
Part Of: Algebra sequence
Followup To: An Introduction to Linear Algebra
Next Up: Singular Value Decomposition
Content Summary: 1300 words, 13 min read
Geometries of Eigenvectors
Matrices are functions that act on vectors, by mapping from row-vectors to column-vectors. Consider two examples:
- Reflection matrices, which reflect vectors across some basis.
- Rotation matrices, which rotate vectors clockwise by
degrees.

The set of eigenvectors of a matrix 

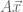
Eigenvectors have a straightforward geometric interpretation:
- Reflection eigenvectors are orthogonal or parallel to the reflecting surface. In the left image above, that is the top two pairs of vectors.
- Rotation eigenvectors do not exist (more formally, cannot be visualized in
).
Algebra of Eigenvectors
We can express our “parallel output” property as:

Thus 
Scaling factor 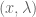
For an 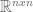

- The sum of eigenvalues equals the trace (sum of values along the diagonal).
- The product of eigenvalues equals the determinant.
To solve, subtract 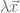

We would like to identify n unique eigenvectors. But if the new matrix 
How to accomplish this? By finding eigenvalues that satisfy the characteristic equation 
Let’s work through an example! What is the eigendecompositon for matrix
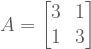
We need to find eigenvalues that solve the characteristic equation.



Are these eigenvalues correct? Let’s check our work:

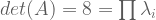
How to find our eigenvectors? By solving the nullspace given each eigenvalue.
For 
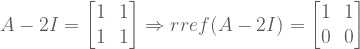

For 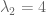


Desirable Matrix Properties
The above example was fairly straightforward. But eigendecomposition can “go awry”, as we shall see. Consider a rotation matrix, which in two dimensions has the following form:

What are the eigenvalues for rotation 

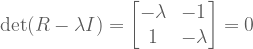
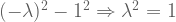
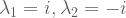
We can check our work:
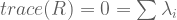
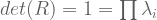
We saw earlier that rotation matrices have no geometric interpretation. Here, we have algebraically shown that its eigenvalues are complex.
![A = \left[ \begin{smallmatrix} 3 & 1 \\ 1 & 3 \\ \end{smallmatrix} \right]](https://s0.wp.com/latex.php?latex=A+%3D+%5Cleft%5B+%5Cbegin%7Bsmallmatrix%7D+3+%26+1+%5C%5C+1+%26+3+%5C%5C+%5Cend%7Bsmallmatrix%7D+%5Cright%5D&bg=ffffff&fg=555555&s=0&c=20201002)
![R = \left[ \begin{smallmatrix} 0 & -1 \\ 1 & 0 \\ \end{smallmatrix} \right]](https://s0.wp.com/latex.php?latex=R+%3D+%5Cleft%5B+%5Cbegin%7Bsmallmatrix%7D+0+%26+-1%C2%A0%5C%5C+1+%26+0%C2%A0%5C%5C+%5Cend%7Bsmallmatrix%7D+%5Cright%5D&bg=ffffff&fg=555555&s=0&c=20201002)
We can generalize the distinction between 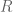
Spectral Theorem. Any matrix that is symmetric (A = AT) is guaranteed to have real, nonnegative eigenvalues. The corresponding n eigenvectors are guaranteed to be orthogonal.
In other words, eigendecomposition works best against symmetric matrices.

Diagonalization
Let us place each eigenvector in the column of a matrix 
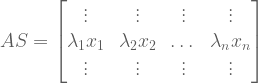
We see the product contains a mixture of eigenvalues and eigenvectors. We can separate these by “pulling out” the eigenvalues into a diagonal matrix. Call this matrix 

Most matrices have the property that its eigenvectors are linearly independent. For such matrices,
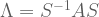

Matrices that can be factorized in this way are said to be diagonalizable. We can see that both elimination and eigendecomposition are performing the same type of work: factorizing matrices into their component parts.
If 


Asymptoptic Interpretations
This diagonalization approach illustrates an important use case of eigenvectors: power matrices. What happens when
We can use the diagonalization equation to represent 

We can simplify by canceling the inner terms 

This equation tells us that the eigenvectors is invariant to how many times
- If each eigenvalue has magnitude less than one, the output will trend towards zero.
- If each eigenvalue has magnitude greater than one, the output will trend to infinity.
Fibonacci Eigenvalues
The powers interpretation of eigenvalues sheds light on the behavior of all linear processes. This includes number sequences such as the Fibonacci numbers, where each number is the sum of the previous two numbers.
Recall the Fibonacci numbers are 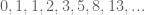

Eigenvalues can answer this question. We must first express the Fibonacci generator as a linear equation:

In order to translate this into a meaningful matrix, we must add a “redundant” equation

With these equations, we can create a 2×2 Fibonacci matrix 
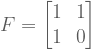
This matrix uniquely generates Fibonacci numbers.


To discover the rate at Fibonacci numbers grow, we decompose






We can go on to discover eigenvectors 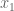
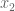


As k goes to infinity, the second term goes to zero. Thus, the ratio is dominated by the larger eigenvalue, 1.61803.
Mathematicians in the audience will recognize this number as the golden ratio.

We have long known that the ratio of successive Fibonnaci numbers converges to 1.61803. Eigenvalues provide a mechanism to derive this value analytically.
Until next time.

Excellent breakdown of eigenvalues and eigenvectors, especially the connection to Fibonacci numbers! If anyone’s interested in more examples and detailed explanations, this article might be a great complement. Thanks for sharing!
LikeLike