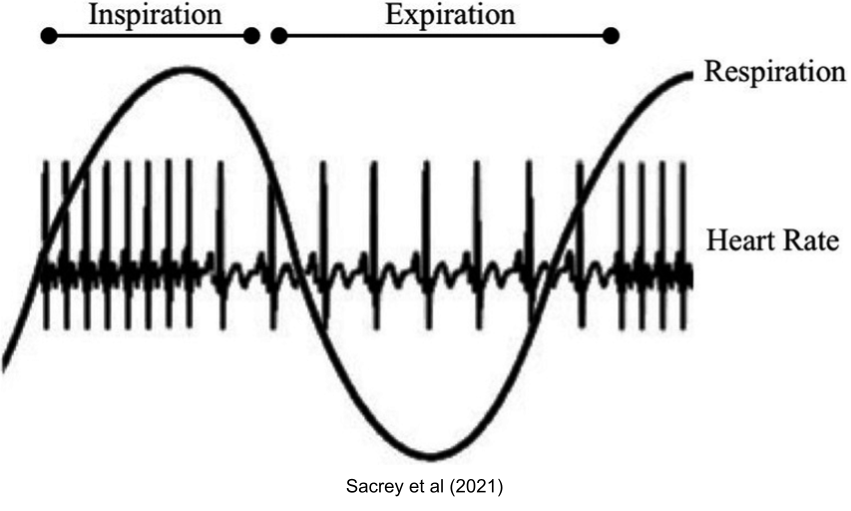
The interplay between the autonomic nervous system is visible in respiration. The PNS is dominant during exhalation, and stress response is more active during inhalation. This may explain why exhalation-focused breathing (with low inhalation/exhalation ratio) can promote calmness.
The interface between SNS and PNS is also well described during sexual intercourse:
To get an erection, a guy has to be calm, vegetative, and relaxed. What happens next, if you are male? You are having a terrific time with someone. Maybe you are breathing faster, your heart rate has increased. Gradually, parts of your body are taking on a sympathetic tone. After a while, most of your body is screaming sympathetic while, heroically, you are trying to hold on to the parasympathetic tone in that one lone outpost as long as possible. Finally, when you can’t take it anymore, the parasympathetic shuts off at the penis, the sympathetic comes roaring on, and you ejaculate.
The pain system is a competition between fast pain and slow pain (Hopkin 1997). Only the former promotes the stress response – they motivate you to quickly move away from the source of the piercing pain. What the slow fibers are about is getting you to hunker down so you can heal.
Stress can also cause analgesia (pain desensitization, e.g., a runner’s high), because your body secrets beta endorphins which mitigate objective pain perception in the spinal cord (Guillemin et al 1977). But when the stress response tilts towards anxiety, stress-induced hyperalgesia can occur via promoting subjective pain perception (Price 2000).
Heart attacks are much more likely to occur when the SRS is activated. So are flare-ups from autoimmune diseases like multiple sclerosis. Withdrawal and excessive drug use can be blocked by CRF antagonists, which speak to the intimate relationship between addiction and stress.
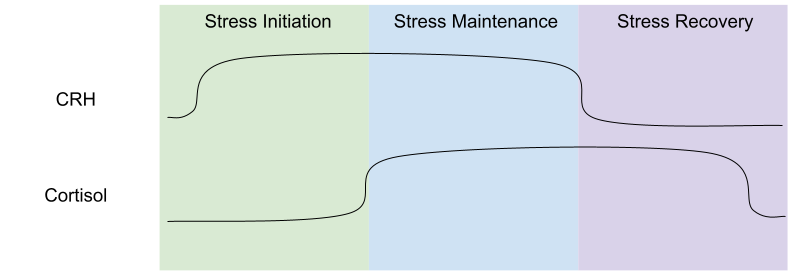
Three Phases of the Stress Response
These systems work at different timescales. SNS responds to stressors immediately, but cortisol changes occur within a few minutes. One can usefully model three phases of the stress response: stress initiation (high CRH, low cortisol), stress maintenance (high CRH and cortisol), and stress recovery (low CRH, high cortisol).
CRH inhibits eating (hypophagia), but cortisol promotes it (hyperphagia). The phase model of stress helps us make sense of this seemingly inefficient tension: eating is inhibited during the first two phases (high CRH), but promoted during stress recovery (low CRH). This explains why people exposed to long, continuous stressors (inhabiting the middle phase) tend to lose weight; whereas people with frequent, intermittent stressors (spending more time in recovery phase) tend to gain weight.
For those reactive to stress, stress eating can cause problems. Cortisol hypersecretors are most likely to be hyperphagic after stress (Epel et al 2001), and they disproportionately favor comfort foods (Dallman et al 2003). These people are more likely to have visceral fat (Epel et al 2000), which is much more harmful than subcutaneous fat (Welin et al 1987). This is because glucocorticoids are disproportionately expressed in the abdomen (Rebuffe-Scrive et al 1990), and are activated during stress recovery.
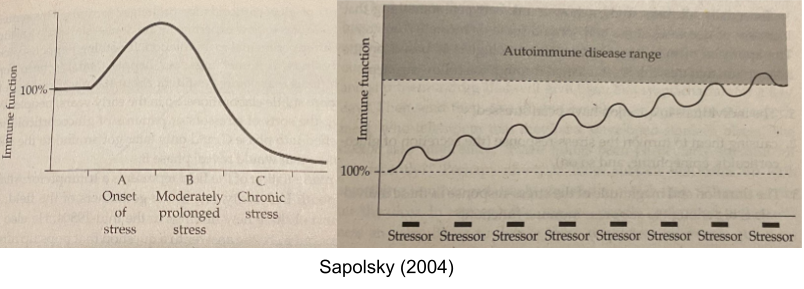
A similar trade off occurs in the immune system. The beginnings of stress response (first 30min) promotes immune function, but after a while (past 1h mark) stress has an immunosuppressant effect. This explains why long, continuous stressors suppress the immune system; whereas frequent, intermittent stressors stimulate the immune system and over time increases the risk of autoimmune disorders (e.g., asthma or multiple sclerosis). This explains why putting people “on steroids” (giving them massive amounts of cortisol) can protect against autoimmune disorders, and yet flare-ups of autoimmune symptoms are also yoked to stress.
Herpesviruses establish latency, which means they hide inside cells and only replicate when they are at an advantage. Their DNA contains a glucocorticoid sensor – when the virus detects elevated GCs, it knows the immune system is temporarily suppressed & it comes out of latency. The virus can even artificially induce an SRS response via your hypothalamus.
Chronic Stress and Senescence
While today’s discussion is at the systems level, the SRS also interacts with intracellular mechanisms. As we will explore next time, individual differences in chronic stress may involve differential rates of senescence. For example, individuals exposed to chronic stress show signs of accelerated biological aging, such as telomere erosion (Humphreys et al 2012).
Many mechanistic theories of senescence appeal to metabolic functions of the mitochondria. And chronic stress has been shown to reduce mitochondrial energy production capacity (Picard & McEwen 2018).
The reactive oxidative species (ROS) theory of senescence appeals to intracellular oxidative stress, not to be confused with systemic psychological stress. But chronic psychological stress does seem to promote oxidative stress (Aschbacher et al 2013), which may explain its role in accelerated aging.
Stress reactivity (larger, slower-fading GC response to stressors) is caused by chronic stress. The Big-5 personality trait of Neuroticism is a crucial moderator of reactivity (Zobel et al 2004)
The Volatility facet of Neuroticism, analogous to Hostile Type A personalities, produces an increased risk of cardiovascular disease (CVD) (Williams & Litman 1996). The link seems causal (Friedman et al 1996). Amusingly, the link between Type A and CVD seems to have been first discovered by an upholsterer in a cardiologist’s office: “…what on earth is wrong with your patients?”:
Stress is involved in age-related diseases like general inflammation, and CVD. However, GC seems to not play a causal role in another age-related disease: cancer. Another endocrine system implicated in senescence, insulin-like growth factor-1 (IGF-1), is more involved in cancer risk.
Stressor Determinants: Predictability and Control
Gradual-onset ulcers are caused by an acid-resistant bacteria known as helicobacter pylori (Dooley & Cohen 1988). Yet, while nearly all of us have the disease, only 10% of us develop ulcers. Stress is one of the lifestyle factors which inhibits repair of the stomach lining, and hence increases risk of ulceration (Levenstein 1998). Ulceration is thus a useful operationalization of stress, and you can explore intricacies of the SRS by measuring gastric lesions.
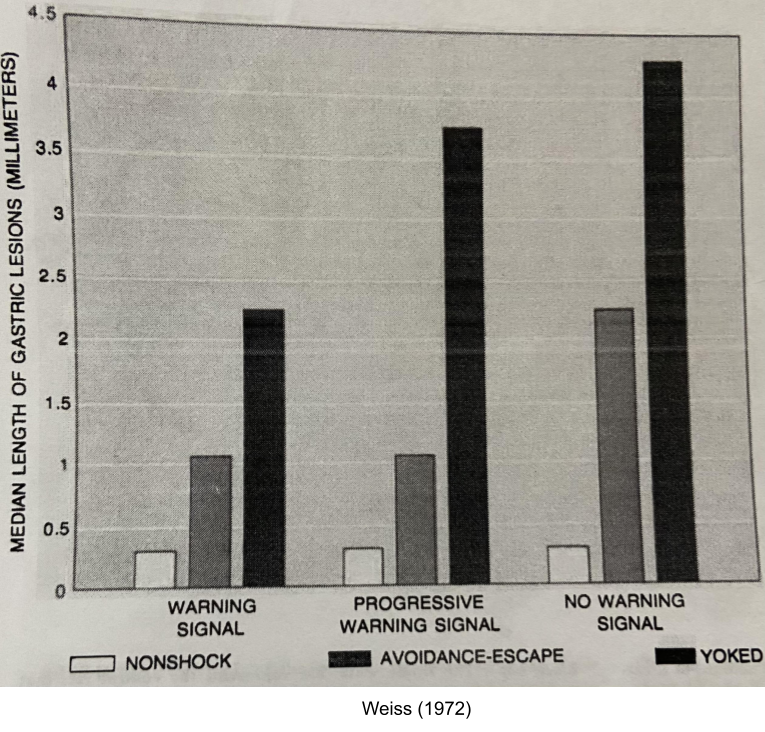
Weiss (1972) hooked mice to receive tail shock every minute in a continuous 21-hour session. His work sheds light on psychological mechanisms of coping.
