Part Of: Algebra sequence
Content Summary: 600 words, 6 min read
Function As Operator
A function can be conceived as a machine that converts input into output. For example:
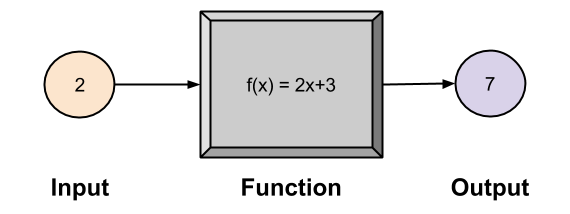
Something cool noticed by geometers of long ago:
If I feed the above function ALL POSSIBLE NUMBERS, I get a line!
Function As Map
We can also view functions as maps, taking an input value & returning its corresponding output item.
Let domain represent the set of all numbers that an input could be. Let codomain represent the set of all numbers that an output could be. For example:

Counting Edges
How might we classify different functions? One obvious thing to do is to count the number of edges entering or leaving a node:
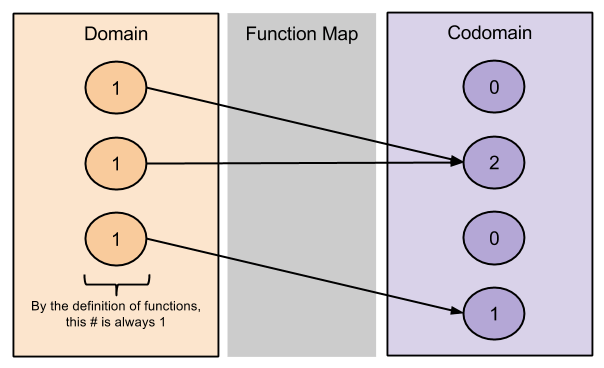
The definition of function is such that every input element maps to one and only one output element. (This is why vertical lines are difficult to achieve in geometry). So the domain counts are relatively predictable.
The codomain numbers, on the other hand, are fairly interesting. We can distinguish popular outputs as those with more than one entry, and unpopular outputs as those with no entries.
Injection & Surjection (& Bijection)
Suppose we want a way to refer to function maps that produce no popular outputs, whose codomain elements have at most one element. Call such functions injective functions.
Suppose we want a way to refer to function maps with no unpopular outputs, whose codomain elements have at least one element. Call such functions surjective functions.
If neither popular nor unpopular outputs exist — if all outputs are “normal” 🙂 — we may call such functions bijective functions.
The above example is neither injective nor surjective:
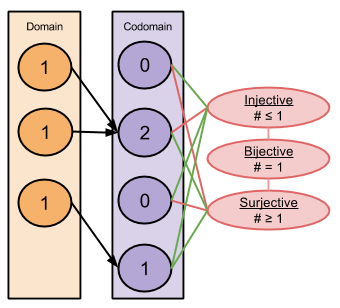
Examples of all four outcomes:

Cardinality vs. Bijection
Consider the bottom-left example. Note that its domain is smaller than its codomain (3 < 4). If I let you rearrange the arrows any which way, could you manufacture surjection? Take a minute to convince yourself that you cannot. Do you see why there will always be at least one unpopular output? Consider the top-right example. Note that its domain is larger than its codomain (4 > 3). If I allow you to rearrange the arrows any which way, could you manufacture injection?
Take a minute to convince yourself that you cannot. Do you see why there will always be at least one popular output?
The argument you must use to convince yourself of the above is an analogue to the pigeonhole principle.
More generally, we find that:

You can also use the above properties to “work backwards”: for example, if two sets provide at least one bijection, their relative sizes (cardinalities) must be equal.
Generalizing To Morphisms
When in doubt, zoom out! Time to fall in love with category theory. 🙂
Functions that are grounded in set theory. But other types of structure-preserving maps have been studied:

Injection/Surjection/Bijection were named in the context of functions. Wouldn’t it be nice to have names any morphism that satisfies such properties? Well, you’re in luck!
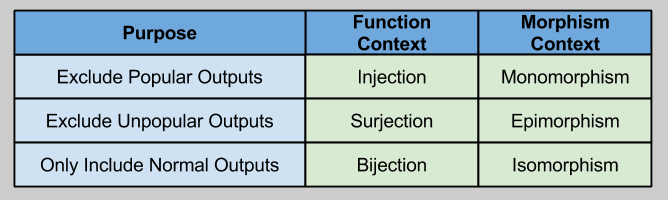
Recall that bijection (isomorphism) isn’t itself a unique property; rather, it is the union of the other two properties.
It turns out that another interesting property to read out of maps is endomorphism: a map of an algebraic structure to itself. That makes three interesting properties. Let us explore how the sets of homomorphisms (a homomorphism is an general instance of a morphism, kind of like the instantiation of an abstract class in computer science) relate to each other:

Decoding the above figure:
- Hom → set of homomorphisms
- End → set of endomorphisms
- Mon → set of monomorphisms (i.e., injective morphisms)
- Epi → set of epimorphisms (i.e., surjective morphisms)
- Iso → set of isomorphisms (i.e., bijective morphisms)
- Aut → set of automorphisms (i.e., bijective morphisms that also satisfy the endomorphic property)
- ∞ → contain only homomorphisms from some infinite structures to themselves.