Predictability: if you give a warning tone before the shock, rats experience less stress (left vs right column)
Control: give a lever to stop its shock and a “yoked” neighbor, the rat will experience less stress (gray vs black bar).
Foreknowledge: early foreknowledge of shock worsens stress only in rats with no control (left vs middle column).
Predictability can drive SRS magnitude, independent of the physiological implications:
Random interval feeding is associated with stronger SRS response than fixed intervals in rats.
Stressor habituation reduces the response to predictable stressors. Parachute jumpers eventually experience no stress as they move through their training (Ursin et al 1978).
In WW2, nightly air raids in cities produced fewer ulcers than infrequent & unpredictable suburban bombings (Stewart & Winser 1942).
Uncontrollability can shut down the SRS. Overmeier & Leaf (1965) discovered that dogs exposed to uncontrollable stressors were later unable to learn a shock-avoidance task, one that controls were easily able to master. Such learned helplessness has tight links to major depression (Seligman 1975). Polyvagal theory interprets this as Jacksonian dissolution: if the SRS fails, the nervous system will fall back to the dorsal vagus.
White (1959) described the desire for control as a motivational drive for competence. As behaviorism was supplanted during the Cognitive Revolution, Rotter (1966) reformulated the theory as locus of control: attitudes of self-control are associated with positive outcomes in myriad facets of daily life (Lefcourt 1992). People’s ratings of self-efficacy are better predictors of future behavior than their past behaviors (Bandura 1977). Self-efficacy also controls effort. When faced with difficulties, people who doubt their abilities quickly give up; people who don’t ratchet up their effort (Bandura & Cervone 1983)
These led to the attributional reformulation of learned helplessness; with its three parameters of explanatory style:
Locus: is the cause internal to the self, or external?
Consistency: are the causes stable over time, or not?
Scope: are the causes global, or specific?
A person with a depressive style (habitually invoking internal, stable, and global factors to explain failures) is most at risk of becoming depressed in the face of uncontrollable circumstances.
Outlets for Frustration
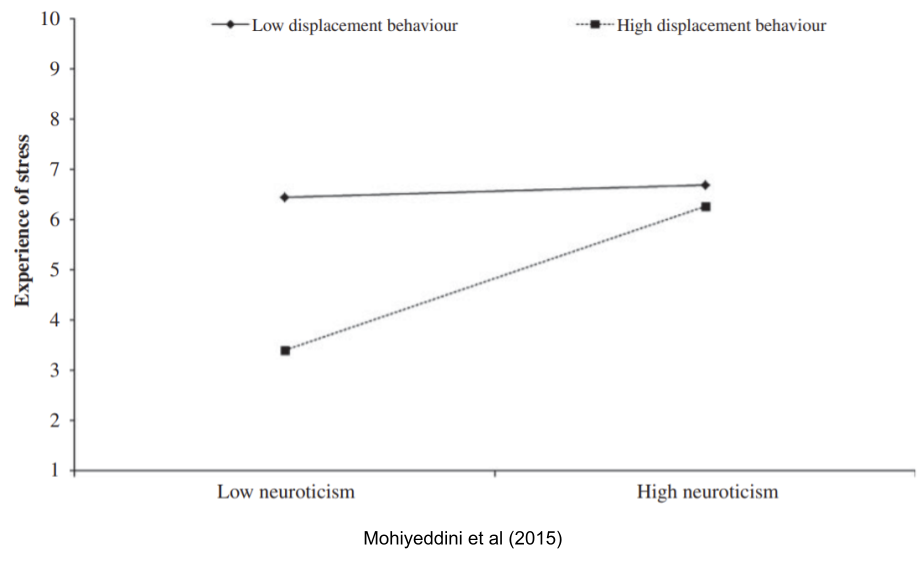
We have previously discussed displacement behaviors: for example, if a starving rat is given some food, but not enough to mitigate the drive, it will engage in ritualistic behaviors, such as pacing, gnawing wood, or self-directed behaviors. These behaviors reduce the stress response, but only for men with low neuroticism (Mohiyeddini et al 2015). Displacement behaviors don’t seem to help women in the same way (Mohiyeddini et al 2013).
Displacement aggression (“punching down”) is a significant outlet for frustration. Here’s Sapolsky (2004):
A variant of Weiss’s experiment uncovers a special feature of the outlet-for-frustration reaction. This time, when the rat gets the identical series of electric shocks and is upset, it can run across the cage, sit next to another rat and.. bite the hell out of it. Stress-induced displacement of aggression: the practice works wonders at minimizing the stressfulness of a stressor. It’s a real primate specialty as well. A male baboon loses a fight. Frustrated, he spins around and attacks a subordinate male who was minding his own business. An extremely high percentage of primate aggression represents frustration displaced onto innocent bystanders. Humans are pretty good at it, too. Taking it out on someone else–how well it works at minimizing the impact of a stressor.
I wish that I understood the reason why outlets have such effects.
Until next time.
References
Abramson et al (1978). Learned helplessness in humans: critique and reformulation
Aschbacher et al (2013). Good stress, bad stress and oxidative stress: insights from anticipatory cortisol reactivity
Bandura (1977) Self-efficacy: toward a unifying theory of behavioral change
Bandura & Cervone (1983). Self-evaluative and self-efficacy mechanisms governing the motivational effects of goal systems.
Berger et al (2019). Mediation of the Acute Stress Response by the Skeleton
Berkman & Syme (1979). Social integration, social networks, social support and health
Berridge et al (2010). Hypocretin/Orexin in Arousal and Stress
Dallman et al (2003). Chronic stress and obesity: a new view of comfort food
Deussing & Chen (2018). The Corticotropin-Releasing Factor Family: Physiology of the Stress Response
Dooley & Cohen (1988). The clinical significance of Campylobacter pylori
Epel et al (2001). Stress may add bite to appetite in women: a laboratory study of stress-induced cortisol and eating behavior
Epel et al (2000). Stress and body shape: stress-induced cortisol secretion is consistently greater among women with central fat
Friedman et al (1996) Effects of Type A behavioral counseling on frequency of episodes of silent myocardial ischemia in coronary patients
Guillemin et al (1977). Beta-endorphin and adrenocorticotropin are secreted concomitantly by pituitary gland.
Heinrichs et al (2003). Social support and oxytocin interact to suppress cortisol and subjective responses to psychosocial stress
Hopkin (1997). Show me where it hurts: tracing the pathways of pain
Humphreys et al (2012). Telomere shortening in formerly abused and never abused women.
Lefcourt (1992) Durability and impact of the locus of control construct
Levenstein (1998). Stress and peptic ulcer
Marmot et al (1978). Employment grade and coronary heart disease in British civil servants
Mohiyeddini et al (2013). Displacement behavior is associated with reduced stress levels among men but not women.
Mohiyeddini et al (2015). Neuroticism and stress: the role of displacement behavior
Overmeier & Leaf (1965). Effects of discriminative Pavlovian fear conditioning upon previously or subsequently acquired avoidance responding.
Parent et al (2017). Dynamic stress-related epigenetic regulation of the glucocorticoid receptor gene promoter during early development: The role of child maltreatment.
Peters et al (2017). Uncertainty and stress: why it causes diseases and how it is mastered by the brain
Pfaff (2006). Brain arousal and information theory: neural and genetic mechanisms
Picard & McEwen (2018). Psychological Stress and Mitochondria: A Systematic Review
Price (2000). Psychological and Neural Mechanisms of the Affective Dimension of Pain
Rebuffe-Scrive (1998). Steroid hormones and distribution of adipose tissue
Rebuffe-Scrive et al (1990). Steroid hormone receptors in human adipose tissues.
Rosengren et al (1993). Stressful life events, social support, and mortality in men born in 1933.
Rotter (1966). Generalized expectancies for internal versus external control of reinforcement.
Sacrey et al (2021). Slow-paced breathing: influence of inhalation/exhalation ratio and of respiratory pauses on cardiac vagal activity.
Sapolsky (2004). Why zebras don’t get ulcers, third edition
Seligman (1975). Helplessness: on depression, development, and death.
Stewart & Winser (1942). Incidence of perforated peptic ulcer: effect of heavy air-raids.
Ulrich-Lai & Herman (2009). Neural regulation of endocrine and autonomic stress responses
Ursin et al (1978). Psychobiology of stress: a study of coping men
Welin et al (1987). Family history and other risk factors for stroke: the study of men born 1913
Weiss (1972). Psychological factors in stress and disease
White (1959). Motivation reconsidered: the concept of competence
Williams & Litman (1996). Psychosocial factors: role in cardiac risk and treatment strategies
Zobel et al (2004). High neuroticism and depressive temperament are associated with dysfunctional regulation of the hypothalamic–pituitary–adrenocortical system in healthy volunteers
Part Of: Biology sequence Content Summary: 1800 words, 9 min read.
The Disposable Soma
Many people interpret aging as an inevitability: heat death is coming for us all. And it is true that most organisms experience senescence, i.e., age-related deterioration (Nussey et al 2012), even some bacteria (Ackermann et al 2003).
But some organisms experience negligible senescence (e.g., hydra Martinez 1998 or rockfish Finch 2009). Why isn’t negligible senescence the norm? As Williams (1957) put it,
It is remarkable that after a seemingly miraculous feat of morphogenesis, a complex metazoan should be unable to perform the much simpler task of merely maintaining what is already formed.
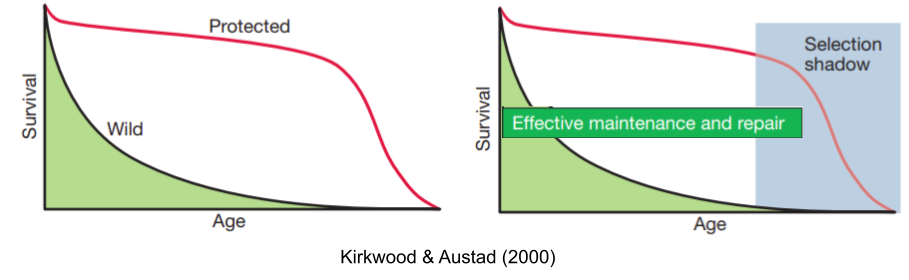
A clue: organisms rarely die from old age. Rather, environmental mortality (accidents, predation, starvation, disease, cold, etc) usually strike well before senescence does (Finch 1990). Why invest in maintaining a body that will be dead anyway for other reasons?
For example, 90% of wild field mice die in their first year (Phelan and Austad 1989), typically from cold. The three-year lifespan potential of the mouse is sufficient for its actual needs in the wild, and yet it is not excessive.
Consider the trade-offs associated with energy allocation. Because energy is scarce, the mouse will benefit by investing any spare energy into thermogenesis or reproduction, rather than better somatic maintenance, even though this means that damage will eventually accumulate to cause aging.
In metazoans, we saw cellular differentiation between somatic cells (which could specialize to ultimately become muscle, bone, etc) and germ cells (which promote reproduction). The germ line requires biological immortality: individual germ cells can die, but the lineage cannot be allowed to deteriorate. Germ cells accomplish this in part by better maintenance: for example, the protective enzyme telomerase only exists in germ cells and in certain adult stem cells. Once embryonic stem cells differentiate into somatic cells, there is a generalized downregulation of cell maintenance systems (Saretzki et al 2004).
This is the disposable soma theory of aging (Kirkwood 1977).
Aging vs Mortality
The idea that intrinsic longevity is tuned to the prevailing level of extrinsic mortality is supported by extensive observations on natural populations (Ricklefs 1998).
It’s not just observational evidence.
Stearns et al (2000) imposed a high mortality regime on one group of fruit flies, and observed that their experimental group lived a shorter life and a reduced age of sexual maturity.
In a natural experiment, opossums naturally evolving on a predator-free island lived longer than their phylogenetic siblings on a normal-predation population (Austad 1993).
Differences in mortality explains a large fraction of lifespan variance between species. For example, flying species enjoy weaker senescence than non-flying species, due to the shelter against mortality (Healy et al 2014). The lifespan-extending effect of mortality reduction is also seen…
… in arboreal species (Shattuck & Williams 2010),
… in fossorial species (Healy et al 2014),
… in species that hibernate (Turbill et al 2011)
… in species that evolve protective shells (Phillip & Abele 2010)
In most species, males senesce faster than females (Brooks & Garrett 2017). This is considered to be a direct investment of the male involvement in intrasexual (and intersexual) competition (Bonduriansky et al 2008), and the resultant increase in male mortality.
We might distinguish between two kinds of environmental mortality:
Non-selective mortality (e.g., the onset of winter) which strikes at random
Selective mortality (e.g., predation) which preferentially strikes certain demographics
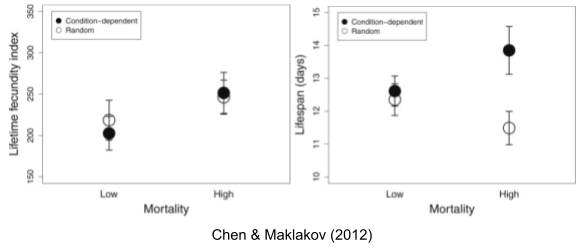
The above experimental results above relate to non-selective mortality. But Abrams (1993) has shown that evolutionary predictions can be considerably altered when density dependence is taken into account; selective mortality affects per capita resource availability. Chen & Maklakov (2012) found that lifespan decreases with random mortality, but increases with condition-dependent mortality (application of heat shock: only especially robust worms survive).
Aging vs Growth
Growth also drives senescence, because growth affects fecundity. Unceasing, indeterminate growth allows increasing fecundity with age. Indeed, senescence is negligible in organisms displaying indeterminate growth (Vaupel et al. 2004). But senescence is the rule in determinate growth organisms such as birds and mammals (Nussey et al. 2013).
Experimentally induction of catch-up growth reduces lifespan (Lee et al 2013).
In fact, growth rate is composed of two biologically distinct mechanisms. Development time is differentiation of the soma; under sexual selection during scramble competition (Andersson 1994). Growth is an increase in mass. When these are decoupled, only development time was found to be coupled to longevity (Lind et al 2017).
Many studies suggest that the hypothalamus-pituitary-somatotropic (HPS) axis mediates the tradeoff between growth and senescence (Dantzer & Swanson 2012). Fast species tend to have higher plasma insulin-like growth factor (IGF-1) than slow species (Swanson and Dantzer 2014; but see Stuart and Page 2010).
Two Genetic Theories of Aging
90% of wild rats die from cold in their first year, but in a protected laboratory environment those same rats live for three years, before dying of age-related diseases. From an evolutionary biologist’s perspective, senescence can evolve because selection gradients on mortality and fertility decline with age. Modeling by Hamilton (1966), and extended in Charlesworth (1994), found that selection is simply much weaker in old age; it casts a selection shadow.
Medawar (1952) noted the similarities between aging and Huntington’s disease. If the disease is inherited and always fatal why hasn’t natural selection expunged the responsible alleles from our gene pool? The answer, of course, has to do with the fact that Huntington’s disease typically strikes late in life history. He wrote “the force of natural selection weakens with increasing age… if a genetic disorder happens late enough in life, its fitness consequences may be completely unimportant”.
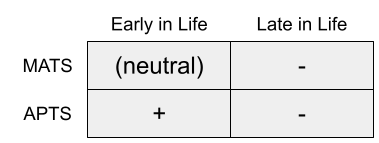
This is the mutation accumulation theory of senescence (MATS). It appeals tothe ubiquity of pleiotropy: one gene can produce multiple, different effects across the life course.
Williams (1957) proposed the antagonistic pleiotropy theory of senescence (APTS). Rather than neutrality, some age-related genes are selected for their benefits to early life, despite those very same genes being deleterious later.
There are important differences between these two theories. Because mutations occur randomly, MATS predicts that aging will be fairly idiosyncratic to that lineage; whereas APTS suggests that the mechanisms underlying aging are comparatively more shared. If APTS is true, biogerontology research on model organisms should prove more informative to human therapeutics.
IGF-1 genes promote growth yet inhibit somatic maintenance. They are excellent candidates for antagonistic pleiotropy, and showcase how the disposable soma theory can bridge genetic and microbiological perspectives.
Some weak evidence has been found for MATS. In contrast, the evidence for APTS is fairly strong (Austad & Hoffman 2018), including identification of dozens of candidate genes. When these genes are knocked out, such as an IGF receptor gene in C elegans, the resultant stains live longer, but ultimately disappear due to a small reduction in early life fertility (Jenkins et al 2004). William’s APTS model generated nine predictions about senescence; today, six of these have found strong support (Gaillard & Lemaitre 2017).
The Search For Mechanism
A quote from Kirkwood (2005)
One oddity about aging is its inherent complexity. Almost every aspect of an organism’s phenotype undergoes modification with aging, and this phenomenological complexity has led, over the years, to a bewildering proliferation of ideas about specific cellular and molecular causes.
In the disposable soma theory, senescence is caused by failures to maintain the soma. But which specific mechanisms are involved? Microbiologists have not yet achieved consensus of causal mechanism. But they have achieved a consensus list of candidates: Lopez-Otin et al (2013) motivates nine hallmarks of aging.
Perhaps someday we will have therapeutics that effectively promote somatic maintenance.
Until next time.
References
Abrams (1993). Does increased mortality favor the evolution of more rapid senescence?
Ackermann et al (2003). Senescence in a bacterium with asymmetric division
Andersson (1994). Sexual selection.
Austad (1993). Retarded senescence in an insular population of Virginia opossums
Austad & Hoffman (2018). Is antagonistic pleiotropy ubiquitous in aging biology?
Bonduriansky et al (2008). Sexual selection, sexual conflict and the evolution of ageing and life span
Brooks & Garrett (2017). Life history evolution, reproduction, and the origins of sex-dependent aging and longevity
Charlesworth (1994). Evolution in Age-Structured Populations
Chen & Maklakov (2012). Longer Life Span Evolves under High Rates of Condition-Dependent Mortality
Cole (1954). The population consequences of life history phenomena
Danson & Swanson (2012). Mediation of vertebrate life histories via insulin-like growth factor-1.
Finch (1990). Longevity, senescence and the genome
Finch (2009). Update on slow aging and negligible senescence – a mini-review
Gaillard & Lemaitre (2017). The Williams’ legacy: A critical reappraisal of his nine predictions about the evolution of senescence
Hamilton (1966) The moulding of senescence by natural selection
Healy et al (2014). Ecology and mode-of-life explain lifespan variation in birds and mammals
Jenkins et al (2004). Fitness cost of extended lifespan in Caenorhabditis elegans
Jones et al (2008). Senescence rates are determined by ranking on the fast-slow life-history continuum.
Kirkwood (1977). Evolution of ageing
Kirkwood (2005). Understanding the odd science of aging
Lee et al (2013). Experimental demonstration of the growth rate–lifespan trade-off
Lind et al (2017). Slow development as an evolutionary cost of long life
Lopez-Otin et al (2013). Hallmarks of aging
Martinez (1998). Mortality patterns suggest lack of senescence in hydra.
Medawar (1952). An unsolved problem of biology.
Nussey et al (2013). Senescence in natural populations of animals: widespread evidence and its implications for bio-gerontology
Omholt & Amdam (2004). Epigenetic regulation of aging in honeybee workers
Phelan and Austad (1989). Natural selection, dietary restriction and extended longevity
Phillip & Abele (2010). Masters of Longevity: Lessons from Long-Lived Bivalves – A Mini-Review
Ricklefs (2010). Embryo development and ageing in birds and mammals
Saretzski et al (2004). Stress Defense in Murine Embryonic Stem Cells Is Superior to That of Various Differentiated Murine Cells
Shattuck & Williams (2010). Arboreality has allowed for the evolution of increased longevity in mammals.
Stearns et al (2000) Experimental evolution of aging, growth, and reproduction in fruitflies.
Stenvinkel & Shiels (2019). Long-lived animals with negligible senescence: clues for ageing research
Stuart & Page 2010). Plasma IGF-1 is negatively correlated with body mass in a comparison of 36 mammalian species
Swanson & Dantzer (2014). Insulin-like growth factor-1 is associated with life-history variation across Mammalia
Turbill et al (2011). Hibernation is associated with increased survival and the evolution of slow life histories among mammals.
Vaupel et al (2004) The case for negative senescence
Wensink et al (2017). The rarity of survival to old age does not drive the evolution of senescence
Williams (1957). Pleiotropy, natural selection and evolution of senescence
Excerpt From: Sapolsky (2004). Why Zebras Don’t Get Ulcers
Of all the hormones that inhibit the reproductive system during stress, prolactin is probably the most interesting. It is extremely powerful and versatile; if you don’t want to ovulate, this is the hormone to have lots of in your bloodstream. It not only plays a major role in the suppression of reproduction during stress and exercise, but it also is the main reason that breastfeeding is such an effective form of contraception. Oh, you are shaking your head smugly at the ignorance of this author with that Y chromosome; that’s an old wives’ tale; nursing isn’t an effective contraceptive. On the contrary, nursing works fabulously . It probably prevents more pregnancies than any other type of contraception (Djerassi 1979). All you have to do is do it right.
Breast feeding causes prolactin secretion. There is a reflex loop that goes straight from the nipples to the hypothalamus. If there is nipple stimulation for any reason (in males as well as females), the hypothalamus signals the pituitary to secrete prolactin. And as we now know, prolactin in sufficient quantities causes reproduction to cease.
The problem with nursing as a contraceptive is how it is done in Western societies. During the six months or so that she breast-feeds, the average mother in the West allows perhaps half a dozen periods of nursing a day, each for 30 to 60 minutes. Each time she nurses, prolactin levels go up in the bloodstream within seconds, and at the end of the feeding, prolactin settles back to pre-nursing levels fairly quickly. This most likely produces a scalloping sort of pattern in prolactin release.
This is not how most women on earth nurse (Konner & Worthman 1980). When a hunter-gatherer woman gives birth, she begins to breast-feed her child for a minute or two approximately every fifteen minutes. Around the clock. For the next three years. (Suddenly this doesn’t seem like such a hot idea after all, does it?) The young child is carried in a sling on the mother’s hip so he can nurse easily and frequently. At night, he sleeps near his mother and will nurse every so often without even waking her.
Consider the life history of a hunter-gatherer woman. She reaches puberty at about age thirteen or fourteen (a bit later than in our society). Soon she is pregnant. She nurses for three years, weans her child, has a few menstrual cycles, becomes pregnant again, and repeats the pattern until she reaches menopause. Think about it: over the course of her life span, she has perhaps two dozen periods. Contrast that with modern Western women, who typically experience hundreds of periods over their lifetime. Huge difference. The hunter-gatherer pattern, the one that has occurred throughout most of human history, is what you see in nonhuman primates.
Perhaps some of the gynecological diseases that plague modern westernized women have something to do with this activation of a major piece of physiological machinery hundreds of times when it may have evolved to be used only twenty times (MacDonald et al 1991). An example of this is probably endometriosis (having uterine lining thickening and sloughing off in places in the pelvis and abdominal wall where it doesn’t belong), which is more common among women with fewer pregnancies and who start at a later age. Remarkably, the same is now being reported in zoo animals who, because of the circumstances of their captivity, reproduce far less often than those in the wild (Vogel 2001).
References
Djerassi (1979). The politics of contraception
Konner & Worthman (1980). Nursing frequency, gonadal function, and birth spacing among !Kung hunter-gatherers
MacDonald et al (1991). Recurrent secretion of progesterone in large amounts: an endocrine/metabolic disorder unique to young women?
Vogel (2001). A fertile mind on wildlife conservation’s front lines
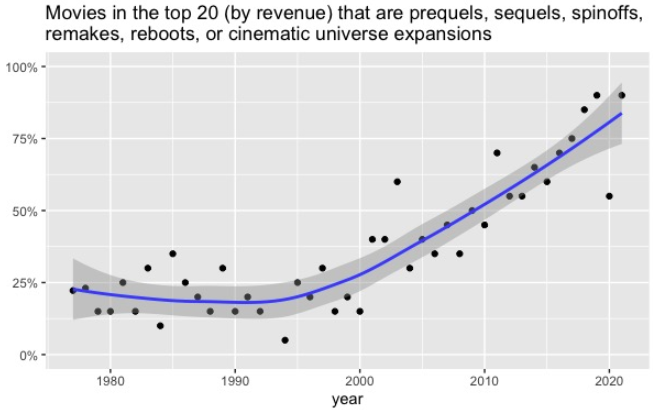
Chart-topping original movies have gone extinct. People have a lot of explanations for this, but they’re all incomplete because they don’t realize the same thing is happening everywhere. An oligopoly has conquered all of popular culture.
Godel’s Loophole: a design flaw in the US Constitution, which would permit the American democracy to be legally turned into a dictatorship.
Labor market explanation of the Flynn effect. Contrast with the education revolution hypothesis.
Artificial Intelligence
Gato, a scalable generalist agent that uses a single transformer with exactly the same weights to play Atari, follow text instructions, caption images, chat with people, control a real robot arm, and more.
What if the reason we dream is similar to the reason MLEs add noise to their models: to promote generalization?
Lesions in the left precuneus are associated with distorted time perception. “Minutes felt like hours… each time he would check his watch he’d be surprised how little time had passed.”
How does literature evolve? One birth at a time. Contrary to belief that literature changes due to external events like 9/11, 54% of the style of literature is solely driven by when its popular authors were born. After their 20s, authors don’t change much.
Biology
“If there is a God, why does he love crabs so much?” Carcinization in fish.
Salvage epistemology: on the dangers of contrarianism in the rationality community.
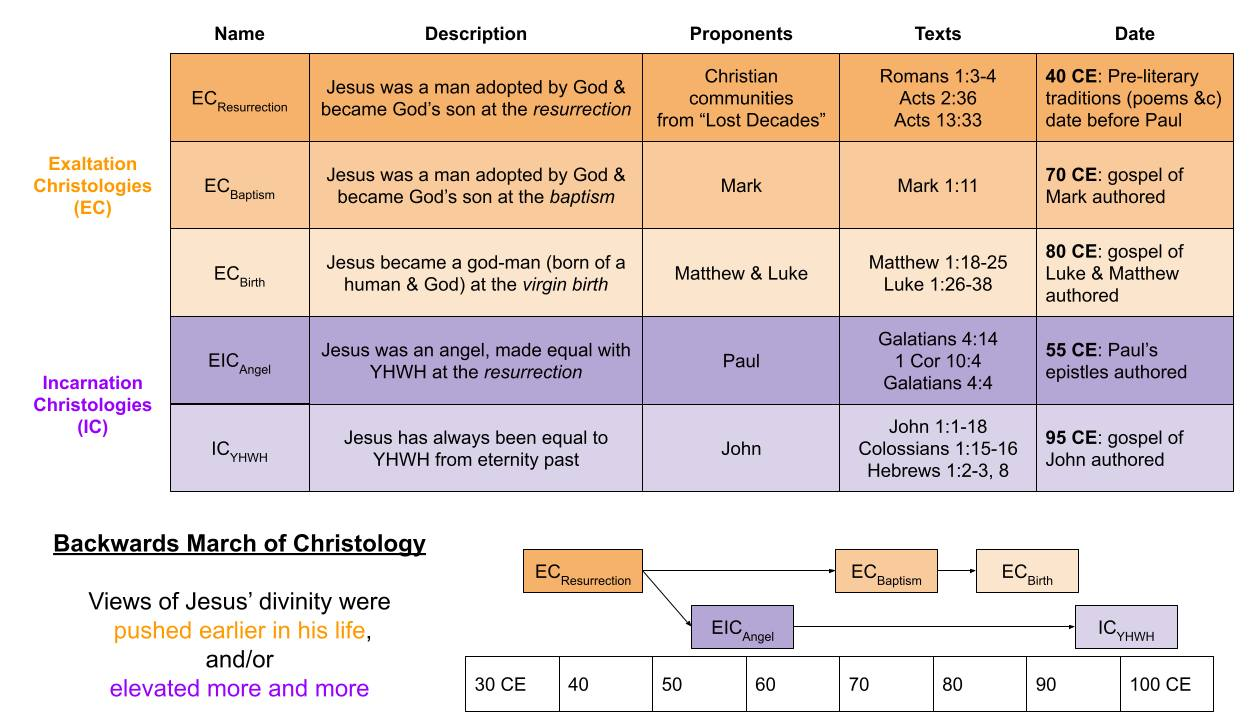
The Backwards March of Christology is a theory of how Christian interpretations of Jesus evolved over time. In the earliest writings, many Christians seemed to view him as a human prophet elevated to divinity at his resurrection: “God fulfilled his promise by resurrecting Jesus, as also it is written in the second psalm, ‘You are my Son; today I have fathered you.” These views became more elaborate as the decades passed.
Is social media driving political dysfunction? Haidt & Obama argue yes, Zeitzoff argues no.
Health
Last month, EBV found to be necessary in the development of MS. Now we learn: it’s not just a trigger, but may be a driver. New trial with transplanted immune cells that fight EBV has managed to stop progression of MS.
Ivermectin update: Strongyloides hypothesis is now peer-reviewed, and new large RCT shows null effects.
Status vs health. Oscar winners really do gain immortality (or at least a longer life). Oscar-winning actors and actresses live 5 years longer. Though later papers found a smaller boost to lifespan, the life-extending effects of winning also apply to Olympic medalists, Nobel winners & politicians.
Cognitive Science
Humans do some weird things without noticing. Every 3 minutes, humans touch their face. Why? First thought to be self-directed stress behavior, chemosignaling research suggests the function is rather to smell our hands. But it’s not just about self-sampling. After shaking someone’s hand, we are 100% more likely to unconsciously sniff that hand than normal, but only if we shake hands with someone of our gender. Otherwise we unconsciously sniff our other hand, likely as a form of self-reassurance! Video, paper.
Hot hand in tennis is real… but only for male players. Men who put the ball just inside during a point instead of just outside are more likely to win the next point. (data from 2m serves) Why women respond differently isn’t clear yet. Likely linked to testosterone and the so-called winner effect.
Growing up in rural areas produces better spatial navigation than being raised in cities, particularly for cities with grid-pattern streets (paper and explainer)
AI
Two extremely impressive models dropped: AI-generated art with Dall-E 2 (example), and natural language PaLM 540b (example). Neither open-sourced yet though..
Socratic Models. With multiple foundation models “talking to each other”, we can combine commonsense across domains, to do multimodal tasks like zero-shot video Q&A or image captioning, no finetuning needed.
Data poisoning is an adversarial attack that tries to manipulate the training dataset in order to control the prediction behavior of a trained model such that the model will label malicious examples into a desired classes (e.g., labeling spam emails as safe).
Weaponizing copyright law to thwart accountability: Cops blare Disney songs from their car to ensure citizen videos of them on the job get copyright flagged & taken down.
TIL most of the story in Catch Me If You Can is probably fake. Frank Abignale, who DiCaprio plays in the film, fabricated a thrilling backstory when he was mostly in prison.
You may recall the EEG study on effects of poverty. It was flawed. This argues that so-called policy relevant social science is mostly a fraud.
What is life? Schodinger (1944) argued that life is a negentropy phenomenon: free energy is concentrated locally, in the face of surrounding energy dissipation. This explains several facts of biology:
Inference. Jaynes (1957) famously argued that both statistical and biological inference derive from free energy minimization.
Abiogenesis. England (2013) argues that replication can be understood in thermodynamic terms, and view abiogenesis as driven by negentropy.
Metabolism. The field of bioenergetics (Cheetham 2010) has discovered metabolism to be consistent with this thermodynamical principle.
Homeostasis was described by Bernard (1878) as, “all vital mechanisms, however varied they may be, have only one object, that of preserving constant the conditions of life in the internal environment.” It has a thermodynamic interpretation: life is buffeting its internal milieu from the dissipative vagaries of the environment.
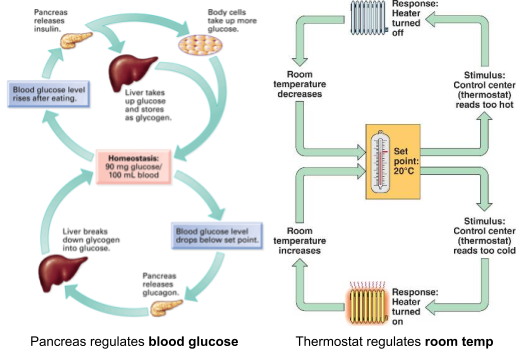
For example, blood sugar concentration is a biologically defended variable. Too much glucose causes energy poisoning, too little causes cellular starvation. The pancreas regulates blood sugar levels between 70 and 140 mg/dl. When blood sugar is too low, the pancreas releases glucagon to raise serum glucose; when too high, the pancreas releases insulin to reduce the level.
The pancreas here plays a similar role as a thermostat which is engineered to regulate room temperature. Thermostat design is heavily influenced by engineering control theory. The set point (i.e., the desired value) is specified, and the error term (difference between observation & set point) is computed. The error term can be used in two different ways:
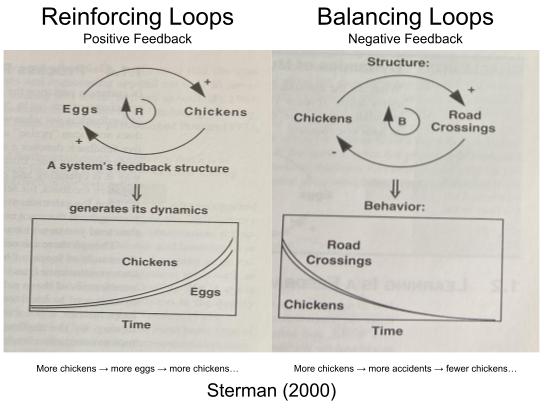
Positive feedback tends to produce exponential growth. Evolutionary arms races are a biological example, microphone squealing is an electronic example.
Negative feedback tends to stabilize a system. Physiological regulation may be a useful example…
Feedback loops are a central organizing principle of business dynamics (i.e., systems thinking). According to Sterman (2000): “all systems, no matter how complex, consist of overlapping networks of positive and negative feedbacks, and all dynamics arise from the interaction of these loops with one another.
The brain regulates body adiposity via the lipostat (Cabanac & Richard 1996), largely mediated by the leptin system (Zhang et al 1994).
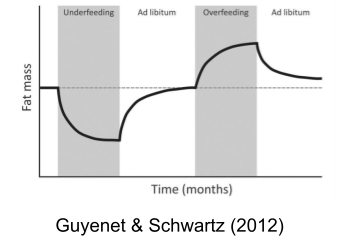
After overfeeding (Sims et al 1968), the body will attempt to lose weight (more metabolism & less food intake).
After underfeeding (Key et al 1950), the body engages a starvation response to gain weight (less metabolism & more food intake)
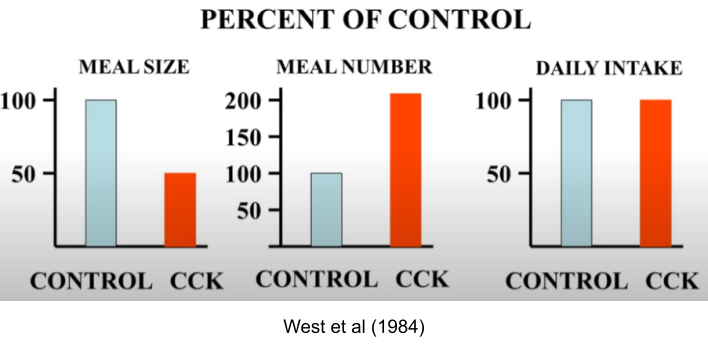
Taken together, these effectors work to maintain a constant level of stored calories (adiposity). Adiposity is biologically defended, which is why willpower-based dieting interventions so often fall short. If you inject a satiety hormone cholecystokinin (CCK) into a rat, meal size roughly halves.. but the number of meals initiated doubles to compensate.
The accuracy of your body’s regulatory systems is remarkable. For eating, annual energy intake is 955,570 calories; gaining one pound is 4,000 calories. In other words, your lipostat adjusts your energy intake to equal energy output with an error of 0.4%, or 11 calories per day. That’s a potato chip.
Adjustable Set Points
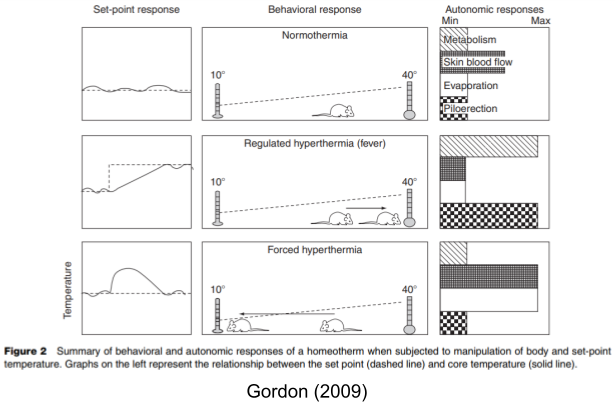
When Cannon (1929) first introduced homeostasis, he emphasized set point constancy. Yet set points can change; these are called rheostatic adjustments (Mrosovsky 1990). Consider body temperature. When a rat encounters an overly hot room (a forced change), it will compensate via three cooling effectors: skin blood flow, evaporation, and behavior to find a cooler environment.
Body temperature can also become elevated in response to infection, which helps the immune system combat pathogens. But this regulated change is handled differently by the body; with fever, warming effectors are engaged: metabolism increase (shivering), piloerection (goosebumps), and behavioral motivation to find a warmer environment. Only in fever is the set point adjusted.
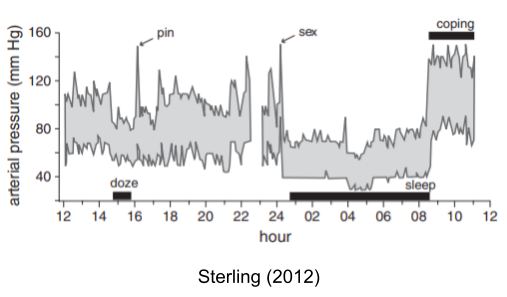
Other set points change too. The blood pressure set point is also dynamically altered from normal waking (~85 mmHg), sleep (~60 mmHg) and periods of extended stress (~120 mmHg).
Many other example of circadian rheostatic adjustments exist:
Why? What is the relationship between physiology and chronobiology?
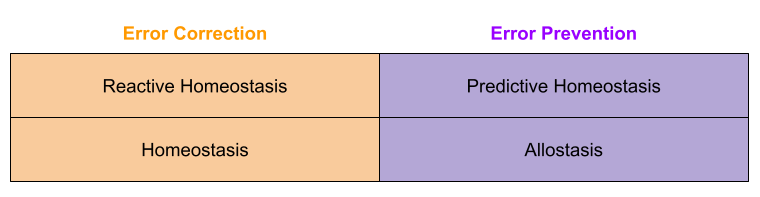
Reactive vs Predictive Homeostasis
Homeostasis is a central organizing principle of the viscera. But chronobiological rhythms is another such principle. Scientists once believed that such rhythms were direct responses to zeitgebers (environmental time cues). In 1729, a French astronomer placed a plant in a dark closet where it was no longer subject to daily variations in illumination. To his surprise, the plant continued to raise and lower its leaves on schedule. De Mairan (1729) concluded the plant had an internal clock for telling the time. This clock endogeneity result was shelved for a century, but was ultimately replicated.
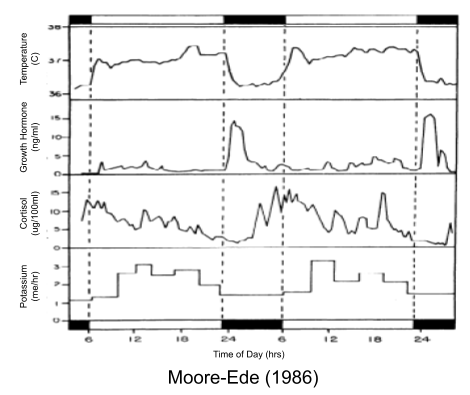
Why should the nervous system mold behavior into such predictable rhythms? As Moore-Ede (1986) puts it,
Amidst the random variations in environmental opportunities and challenges, two highly regular geophysical cycles – the year and the day – stand out. They dominate multiple aspects of our environment, most directly illumination and temperature. One of the most important features of these environmental cycles is extreme predictability. The time it takes for the rising sun to return to shine on the same spot on the spinning Earth (the solar day) varies by no more than a few minutes in any 1 year, and the average period of the Earth’s daily rotation has only slowed by 20 seconds during the course of the last million years. Since these cyclic changes are so predictable, it is scarcely surprising that circadian and circannual adaptive mechanisms have evolved to take advantage of this predictability.
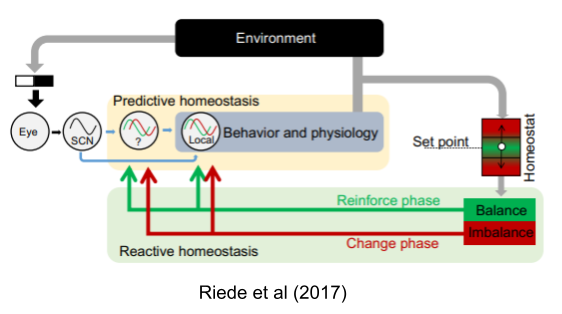
Circadian rhymes manifest in sleep-wake behavior, feeding-fasting cycles, drinking behavior, melatonin synthesis, and locomotor activity. In the controlled atmosphere of the lab, they rarely change; but in natural settings they do. Their phase flexibly responds to changing energetic conditions: a kind of temporal niche switching (Riede et al 2017).
Lesions of the suprachiasmatic nucleus (SCN) in the hypothalamus abolish these rhythms (e.g., Eastman et al 1984). Here, for example, is drinking record of a squirrel monkey – SCN lesions do not change the overall volume intake, but it does result in arrhythmia.
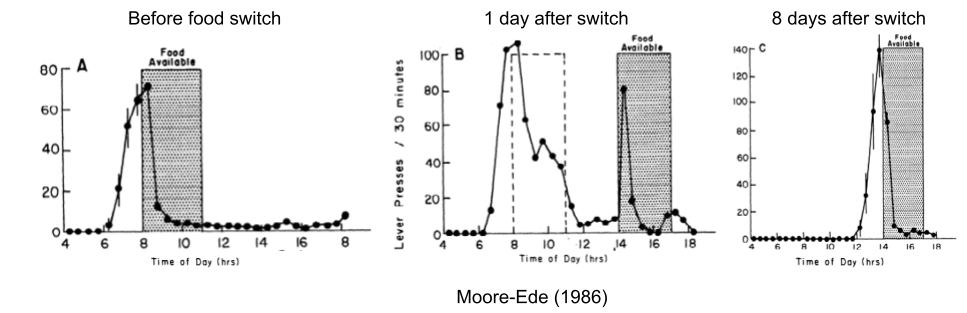
Consider a rat food dispenser that dispenses calories only during a 3h window. The rat will ramp up its food seeking behavior (lever presses) about an hour before the food is available. If the food availability window is shifted forward by six hours, the predictive behavior occurs on schedule, but the reactive behavior only occurred when the press of the lever first produced a pellet at 2pm. Over the course of the next eight days, the predictive component gradually slid towards the new window.
If a rat becomes motivated to eat only when it is hungry, that is too late. Foraging is a time consuming behavior. And the body itself needs time to prepare for a meal: blood glucose decreases before a meal, which serves to blunt the postprandial rise in glucose. These anticipatory cephalic phase responses (CPRs) enable animals to cope with the imbalance created when food is restored.
Decoupling of predictive and reactive components has been replicated in myriad other domains (Moore-Ede 1986, Schulkin & Sterling 2019). In general, phase adjustments occur when the original rhythms fail (Riede et al 2017). Errors in predictive homeostasis promote exploration of alternative temporal niches.
Finally, predictive homeostasis is not limited to circadian clocks. Arbitrary cues can elicit homeostatic responses.
Can the concept of homeostasis include predictive, error preventive components. Researchers disagree. Moore-Ede (1986) says yes, Schulkin & Sterling (2019) says no and reserves the term allostasis for the latter concept. Much of this dispute is taxonomic, and centers on interpreting Cannon (1929)’s original meaning. In the final analysis, however, both sides have converged on a dual process theory of regulation.
Balance Point Theory
The concept of set point may need to be discarded. To understand why, let’s return to thermoregulation.
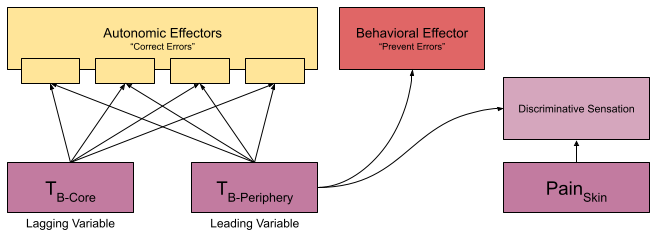
In humans, we think of a single set point of 98.6 F. But your CNS measures two quantities: peripheral temperature (e.g., in the skin) and core temperature (e.g., in the stomach). Peripheral temperature sensors are not used exclusively by thermoregulation, they also push fine-grained spatial data to the insula for more specific interactions with the environment (e.g., burn prevention).
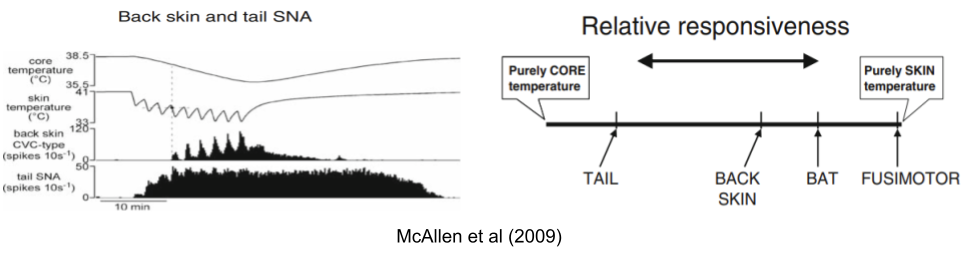
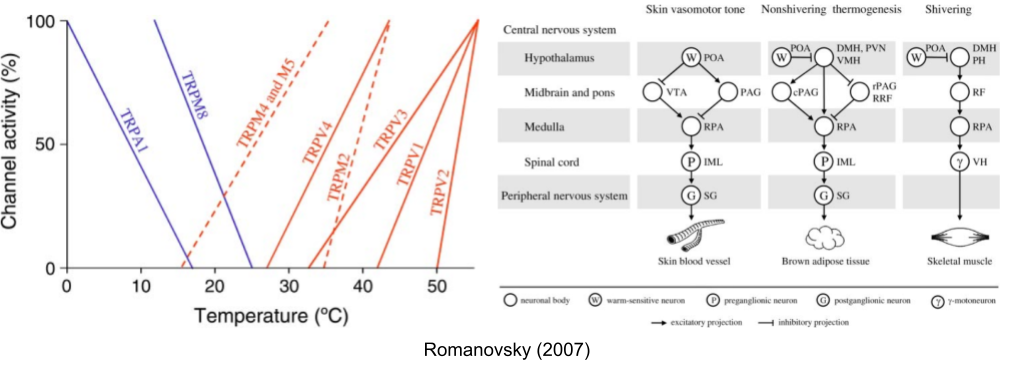
Due to thermal inertia, the core changes more slowly than the periphery (especially in large animals). This makes the periphery a leading variable. Because skin is more predictive than core, its sensors are more likely to evoke a preventative behavioral response (Romanovsky 2007).
Some autonomic effectors are more responsive to core temperature and vice versa. McAllen et al (2009) report experiments where they immersed a rat in water & rapidly altered the skin temperature. By measuring effector neurons during this experience, they showed that these effectors do not respond univocally – they differ in responsiveness to changes in core and skin.
These effectors not only respond to different inputs. Each input responds to different temperatures, and each output flows through an independent anatomical pathway:
The classical theory of homeostatic set point requires a central controller, which aggregates across temperature sensors to compute a mean temperature & coordinate its responses. But the anatomical basis for such a system remains elusive. And we have seen that thermoregulation effectors have independent inputs, functions, and outputs.
Satinoff (1978) proposes that the central controller does not exist, and neither does a single set point. She modeled multiple, independent sensor-effector loops, whose arithmetic sum of activity across activated effectors comprise the biologically defended range. As the subpopulation of active sensor-effector loops changes, so too does the aggregate balance point (Romanovsky 2007).
Decentralized control systems envisioned by balance point theory are self-organizing. They have important advantages, including flexibility and robustness to loss of system components (Seeley 2002). This comes at a price: decentralized systems cannot guarantee optimality, in part because of inefficient coordination of the distributed subsystems. Decentralized control may explain the following phenomena:
Opponent Processes. Simultaneous use of the furnace and air conditioner wastes fuel and contributes to wear and tear on both pieces of equipment. In the same way, it is hard to imagine a central controller producing such an inefficient result, but balance point theory explains the phenomenon quite nicely. One popular model of addiction assumes that reward and hedonia are physiologically regulated and that sensor-effector loops exist that influence the value of these variables (Koob & Le Moal 2008). Addiction is viewed as competition between a generic antireward mechanism versus a specific cue being ascribed increasing amounts of incentive salience.
Asymmetric Enforcement. For adiposity, mammals are very efficient at responding to underfeeding (and surgical removal of fat), but their response to overfeeding (or surgical implantation of fat) is much less robust. Leptin in particular seems to enforce the lower threshold alone (Wade 2004). For temperature, mammals exposed to severe stressors (e.g., endotoxins) will shut down thermogenesis and revert to poikilothermy – the upper threshold is still defended, but the lower defended threshold drops by tens of degrees (Romanovsky 2004).
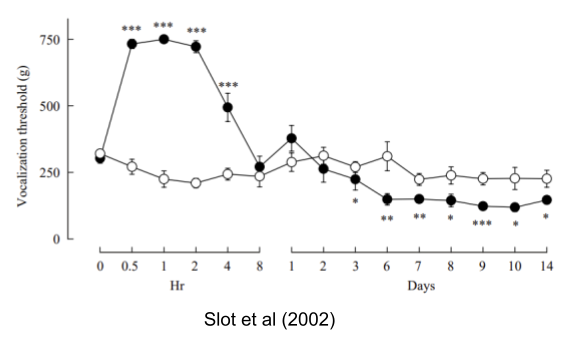
Overcompensation. Cold-challenged armadillos resulted in persistent and excessive increases in core temperature and oxygen consumption that exceeded the pre-perturbation values (discussed in Ramsay & Woods 2014). Similarly, Slot et al (2002) show that exposure to fentanyl at first produces pain tolerance, but over time leads to pain intolerance (hyperalgesia):
Overcompensation may be involved in many modern-day examples of cumulative movement of the balance point (aka rheostatic drift), including
why BMI began increasing in the 1970s (James et al 2001);
why sperm count is declining (Levine et al 2017);
why body temperature is falling (Protsiv et al 2020);
why autoimmune diseases are on the rise (Brady 2012); and
why the placebo effect is strengthening (Tuttle et al 2015).
Market-based control (Clearwater 1996) represents one way to formalize balance point theory. Consider blood pressure. The body must balances between demand (organs requiring nutrient-rich blood) and supply (the heart-lung system which distributes these resources). Blood pressure can be interpreted as a price equilibrating supply and demand: higher blood pressure benefits organs but places a strain on the heart, and vice versa (Fink 2005). This interpretation of blood pressure casts new light on the strong associations between the hypertension, obesity, and hyperglycemia (i.e., metabolic syndrome): they are equilibria of an energy surplus.
Interloop Effectors
In Two Cybernetic Loops, we saw how the nervous system can be dichotomized as a world-oriented cold loop and body-oriented hot loop. Our discussion of homeostasis has centered on internal bodily variables being regulated by internal effectors. But one of the key functions of the hot loop is to “cross state lines” and motivate foraging behavior (i.e., external effectors) in service of the body.
The relationship between hot loop & reward system is complicated to tease apart. Activity in agouti-related protein (AgRP) neurons, aka hunger neurons, cause sensations of hunger, and also transmit a sustained positive valence signal that conditions both Pavlovian and instrumental learning (Chen et al 2016). When an animal sees food, AgRP neurons are immediately silenced, but the reward system nevertheless promotes consummatory behavior.
In obesity, we know that ultra-processed foods (UPF) play a role (Hall et al 2019). But we still don’t know which system is to blame! Is the epidemic caused by toxins (e.g Alharbi et al 2018) interfering with our internal effectors? Or by superstimulus (hyperpalatable foods) overwhelming our reward system (Guyenet 2017)? The jury is out.
Panksepp (1998) describes the basal ganglia as the SEEKING system, a generic mechanism that promotes both appetitive and consummatory motor behaviors. Activation of this system generates emotional experiences of curiosity, engagement, wanting, and motivation. Homeostatic detectors in the medial hypothalamus activate SEEKING via the lateral hypothalamus:
The reward value of a stimulus increases with the effectiveness of that stimulus in restoring bodily equilibrium (homeostasis). This effect, known as alliesthesia, is well-documented for food rewards, which are more pleasurable when they relieve a hunger state (Burnett et al 2019). Further, on different visceral states (e.g., hungry vs thirsty), the reward topography will change, despite the absence of any phasic DA learning signals.
Wanting is the substrate of arousal, or motivation. Its purpose is to control metabolic expenditure. We can see evidence for this in adjunctive behaviors. If a starving rat is given some food, but not enough to mitigate the drive, it will engage in ritualistic behaviors, such as pacing, gnawing wood, or running excessively. This phenomenon of behavior substitution was also discovered by ethologists under the heading of displacement behaviors. For example, two skylarks in combat might suddenly cease fighting and peck at the ground with feeding movements. These behaviors rely on the mesolimbic dopamine system (Robbins & Koob 1980).
Formal models (such as reinforcement learning and active inference) aspire to model the behavioral profile of the SEEKING system. Yet many models do not include these visceral influences. I look forward to the day a simulated agent can reproduce these phenomena.
Until next time.
References
Alharbi et al (2018). Health and environmental effects of persistent organic pollutants
Bernard (1878). Les phenomenes de la vie
Brady (2012). Autoimmune Disease: A Modern Epidemic?
Burnett et al (2019). Need-based prioritization of behavior
Cabanac & Richard (1996). The nature of the ponderostat: Hervey’s hypothesis revived
Cannon (1929). Organization for physiological homeostasis.
Cheetham (2010) Introducing biological energetics
Chen et al (2016). Hunger neurons drive feeding through a sustained, positive reinforcement signal.
Clearwater (1996). Market-based control: a paradigm for distributed resource allocation.
De Mairan (1729). Observation botanique.
England (2013). Statistical physics of self-replication
Falk (1970). The nature and determinants of adjunctive behavior
Fink (2005). Hypothesis: the systemic circulation as a regulated free-market economy. A new approach for understanding the long-term control of blood pressure
Gordon (2009). Autonomic Nervous System: Central Thermoregulatory Control
Guyenet (2017). The Hungry Brain: Outsmarting the Instincts That Make Us Overeat
Guyenet & Schwartz (2012). Regulation of Food Intake, Energy Balance, and Body Fat Mass: Implications for the Pathogenesis and Treatment of Obesity
Eastman et al (1984). Suprachiasmatic nuclei lesions eliminate circadian temperature and sleep rhythms in the rat
Hall et al (2019). Ultra-Processed Diets Cause Excess Calorie Intake and Weight Gain: An Inpatient Randomized Controlled Trial of Ad Libitum Food Intake
James et al (2001). The worldwide obesity epidemic
Jaynes (1957). Information theory and statistical mechanics
Key et al (1950). The biology of human starvation.
Koob & Le Moal (2008). Addiction and the brain antireward system.
Levine et al (2017). Temporal trends in sperm count: a systematic review and meta-regression analysis
McAllen et al (2010). Multiple thermoregulatory effectors with independent central controls.
Modell et al (2015). A physiologist’s view of homeostasis
Moore-Ede (1986). Physiology of the circadian timing system: predictive versus reactive homeostasis
Mrosovsky (1990). Rheostasis: the physiology of change
Panksepp (1998). Affective Neuroscience
Protsiv et al (2020). Decreasing human body temperature in the United States since the Industrial Revolution
Romanovsky (2007). Thermoregulation: some concepts have changed. Functional architecture of the thermoregulatory system.
Romanovsky (2004). Do fever and anapyrexia exist? Analysis of set point-based definitions
Ramsay & Woods (2014). Clarifying the roles of homeostasis and allostasis in physiological regulation
Robbins & Koob (1980). Selective disruption of displacement behaviour by lesions of the mesolimbic dopamine system
Satinoff (1978). Neural organization and the evolution of thermal regulation in mammals.
Schulkin & Sterling (2019). Allostasis: a brain-centered, predictive mode of physiological regulation
Schrodinger (1944). What is life?
Seeley (2002) When is self-organization used in biological systems?
Sims et al (1968). Experimental Obesity in Man.
Sterman (2000). Business Dynamics
Sterling (2012) Allostasis: a model of predictive regulation
Slot et al (2002). Sign-reversal during Persistent Activation in l-Opioid Signal Transduction
Tuttle et al (2015). Increasing placebo responses over time in U.S. clinical trials of neuropathic pain
Wade (2004) Regulation of body fat content?
West et al 91994). Cholecystokinin persistently suppresses meal size but not food intake in free-feeding rats
Wing & Phelan (2005). Long-term weight loss maintenance
Zhang et al (1994). Positional Cloning of the Mouse Obese Gene and its Human Homologue
Part Of: Politics sequence Content Summary: 1000 words, 5 min read
Dominance and Fitness
In many species, dominance hierarchies are fairly easy to measure. Submissive chimpanzees, for example, emit pant-hoots to dominants, which clarify their relationship. Systematically counting these events in a community, and the latent social structure will reliably reveal itself.
The Elo rating system, used in chess, is an efficient method to estimate rank. Just as chess harnesses observable outcomes (game results) to estimate a hidden variable (player ability), researchers use Elo to estimate latent status from observable pant-hoots:
Intrinsic dominance is underwritten with physical strength, or resource holding potential (RHP). A dramatic illustration of this is lekking behavior, with males gathering in one area and physically competing for prime real estate (near the center). These examples of contest competition amongst male can be deadly, especially among species with sexual selected weapons like antlers on red stags.
Here we illustrate a lek amongst sage-grouse. Females enter the lek and preferentially, although not exclusively, mate with high status males. High status males thus enjoy reproductive benefits, and the species exhibits strong reproductive skew. It is sometimes difficult to verify paternity via behavioral measures alone, but new genetic approaches confirm the hypothesis that dominance bestows fitness benefits (Di Fiore 2003).
In many species, physical formidability is the primary determinant of dominance. But other species feature political microcoalitions, where multiple subordinates forge alliances to challenge the status of a dominant. For example, de Waal (1982) describes this in a triangular relationship amongst chimpanzee males. After the alpha Yeroen is displaced by a strong Luit, he forms a coalition with the young Nikkie, who together displaced a physically stronger Luit. While his intrinsic dominance was lower, Nikkie’s derived dominance (Hand 1986) propelled him into an alpha position.
Dominance vs Leverage
Yet, there is more to power than dominance. You can see this in the relationship between Nikkie, Yeroen and Luit. Despite being beta, Yeroen engaged in more mating activity than Yeroen. Alphas normally interfere in subordinate mating, but Nikkie did not. Why?
While Nikkie possessed dominance, his position was dependent on Yeroen. Yeroen had leverage over Nikkie, at least until Nikkie’s power was consolidated during his second year.
We can define leverage as dependence-based power, with a unique resource exchanged for a common resource. This phenomenon is largely independent of dominance rank:
Estrus vs Food Tolerance. During estrus, female primates experience advantageous changes in their relationships without changing rank, because their eggs represent an inalienable commodity. Male food tolerance transiently increases – sexual associations could end if males refused to share food (Van Noordwijk and van Schaik 2009).
Foraging Skill vs Grooming. Stammbach (1988) reported an experiment in which a single subordinate male long-tailed macaque was trained to use a relatively complex procedure to obtain food. Once he had completed the task, other animals had access to food. As a result, the trained animal began to receive significantly more grooming. The trained animal received significantly more grooming than before the training, which suggests that he had leverage independent of his dominance rank.
Infant Access vs Grooming. Monkeys, particularly females, find young infants extremely attractive, and frequently approach and try to interact with the newborn infant. Some mothers will grant access to their newborns in exchange for such access (Silk, 2002).
The taxonomy of Smith et al (2002) delineates these different facets of power (a.k.a., status). This aligns with certain sociological theories of power in humans (Emerson 1962), as argued in Chapais (1991).
Primate status is promoted by competence. Dominance requires not just physical formidability, but skill in coalition formation, tactical deception, and combat tactics. Similarly, leverage isn’t restricted to resource ownership – foraging skill can be another route to power.
Dominance Produces Leverage
But dominance and leverage are not independent. Dominance is itself a unique resource, which can in turn produce leverage.
Alphas often engage in bridging alliances, where a dominant backs a subordinate to increase his derived dominance rank. More generally, Seyfarth (1977) proposed the grooming for support model, with three subcomponents.
Status Attraction: grooming directed up the dominance hierarchy. Supportive results in Tiddi et al (2012), Schino (2001). But in other species, grooming can be directed downwards (Parr et al 1997, Saunder 1988), or in no specific direction (Silk et al 1999).
Grooming Reciprocity: dominants were more likely to support subordinates. Supportive results in Seyfarth & Cheney (1984), Hemelrijk (2004)
Affiliative Competition: subordinates compete for grooming access to dominant. Supportive results in Schino (2007).
Dominants have leverage! Here they exchange a unique resource (coalitional support) for common resources (grooming).
The status attraction phenomenon shows that subordination is more than unalloyed fear and avoidance. Primate dominance thus exhibits a kind of proto-prestige (admiration for the powerful), which is quite elaborate in Homo Sapiens.
Other resources besides dominant-provided political support can generate leverage. Grooming for food tolerance exchanges are documented in Henzi et al (2003). Subordinate support for sexual tolerance exchanges are documented in Duffy et al (2007). Besides these dyadic exchanges, alpha chimpanzees also produce public goods. They engage in dispute resolution (a proto-judiciary!), impartially prying apart disputants to keep the peace, and underdog advocacy to protect the weak. These public goods may also provide leverage.
Until next time.
References
Chapais (1991). Primates and the origins of aggression, power, and politics among humans.
Chapais (2015). Competence and the evolutionary origins of status and power in humans
Di Fiore (2003). Molecular genetic approaches to the study of primate behavior, social organization, and reproduction
Duffy et al (2007). Male chimpanzees exchange political support for mating opportunities
Emerson (1962). Power-Dependence Relations
Hand (1986). Resolution of social conflicts: dominance, egalitarianism, spheres of dominance, and game theory.
Henrich & Gil-White (2000). The evolution of prestige: freely conferred deference as a mechanism for enhancing the benefits of cultural transmission
Henzi et al (2003). Effect of resource competition on the long-term allocation of grooming by female baboons: evaluating Seyfarth’s model
Hemelrijk (2004) Support for being groomed in long-tailed macaques
Lewis (2002). Beyond dominance: the importance of leverage
Newton-Fisher (2017). Modeling Social Dominance: Elo-Ratings, Prior History, and the Intensity of Aggression
Parr et al (1997). Grooming down the hierarchy: allogrooming in captive brown capuchin monkeys
Saunder (1988). Ecological, social, and evolutionary aspects of baboon (Papio cynocephalus) grooming behavior
Schino (2001). Grooming, competition and social rank among female primates: a meta-analysis
Schino (2007). Grooming and agonistic support: a meta-analysis of primate reciprocal altruism.
Seyfarth (1977). A model of social grooming among adult female monkeys
Seyfarth & Cheney (1984). Grooming, alliances, and reciprocal altruism in vervet monkeys
Silk et al (1999). The structure of social relationships among female savannah baboons in Moremi Reserve, Botswana.
Silk (2002). Using the ‘f’-word in primatology.
Stammbach (1988). Group responses to specially skilled individuals in a Macaca fascicularis group
Tiddi et al (2012). Grooming up the hierarchy: the exchange of grooming and rank-related benefits in a New World primate.
Von Noordwijk & van Schaik (2009). Intersexual food transfer among orangutans: do females test males for coercive tendency? Maria A. van Noordwijk & Carel P. van Schaik